이전에 filter와 interceptor의 차이를 보았는데, 오늘은 filter와 oncePerRequestFilter의 차이를 보려고 한다. 그런데 이게 필턴데 스프링 컨텍스트 안에서 작용한다고? 그럼 또 interceptor를 놓칠 수 없다..
OncePerRequestFilter
OncePerRequestFilter는 Spring Framework에서 제공하는 필터로, Spring의 서블릿 컨테이너에서 동작한다. 이는 Spring의 일반적인 필터 체인에서 동작하는데, Spring이 제공하는 기능이기 때문에 Spring 이외의 서블릿 컨테이너에서는 자동으로 동작하지 않는다. 또한 extend로 필터를 구현하며 @Component로 등록되어 있어야 한다.
A Filter can be called either before or after servlet execution. When a request is dispatched to a servlet, the RequestDispatcher may forward it to another servlet. There's a possibility that the other servlet also has the same filter. In such scenarios, the same filter gets invoked multiple times.
Spring guarantees that the OncePerRequestFilter is executed only once for a given request.
spring은 filter에서 spring config 설정 정보를 쉽게 처리하기 위한 GenericFilterBean을 제공한다.
사용자는 요청을 한 번 보냈지만 redirect나 내부적인 이슈로 한 요청이 여러 번의 요청을 낳게 될 수 있다. 이 경우 인증, 로깅 등 필터가 (의도치 않게) 중첩적으로 호출되는데 이를 방지하고 하는 필터가 OncePerRequestFilter이다. OncePerRequestFilter 역시 GenericFilterBean상속받아 구현되어 있다. 즉 스프링이 제어한다는 것이고, 스프링은 OncePerRequestFilter가 주어진 요청에 대해 단 한 번만 수행되는 것을 보장한다.
OncePerRequestFilter는 다음과 같이 동작합니다:
서블릿 컨테이너에서 Spring 필터 체인이 실행될 때, OncePerRequestFilter는 요청을 가로채서 처리
필터 체인을 통해 요청을 전달할 수 있으며, 필터 체인 내에서 다른 필터들이 중복 실행되지 않도록 보장
필터 체인에서 중복 실행 방지가 필요한 경우에 사용. 일반적인 javax.servlet.Filter는 요청이 FORWARD 또는 INCLUDE로 서블릿 내부에서 재처리될 때 여러 번 호출될 수 있지만, OncePerRequestFilter는 각 요청당 한 번만 실행됩니다.
실제 동작 흐름:
아무 설정을 하지 않아도 Spring Boot는 Spring 필터(Specifically, Spring Security 등)를 서블릿 컨테이너 필터보다 먼저 실행되도록 자동으로 설정합니다. 이는 Spring Boot의 자동 구성(Autoconfiguration) 기능과 내부 필터 체인 관리방식 덕분입니다. Spring Boot는 애플리케이션 시작 시 자동으로 Spring 필터들을 서블릿 컨테이너에서 관리되는 필터보다 우선적으로 실행되도록 설정합니다.
서블릿 컨테이너가 요청을 받습니다.
Spring Boot는 Spring 필터 체인을 먼저 실행하도록 설정합니다.
Spring에서 관리하는 필터(예: OncePerRequestFilter)가 먼저 실행됩니다.
그 후, 서블릿 컨테이너에 등록된 일반 필터(javax.servlet.Filter)가 실행됩니다.
2024-10-08 15:35:41 INFO [c.n.a.f.CustomServletWrappingFilter .doFilterInternal : 24] [once-filter][REQUEST] [GET] /api/asdf
2024-10-08 15:35:41 INFO [c.n.aapoker.filter.RequestLogFilter .doFilter : 34] [filter][REQUEST] [GET] /api/asdf
2024-10-08 15:35:41 INFO [c.n.aapoker.filter.RequestInterceptor .preHandle : 21] [interceptor][REQUEST] [GET] /api/asdf
2024-10-08 15:35:41 INFO [c.n.aapoker.filter.RequestInterceptor .postHandle : 39] [interceptor][RESPONSE] [GET] /api/asdf 404 - 0.003 ms
2024-10-08 15:35:41 INFO [c.n.aapoker.filter.RequestLogFilter .doFilter : 43] [filter][RESPONSE] [GET] /api/asdf 404 - 0.01ms
2024-10-08 15:35:41 INFO [c.n.a.f.CustomServletWrappingFilter .doFilterInternal : 32] [once-filter][RESPONSE] [GET] /api/asdf 404 - 0.011ms
2024-10-08 15:35:41 INFO [c.n.aapoker.filter.RequestInterceptor .preHandle : 21] [interceptor][REQUEST] [GET] /error
2024-10-08 15:35:41 INFO [c.n.aapoker.filter.RequestInterceptor .postHandle : 39] [interceptor][RESPONSE] [GET] /error 404 - 0.013 ms
에러 화면을 요청할 경우 필터와 onceRequestFilter는 한번씩만 실행되고, 인터셉터는 스프링 진영에서 자동으로 route되는 error화면까지 잡힌다.
onceRequestFilter도 스프링에서 관리되는 필터지만 error를 잡지 않는다는 것을 확인!
참고) ContentCachingRequestWrapper
ContentCachingRequestWrapper는 요청(Request) 본문을 캐싱할 수 있도록 도와주는 래퍼 클래스입니다. 기본적으로, 서블릿 요청의 본문은 한 번만 읽을 수 있는 스트림 형태로 제공됩니다. 하지만 특정 상황에서는 요청 본문을 여러 번 읽어야 하거나, 로깅 또는 분석 목적으로 요청 본문을 캐싱하고자 할 때가 있습니다.
api 두 개를 순차적으로 요청할 때, 첫 번째 api 결과로 얻은 list안의 어떤 값을 두 번째 api의 요청 값에 넣어 순차적으로 테스트하는 방법을 알아본다. 이전 글에서 다룬 chaining test랑도 비슷하지만, chaining test에서는 object안의 한 항목을 variable로 set 해서 전달했다면, 여기서는 마치 for loop을 도는 것처럼 list안의 항목을 하나씩 돌아 테스트한다.
이전에 다룬 bulk test와도 비슷하지만 별도의 csv파일을 활용하지 않고 진행하는 것에 차이가 있다.
여기서 status = '01' 이면 active, '01'이 아니면 inactive이다. 원하는 것은 active 한 object의 playerId를 꺼내서 다음 api의 request항목(여기서는 path param)에 넣어 순차적으로 요청하는 것이라면, 테스트 코드를 어떻게 작성해야 할까.
const playerIds = pm.collectionVariables.get("playerIds");
pm.test("Status code is 200", function () {
pm.response.to.have.status(200); //6. 현재 요청이 성공인지 우선 확인
});
if(playerIds && playerIds.length > 0){ //collection-var의 array에 데이터가 있는지 확인하고, 있으면
postman.setNextRequest("get affiliate by asp"); //7. 자기자신을 다시 실행
}else{
postman.setNextRequest(null); //7. 없으면 끝
}
이렇게 두고 테스트하니 아래처럼 첫 번째 api는 1번 두 번째 api는 playerIds array의 크기(여기서는 29)만큼의 루프를 모두 돌아 정상 실행됨을 확인할 수 있었다.
reactive programming과 관련하여 토비의 라이브 10강을 시청하고 요약정리하려고 한다.
1. Iterable vs Observable (duality)
Iterable(pull) 방식: 사용하고자 하는 사람이 가져다가 쓴다.
Iterable#next
public static void main(String[] args){
Iterable<Integer> iter = () ->
new Iterator<>() {
int i = 0;
final static int MAX = 10;
public boolean hasNext() {
return i < MAX;
}
public Integer next() {
return ++i;
}
};
for(Integer i : iter){ //for each
System.out.println(i);
}
for(Iterator<Integer> it = iter.iterator(); it.hasNext();){
System.out.println(it.next()); //pull 데이터를 꺼내자
}
}
Observable(push) 방식: 데이터를 주면 그걸 받아서 처리하는 방법
Observable#notifyObservers
@SuppressWarnings("deprecation")
static class IntObservable extends Observable implements Runnable{
@Override
public void run() {
for(int i=1; i<=10; i++){
setChanged(); //데이터 바뀌었으니 가져가라고 설정
notifyObservers(i); //push방식으로 옵저버에게 데이터를 주면
}
}
}
public static void main(String[] args){
Observer ob = new Observer() {
@Override
public void update(Observable o, Object arg) {
//받아
System.out.println(Thread.currentThread().getName() + " " + arg);
}
};
IntObservable io = new IntObservable();
io.addObserver(ob); //리스너 등록
//io.run(); //실행
//옵저버 패턴은 별도의 스레드에서 작업하기 수월
ExecutorService es = Executors.newSingleThreadExecutor(); //따로 할당받은 스레드에서
es.execute(io); //run이 실행됨
System.out.println(Thread.currentThread().getName() + " DONE"); //메인 스레드에서 실행
es.shutdown(); //스레드 종료
}
추가) 위 내용에 대해 이해하기 위해서는 옵저버 패턴(Observer pattern)을 필수로 알아야 한다.
옵저버 패턴? 객체의 상태 변화를 관찰하는 관찰자들, 즉 옵저버들의 목록을 객체에 등록하여 상태 변화가 있을 때마다 메서드 등을 통해 객체가 직접 목록의 각 옵저버에게 통지하도록 하는 디자인 패턴이다. 한 객체의 상태가 바뀌면 그 객체에 의존하는 다른 객체들한테 연락이 가고, 자동으로 내용이 갱신되는 방식으로 일대다(one-to-many) 의존성을 정의한다.
위 내용에 맞게 스스로 관련 내용을 구현할 수 있지만 자바에서 제공하는Observer 인터페이스와 Observable 클래스를 가지고 구현할 수도 있다.
Observable 클래스를 상속받은 게 "데이터 제공자" Observer 인터페이스를 구현한 게 "데이터 받는 자"이다.
참고로 Observable클래스는 Java9부터 deprecated라서 관련 경고를 없애기 위해 아래 어노테이션을 넣는다.
@SuppressWarnings("deprecation")
옵저버 패턴에서는 다음과 같은 이슈가 있다.
complete? 마지막이 언제인지 알기 힘들다.
error? 진행되다 익셉션이 나면? 전파되는 방식이나 에러는 어떻게 처리? fallback? 관련 아이디어가 패턴에 녹아져 있지 않다.
이에 나오게 된 사상이 reactive stream이다.
2. reactive stream(스펙)
reactive stream이란 non-blocking(논 블럭킹) backPressure(역압)을 이용하여 비동기 서비스를 할 때 기본이 되는 스펙으로 아래와 같은 특징이 있다.
잠재적으로 무한한 양의 데이터 처리
순서대로 처리
데이터를 비동기적으로 전달
backpressure를 이용한 데이터 흐름 제어
또한 4가지 컴포넌트로 구성되어 있는데 다음과 같다.
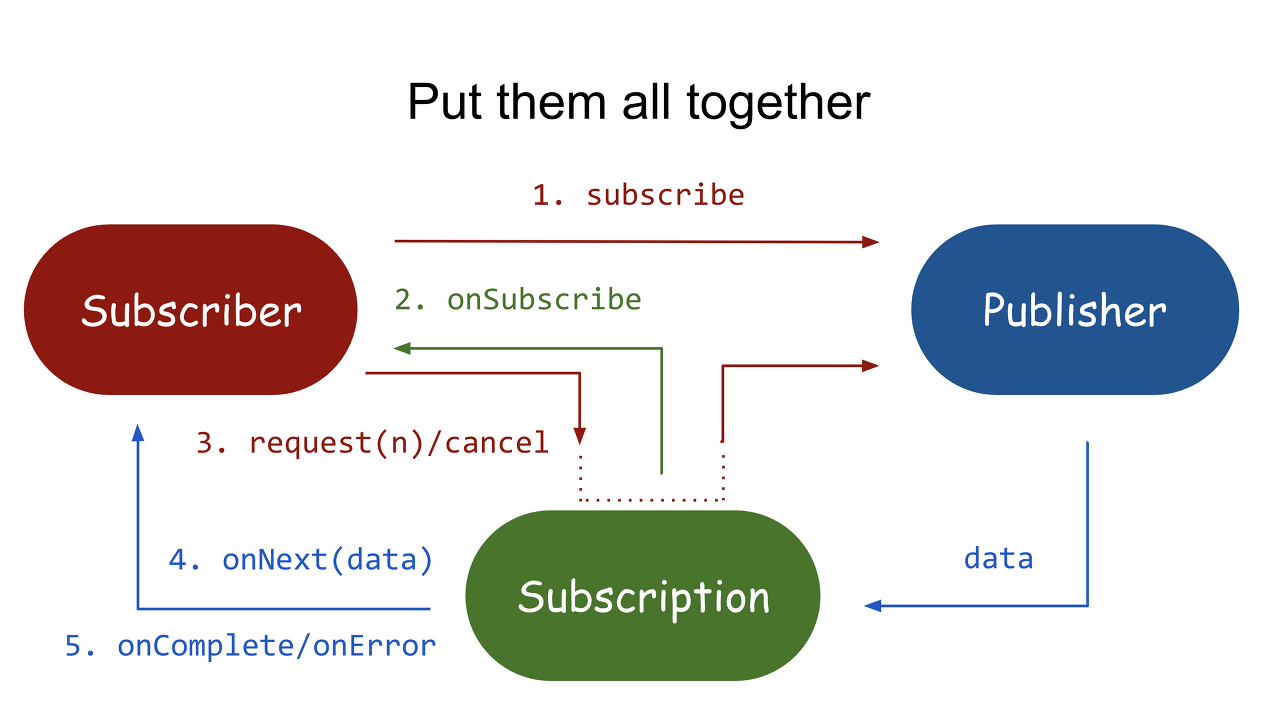
publisher: 데이터 제공자(옵저버 패턴의observable)
Publisher.subscribe(Subscriber)
subscriber: 데이터를 받아서 사용하는 쪽(옵저버 패턴의 observer)
onSubscribe, onNext ...
subscription
proessor
참고로 Java9에 추가된 Flow는 reactvie stream 스펙을 채택하여 사용하고 있다. reative stream 스펙에 대한 내용은 여기에서 확인하기로 하고 이제 소스를 살펴보자.
public static void main(String[] args) throws InterruptedException {
Iterable<Integer> itr = Arrays.asList(1, 2, 3, 4, 5);
ExecutorService es = Executors.newSingleThreadExecutor();
Flow.Publisher p = new Flow.Publisher() {
@Override
public void subscribe(Flow.Subscriber subscriber) {
Iterator<Integer> it = itr.iterator();
subscriber.onSubscribe(new Flow.Subscription() {
@Override
public void request(long n) { //몇 개줄까; 갯수만큼 받고 싶어
es.execute(() -> {
//스레스 한정 위반이라 n을 안에서 수정 못해, i를 별도로 설정
int i = 0;
try{
while(i++ < n){
if(it.hasNext()){
subscriber.onNext(it.next());
}else {
subscriber.onComplete();
break;
}
}
}catch (RuntimeException e){
subscriber.onError(e);
}
});
}
@Override
public void cancel() { //중간에 작업 취소 시킬 수 있음
}
});
}
};
Flow.Subscriber<Integer> s = new Flow.Subscriber<Integer>() {
Flow.Subscription subscription; //잠시 저장하자
@Override
public void onSubscribe(Flow.Subscription subscription) { //구독이 시작되었어
System.out.println(Thread.currentThread().getName() + " > onSubscribe ");
//request
this.subscription = subscription;
this.subscription.request(1); //Long.MAX = 다 내놔
}
@Override
public void onNext(Integer item) { //update; 데이터 주면 받아서 처리해; 끌어와 데이터를
System.out.println(Thread.currentThread().getName() + " > onNext " + item); //받을 준비 되었어
//버퍼사이즈, cpu 등에 따라 별도로 조절가능
this.subscription.request(1);//하나 줘
}
@Override
public void onError(Throwable throwable) { //에러가 나면 에러를 나 줘; 재시도 등 처리가능; 구독 끝
System.out.println(Thread.currentThread().getName() + " > onError " + throwable.getMessage());
}
@Override
public void onComplete() { //다 완료되었어; 구독 끝
System.out.println(Thread.currentThread().getName() + " > onComplete ");
}
};
p.subscribe(s); //s가 p를 리슨
// es.shutdown();
es.awaitTermination(10, TimeUnit.SECONDS);
es.shutdown();
}
소스 각 라인에 주석으로 설명을 달았으며 큰 흐름은 아래 그림을 보고 이해하면 된다.
reactive stream from line
여기서의 특징은 publisher와 subscriber 사이에 subscription이라는 데이터이자 중계자를 거쳐서 구독과 관련된 설정을 할 수 있다는 점이다.
request로 사용할 데이터가 든 파일을 준비한다. csv 확장자로 저장된 파일이어야 하며, 최상단에는 지칭하는 이름이 들어있어야 한다(노트패드나 엑셀에서 csv파일을 만들 수 있다).
포스트맨에서 collection -> runner 클릭하고 콜랙션의 api를 옆으로 드래그한다. 필요시 순서를 맞추고, 테스트할 api를 선택한다.
오른쪽 영역에서 위 csv파일을 데이터 부분에서 csv 파일을 불러온다.
preview를 눌렀을 때 아래와 같이 팝업이 뜨면 정상적으로 읽힌 것이다.
자 이제 파일을 준비했으니, 저 변수를 가져올 부분을 세팅해보자. 나는 저 변수를 POST 요청의 항목으로 사용할 예정이라 아래와 같이 수정해주었다.
가. pre-request script에서 파일에서 읽어 온 값을 변수 처리한다. 어떤 변수로 세팅해야 할지는 상황에 따라 다르겠다. 이전 글을 보면 변수의 범위에 대해 언급한 적이 있는데, 동일하게 생각해서 설정하면 된다.
var cardNo = pm.iterationData.get("card") //csv파일의 각 줄의 card부분을 가져와 변수 세팅
var zipcode = pm.iterationData.get("zipcode") //csv파일의 각 줄의 zipcode부분을 가져와 변수 세팅
console.log(cardNo) //로그
pm.collectionVariables.set("card", cardNo); //위 cardNo를 콜랙션 변수로 세팅
pm.collectionVariables.set("zipcode", zipcode); //위 zipcode를 콜랙션 변수로 세팅
나. body 부분을 수정한다. 변수가 들어갈 부분을 수정해준다.
다. 잘 들어갔는지 확인. 테스트 코드로 확인한다.
pm.test("request 변수 확인", function () {
var req = JSON.parse(pm.request.body.raw); //request body를 가져와서
console.log(req) //로그찍고
console.log(req[0].card) //string "9460777788890000"
console.log(pm.iterationData.get("card"))//number 9460777788890000
//parseInt(req[0].card)로 number로 바꿔서 비교해야 같게 나옴
pm.expect(parseInt(req[0].card)).to.eql(pm.iterationData.get("card"));
pm.expect(parseInt(req[0].address.zipcode)).to.eql(pm.iterationData.get("zipcode"));
});
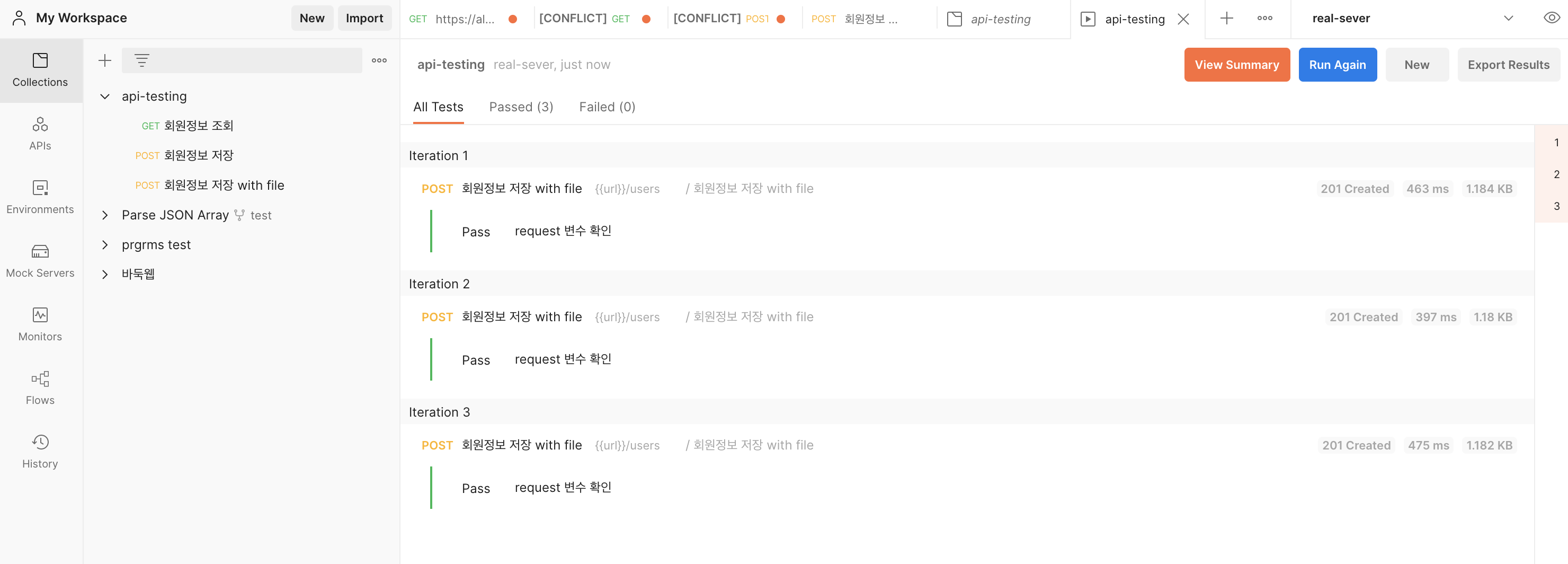
라. 위 가~다 과정을 하고 나서 꼭 ctrl+s 를 눌러서 저장을 해주고, 다시 collection의 runner로 돌아와서 Run api-testing을 클릭한다.
테스트가 성공하는 것을 볼 수 있다. 만약 실패해도 뭐가 틀렸는지 알려주기 때문에 바로 수정하면 된다.
참고로 각 요청을 클릭하면 실제로 어떤 json이 요청 나가고 들어왔는지 볼 수 있다.
참고
1. csv파일의 특성 상 숫자 형의 맨 처음 오는 0은 잘리니까 조심해야 한다(사진에서도 파일에는 0이 있지만 포스트맨에서 불러왔을 때에는 0이 없어지는 것이 확인된다). 해결법이 있을 법도 한데,, 아직 없는 것 같다. csv파일을 json포맷으로 바꿔서 했다는 글만 있다.
2. 그리고 csv 안의 숫자의 길이가 16자리 이상이면 포스트맨이 값을 알아서 변환해버리는 이슈가 있다. 변수를 불러올 때 자바스크립트의 Number를 사용해서 생기는 이슈라고는 하는데 어쨌든 request와 다른 값으로 쏘는 것은 명백한 이슈기 때문에 숫자를 문자로 바꿔서 요청할 수 있게끔 지원해달라는 문의글이 최신으로도 올라오고 있다. 이를 방지하려면 아래와 같이 csv안의 숫자 앞뒤로 "(큰따옴표)를 넣어주면 되긴 하지만.. 데이터가 많을수록 귀찮아질 것이기에.. 아래의 json변환 방법을 사용하려 쏘는 게 더 나을 것 같다.
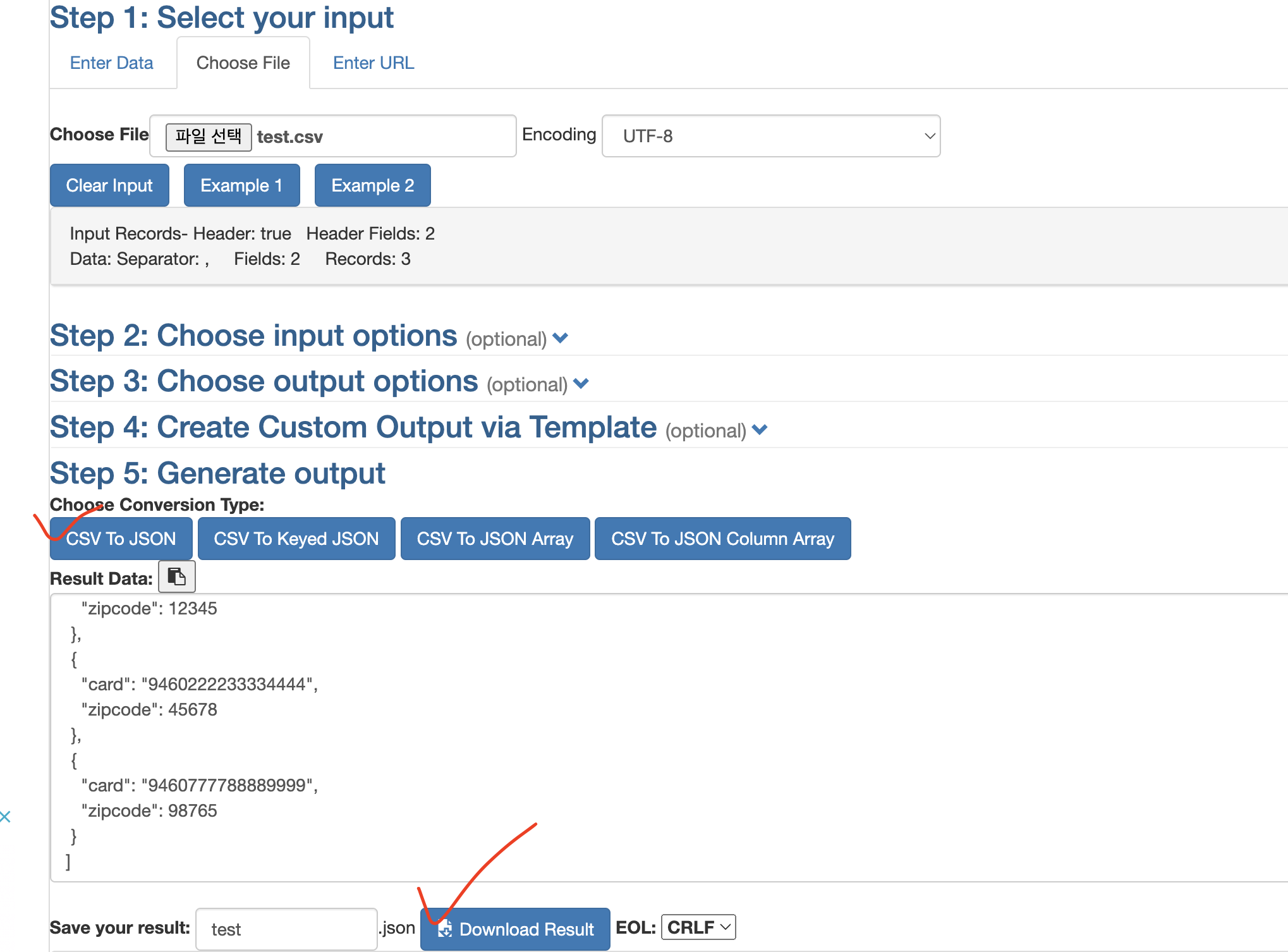
위 사이트에서 미리 준비된 csv를 선택하면 아래에 결과를 볼 수 있다. 여러 포맷으로 변환해주는데 포스트맨에서는 맨 처음 양식을 지원하기 때문에 csv to json으로 변환해주고 download를 눌러주면. json파일이 받아진다.
만들어진 파일을 열어본다(위 사진의 result data에서도 확인가능하다).
자동으로 타입을 판별해서 그런지 zipcode가 숫자 타입으로 json이 만들어졌는데, 이를 문자열로 바꿔서 다시 만들도록 한다(api request에서 문자로 보내야 하는지 숫자로 보내야 하는지에 따라 다르게 설정하면 된다).
사이트 output 옵션 중에 강제로 stringify하는 곳이 있는데, 비워두면 전체를 문자열화, 위치를 콤마로 구분해서 넣어주면 그 곳만 문자열화 해준다. 우리는 두번째에 위치한 zipcode를 문자열화 해야 하니 2를 넣어주고 다시 csv to json을 눌러준다. 아래에 문자열로 바뀐 json을 확인한다.
포스트맨에서 json파일을 불러오고 preview버튼을 누르면 아까 csv에서는 사라졌던 0이 잘 들어와 있는 것을 볼 수 있다.
csv로 테스트했을 때는 다 숫자로 읽어와서 테스트 코드도 숫자로 변환하는 부분이 있었는데, json에서는 이를 유동적으로 바꿀 수 있어서 더 좋은 것 같다. 우리는 지금 모든 값을 문자화 했으니 테스트 코드도 문자 비교로 바꿔야 통과한다.
pm.test("request 변수 확인", function () {
var req = JSON.parse(pm.request.body.raw);
console.log(req)
pm.expect(req[0].card).to.eql(pm.iterationData.get("card"));
pm.expect(req[0].address.zipcode).to.eql(pm.iterationData.get("zipcode"));
});
마치며..
csv는 숫자 값이면 (숫자가 아니어도 숫자 꼴이기만 하면; ex. 카드번호, 폰번호) 숫자로 인식해서 예상하지 못한 문제가 생길 수 있는데, json으로 변환하면 이를 조절할 수 있으니 json으로 테스트하는 게 더 정확하고 예측 가능한 것 같다!
마이크로 서비스 아키텍처(MSA) 프로젝트를 개발 및 운영을 하다 보면 도메인 모델은 복잡해지고 점점 설계 시점의 의도와는 다른 방향으로 변질되는 일이 빈번히 발생한다. 특히 요즘처럼 고차원적인 UX, 급변하는 IT 시장의 흐름으로 인해 시도 때도 없이 달라지는 기획팀/사업부의 요구사항을 충족하는 모델을 만드는 건 더욱 어려운 일이 되었다. 게다가 이렇게 복잡한 내용을 하나의 화면에서 다 보여달라고 하니.. 아무리 인덱스를 추가하고 쿼리를 튜닝하더라도 조회 속도가 나지 않고, n번의 api를 결과를 합치면서 생기는 실수, 더러운 소스코드 등은 결국 서비스의 질을 낮추기에 충분해진다.
(내가 경험한) MSA
이게 왜 어려워졌을까? 데이터의 변경과 조회 시 필요한 데이터가 관점에 따라 명백히 다른데, 이걸 하나의 모델/애플리케이션/디비에서 해결하려다 보니 (각 영역에서 필요하지 않은 속성들로 인해) 복잡도가 증가하고 변질되는 것은 아닐까?
그럼 어떻게 이 문제를 해결 할 수 있을까? 데이터의 변경과 조회를 나누면 되지 않을까? 해서 나온 게 CQRS이다.
CQRS란?
마이크로 서비스의 패턴이 무려 44가지나 있다고 하는데, 간단하게 관련 용어 몇 가지만 살펴본다.
DDD - Domain Driven Design 도메인 주도 개발(방법론)
비즈니스를 도메인 별로 나누어 설계하는 방식/접근법
EDA - Event Driven Architecture
분산된 시스템 간에 이벤트를 생성, 발행(publishing)하고 발행된 이벤트를 필요로 하는 수신자(subscriber)에게 전송되는 흐름으로 구성된 아키텍처로 이벤트를 수신한 수신자가 이벤트를 처리하는 형태임
Event-Sourced Aggregate: EventStore로부터 Event를 재생하면서 모델을 최신 상태로
State-Stored Aggregate: EventStore에 Event를 적재와 별개로 모델 자체에 최신 상태를 DB에 저장
Query Application
Point to Point Query: 하나의 QueryHandler를 찾아 진행
Scatter-Gather Query: 동일한 Query를 처리하는 Handler가 여러 App에 등록되어있을 때, 이를 처리하는 방법
Subscription Query: Point to Point Query를 요청하였을 때, 만약 Query를 수행하는 Read Model이 바뀌었다면, 화면에 출력되는 결과와 Read Model 사이 데이터 정합성 불일치 문제가 발생한다. 따라서 이를 해결하기 위해 주기적으로 Query를 재요청하는 방식
추가) Saga pattern in axon
axon framework에서도 분산 트랜젝션을 위해 saga 패턴을 지원한다(saga event 정보를 db에 저장).