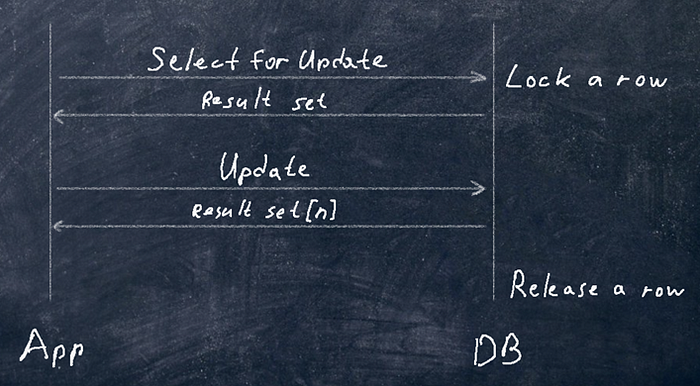
락이 실행할 때 transaction이 없으면 에러 발생(transactionRequiredException)
락을 바로 얻을 수 없으면 LockTImeoutException 던짐
timeout 설정 필요: 락을 잡고 있는 최대 시간
QueryHint 이용; javax.persistence.lock.timeout; 단위 ms
모든 DBMS가 지원하는 건 아님
If the time it takes to obtain a lock exceeds the value of this property, aLockTimeoutExceptionwill be thrown, but the current transaction will not be marked for rollback.
@Lock(LockModeType.PESSIMISTIC_READ)
@QueryHints({@QueryHint(name = "jakarta.persistence.lock.timeout", value = "3000")})
public Optional<Customer> findById(Long customerId);
A transaction is a group of sequential operations on a database that forms a logical unit of working with data.
Transactions are used to maintain the consistency and integrity of data in a database.
It’s important to know that transactions are thread-local, so they apply to the current thread only.
propagation: 세션의 트랜젝션을 어떻게 이용할지; 무결성과 정합성을 유지하기 위한 방법
종류
트랜젝션 존재 시
트랜젝션 미존재 시
비고
REQUIRED
기존 트랜잭션 이용
신규 트랜잭션 생성
기본값
SUPPORTS
기존 트랜잭션 이용
트랜잭션 없이 수행
MANDATORY
기존 트랜잭션 이용
exception 발생
꼭 이전 트랜잭션이 있어야 하는 경우
NEVER
exception 발생
정상적으로 트랜잭션 없이 수행
트랜잭션 없을 때만 작업이 진행되어야할 때
NOT_SUPPORTED
기존 트랜젝션은 중지하고 대기, 트랜젝션 없이 실행하다가 끝나면 기존 트랜젝션 실행
트랜잭션 없이 로직 수행
기존 트랜잭션에 영향을 주지 않아야할 때
REQUIRES_NEW
현재 트랜잭션은 중지되고 대기. 새로운 트랜잭션을 생성하고 종료되면 현재 트랜젝션이 다시 진행
신규 트랜잭션을 생성하고 로직을 실행
이전 트랜잭션과 구분하여 새로운 트랜잭션으로 처리가 필요할 때; 락과 함께 사용할 경우 데드락 조심
NESTED
현재 트랜잭션에 Save Point를 걸고 이후 트랜잭션을 수행
REQUIRED와 동일하게 작동 (신규 트랜잭션을 생성하고 로직이 수행)
DBMS특성에 따라 지원 혹은 미지원; jpa에서 사용 불가
Nested is not possible in the JPA dialect because you cannot create a save point here. Nested, unlike Required New, creates a kind of save point. For example, if you are updating a huge batch of data, you won’t have to roll back everything in case of an error; you may roll back just to the save point.
두 함수간 트랜젝션을 전파하는 경우(출처: chat gpt..)
부모 함수 -> 자식 함수라고 가정할 때
트랜잭션 전파의 핵심은 부모 메서드에서 트랜잭션이 이미 시작되었는지 여부입니다. parentMethod()에서 트랜잭션이 시작되었다면, 그 안에서 호출되는 모든 자식 메서드(접근 제어자 public이든 private이든 상관없이)는 동일한 트랜잭션 경계 내에서 실행됩니다.
부모
자식
부모 transaction 전파 여부
public + @Transactional
private in same class
O
public + @Transactional
public in same class, @Transactional유무 상관없이
O
public + @Transactional
public in different class, @Transactional유무 상관없이
O
1. Transaction은 public에서 시작, private은 함수의 일부라 판단하여 트랜젝션 이어짐
@Service
public class MyService {
@Transactional
public void parentMethod() {
// Transaction starts here
privateChildMethod(); // This method is part of the same transaction
}
private void privateChildMethod() {
// This method participates in the transaction started by parentMethod
}
}
2. 자식 함수가 같은 클래스에 있으면 부모 트랜젝션 전파됨
만약 반대로 부모가 @TRANSACTIONAL이 없고 같은 클래스의 자식에게 @TRANSACTIONAL이 있다면 자식의 트랜젝션은 신규로 생성되지 않음(프록시를 타지 않아서)
@Service
public class MyService {
@Transactional
public void parentMethod() {
// Transaction starts here
publicChildMethod(); // This call bypasses the proxy
}
public void publicChildMethod() {
// This method does not participate in the transaction started by parentMethod
}
}
3. 부모와 자식 클래스가 다를 경우, 자식이 기본 Transaction을 사용할 경우
클래스가 다를 경우 자식 함수가 proxy의 영향을 받기 때문에 부모의 트랜젝션이 자식에게 전파된다.
자식 함수가 @Transaction 어노테이션이 있건 없건 전파되는데, 만약 자식 함수도 Transaction 어노테이션이 있고 별다른 propagation 설정이 없다면 기본 전파 옵션이 Propagation.REQUIRED 이기 때문에 기존 트랜젝션을 탄다. 이 경우가 transaction 중첩이 가능한 부분이고, 위 옵션에 따라 달라진다.
@Service
public class ParentService {
@Autowired
private ChildService childService;
@Transactional
public void parentMethod() {
// Transaction starts here
childService.childMethod(); // This call goes through the proxy
}
}
@Service
public class ChildService {
@Transactional //있건없건 트랜젝션 영향 받음
public void childMethod() {
// This method participates in the transaction started by parentMethod
// because the call goes through the Spring proxy
}
}
Isolation Level은 동시 트랜잭션이 수행될때 다른 트랜잭션이 동일한 데이터에 대해서 어떻게 보일지에 대한 범위를 나타낸다.
Isolation is the third letter in the ACID acronym. It means that concurrent transactions should not impact each other.
위에서 DB단에서의 isolation level에 대해 살펴보았다. 이제 application 단에서의 isolation 설정을 알아보자.
isolation level을 아래와 같이 트랙잭션 별로 설정할 수 있다.
import org.springframework.transaction.annotation.Isolation;
import org.springframework.transaction.annotation.Transactional;
@Transactional(isolation = Isolation.READ_UNCOMMITTED)
public void readUncommittedTransaction() {
// Your code here
}
@Transactional(isolation = Isolation.READ_COMMITTED)
public void readCommittedTransaction() {
// Your code here
}
@Transactional(isolation = Isolation.REPEATABLE_READ)
public void repeatableReadTransaction() {
// Your code here
}
@Transactional(isolation = Isolation.SERIALIZABLE)
public void serializableTransaction() {
// Your code here
}
Isolation.DEFAULT: 디비의 default 설정에 따름
Isolation.READ_UNCOMMITTED
Isolation.READ_COMMITTED: 처음 업데이트 값으로 오버라이드 위험
Isolation.REPEATABLE_READ: 오버라이드 할 것 같으면 에러 발생
에러 발생하면 재시도할 수 있음
@Retryable(maxAttempts = 15) // This is actually quite a lot. Ideally, 1–3 attempts should be sufficient.
스래드 200개 생성됨..(과다하게 생성됨; 동시성 이슈)
즉각 재시도(디비저장) 보다 다시 큐를 쌓도록하는게 동시성을 낮출 수
Isolation.SERIALIZABLE
동시에 저장하려고하면 디비에서 에러발생
그래도 100프로 보장 못함; 실패나면 롤백되는게 있음
주의사항
데이터 정합성(data integrity)과 성능(performance)을 고려하여 설정해야 한다.
oracle에는 merge into 가 있어 값이 있을때는 수정하고 없을때는 추가하여 pk 없음 에러 혹은 중복키 저장 에러가 나지 않고 작업을 진행할 수 있었는데, mysql에는 같은 기능을 하는 쿼리가 있는지 알아본다.
oracle
MERGE INTO [UPDATE되거나 INSERT 될 테이블]
USING [MERGE를 진행하고 싶은 대상, 조인, 서브쿼리도 사용 가능]
ON [조건]
WHEN MATCHED THEN [조건에 맞는 데이터가 있을 시 실행할 구문, UPDATE, DELETE]
WHEN NOT MATCHED THEN [조건에 맞는 데이터가 없을 시 실행할 구문, INSERT]
;
mysql
INSERT INTO 테이블 (
[콜롬들...]
)VALUES(
[값들...]
)
ON DUPLICATE KEY UPDATE
[PK값들..]
예시
category 테이블 pk가 service_code, category_code 인 경우, category_name을 추가하거나 수정하려고 한다면..
CREATE TABLE `category` (
`service_code` varchar(20) NOT NULL COMMENT '서비스 코드',
`category_code` varchar(20) NOT NULL COMMENT '카테고리 코드',
`category_name` varchar(20) NOT NULL COMMENT '카테고리 명',
PRIMARY KEY (`service_code`,`category_code`)
기존 row가 있을 경우 결과가 2로 떨어지고 데이터도 수정된 것을 확인할 수 있다. 없을 경우 1로 떨어지고 추가된다.
왜?!???
With ON DUPLICATE KEY UPDATE, the affected-rows value per row is 1 if the row is inserted as a new row, 2 if an existing row is updated, and 0 if an existing row is set to its current values. If you specify the CLIENT_FOUND_ROWS flag to the mysql_real_connect() C API function when connecting to mysqld, the affected-rows value is 1 (not 0) if an existing row is set to its current values.