# springboot2.2 버전 이상이면
server.tomcat.remoteip.remote-ip-header=X-FORWARDED-FOR
# 구버전
#server.tomcat.remote-ip-header=X-FORWARDED-FOR
경우에 따라서는 아래 값도 조정해야할 수 있다.
server.tomcat.remoteip.internal-proxies
이 값은 신뢰할 내부 프록시를 매칭하는 값이다. 정규식으로 작성해야하며 기본값은 아래와 같다. 일반적으로는 기본값으로도 사용가능하지만 프로덕션 환경에서 내부 프록시 ip들이 해당 범위를 넘어갈 수도 있으니 확인이 필요하다. 참고로 공백으로 설정하면 모든 프록시를 신뢰한다는 뜻으로 프로덕션 환경에서는 이렇게 설정하면 위험할 수 있으니 주의해야 한다.
EDA는 시스템 내의 이벤트를 통해 컴포넌트나 서비스 간의 통신을 관리하는 아키텍처입니다. 어떤 상태 변화나 동작이 발생하면 이벤트가 생성되고, 이를 기반으로 다른 컴포넌트들이 반응합니다.
EDA는 이벤트를 통해 시스템 간 통신과 상호작용을 관리하는 데 초점을 맞추며, 컴포넌트 간의 느슨한 결합과 비동기 처리를 가능하게 합니다.
특징:
비동기 통신: 이벤트는 비동기적으로 발행되고, 이를 처리하는 소비자들이 독립적으로 이벤트를 처리합니다. 이는 시스템의 느슨한 결합을 가능하게 합니다.
루스 커플링: 이벤트 발행자와 소비자는 서로 직접적으로 알 필요가 없습니다. 이는 시스템 간의 의존성을 줄이고 유연한 확장성을 제공합니다.
확장성: 새로운 이벤트 소비자를 쉽게 추가할 수 있고, 시스템의 각 구성 요소가 독립적으로 확장 가능합니다.
리액티브 시스템: EDA는 시스템의 비동기적 반응성을 높여 실시간으로 변화에 대응할 수 있게 합니다.
EDA: 시스템 간의 비동기적 상호작용을 통해 최종 일관성(Eventual Consistency)을 유지할 수 있습니다. 메시지 손실이나 중복 처리 등은 메시징 시스템의 특성에 따라 다르게 처리될 수 있습니다.
monolithic
단일 데이터베이스
트랜잭션 처리를 완벽하게 -> ACID
atomicity
consistency
isloation
durable
msa
각 서비스마다 독립적인 데이터베이스(polyglot)
API를 통해 접근
atomicy, consistency를 완벽하게 지키기 힘듦 -> commit transaction 사용
작업 단위가 정상적으로 끝났음을 알려줌
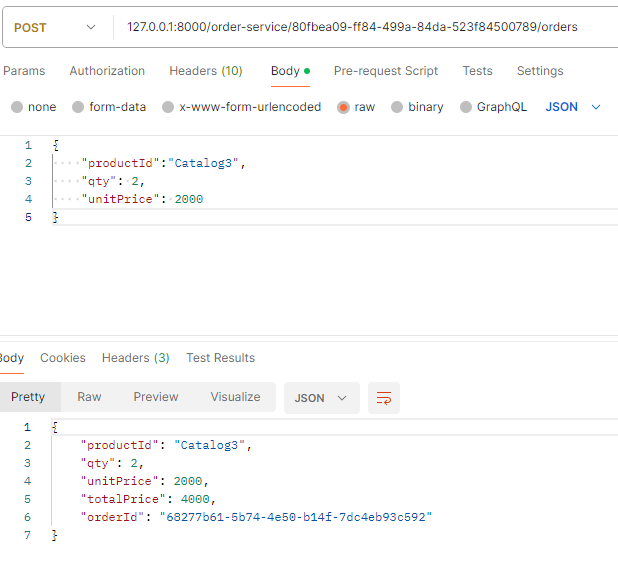
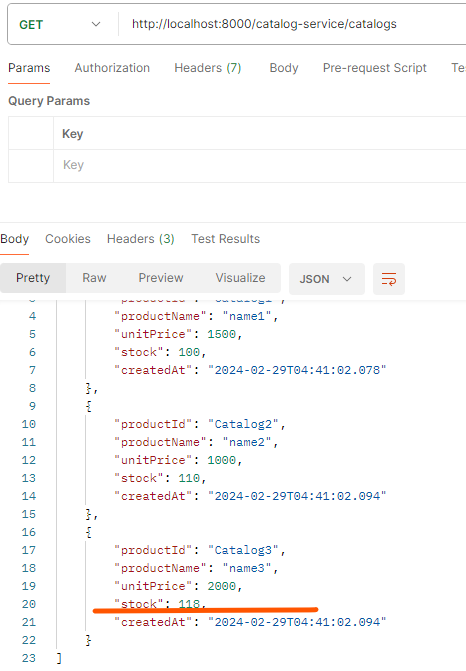
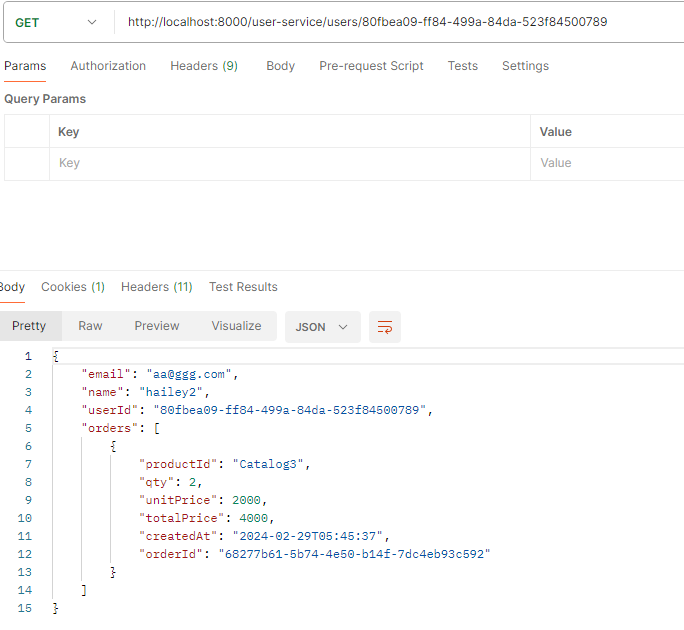
A 서비스: 최초에 대기상태로 저장 후 요청(카프카) -> B서비스: 수량 등을 확인하고 재고처리 후 confirm 메세지 발행(카프카; 메세지 종류는 상태에 따라 다르게 발생) -> A서비스: confirm message를 받아서 상태값을 변경
롤백이나 취소 상태로 변경 용이
event sourcing
정의:
Event Sourcing은 시스템의 상태를 데이터베이스에 직접 저장하지 않고, 상태 변화를 나타내는 모든 이벤트를 저장하고, 이 이벤트들을 순차적으로 재생(Replay)하여 현재 상태를 복원하는 아키텍처 패턴입니다.
Event Sourcing은 시스템의 상태 변화를 이벤트로 기록하여 현재 상태를 유지하고, 데이터의 변경 이력을 완벽하게 보존하는 데 중점을 둡니다.
특징:
이벤트 저장: 애플리케이션의 모든 상태 변화는 이벤트로 표현되어 이벤트 스토어에 기록됩니다. 예를 들어, "계좌 개설", "잔고 추가", "잔고 인출"과 같은 이벤트들이 저장됩니다.
현재 상태 재생: 현재 상태는 저장된 모든 이벤트를 순차적으로 재생하여 계산할 수 있습니다. 이를 통해 애플리케이션의 상태를 특정 시점으로 되돌리거나 복원할 수 있습니다.
이벤트 불변성: 이벤트는 불변이며, 한번 기록된 이벤트는 변경되지 않습니다. 이는 감사(audit) 기록이나 상태 추적에 유리합니다.
CQS와의 결합: Event Sourcing은 일반적으로 CQRS 패턴과 함께 사용되며, 명령(Command)이 발생하면 이벤트로 기록하고, 이 이벤트를 통해 읽기 모델(Query)를 업데이트합니다.
Event Sourcing: 이벤트 로그가 시스템의 단일 진실 원천(Single Source of Truth)입니다. 모든 상태는 이벤트 로그를 통해 재구성될 수 있기 때문에 데이터 일관성이 매우 중요합니다.
데이터의 마지막 상태만을 저장하는 것이 아닌, 해당 데이터에 수행된 전체 이력을 기록
이벤트 자체를 발행, 끌어가서 알아서 처리
insert만 존재; update/delete 없음
데이터 구조 단순
데이터의 일관성과 트랜잭션 처리 가능
데이터 저장소의 개체를 직접 업데이트 하지 않기 때문에 동시성 충돌 문제 해결
도메인 주도 설계(domain driven design)
aggregate; 데이터의 상태 값을 바꾸기 위한 방법
projection; 현재 데이터 상태 값을 표시하기 위한 방법
메세지 중심의 비동기 작업 처리
단점
모든 이벤트에 대한 복원; 시간
snapshot(중간 세이브포인트; 어느 순간 이후부터 히스토리 쌓기)
다양한 데이터가 여러 조회
cqrs(command and query responsibility segregation)도입으로 해결 가능
명령과 조회의 책임 분리
상태를 변경하는 command
조회를 담당하는 query
saga pattern
SAGA 패턴은 주로 비동기적으로 분산 트랜잭션을 관리하기 위해 사용됩니다. 이 패턴은 분산 시스템에서 트랜잭션 일관성을 유지하는 데 유용하며, 특히 데이터 일관성이 필요한 여러 서비스 간의 장기 실행 트랜잭션(Long-Running Transactions)에 적합합니다.
Saga는 여러 서비스에 걸쳐 진행되는 일련의 로컬 트랜잭션으로 이루어져 있습니다. 각 서비스가 자신의 트랜잭션을 성공적으로 처리하면, 다음 서비스가 트랜잭션을 진행하고, 만약 어느 한 서비스에서 트랜잭션이 실패하면 이전에 성공한 트랜잭션을 보상 트랜잭션을 통해 취소합니다.
구현방식: 어플리케이션에서 트랜젝션 처리하는 방식에 따라서 choreography, orchestration 방식으로 구분됨
어플리케이션이 분리된 경우에는 각각의 local transaction만 처리
각 어플리케이션에 대한 연속적인 트랜젝션에서 실패할 경우
롤백 시 모든 값을 원상복구해야하는데, 관련한 롤백 처리 구현 -> 보상 트랜젝션이 준비되어 있음.
데이터의 원자성을 보장하지 않지만 일관성을 보장
내 할일만 잘하면 됨
장점
탈결합: 서비스가 이벤트를 통해 통신하므로 독립적으로 발전할 수 있습니다.
확장성: 각 서비스가 자체 트랜잭션을 관리하므로 수평적으로 확장이 가능합니다.
회복력: 부분적인 실패와 보상을 허용하여 시스템 회복력을 높일 수 있습니다.
단점
복잡성: 여러 서비스 간에 발생하는 이벤트 흐름을 추적하기 어려워지며, 트랜잭션 경로가 복잡해질 수 있습니다.
최종 일관성(Eventual Consistency): 사가는 즉각적인 일관성을 보장하지 않으며, 시간이 지남에 따라 데이터가 일관성을 갖도록 합니다.
오류 처리: 강력한 오류 처리 및 보상 로직 구현이 어려울 수 있습니다.
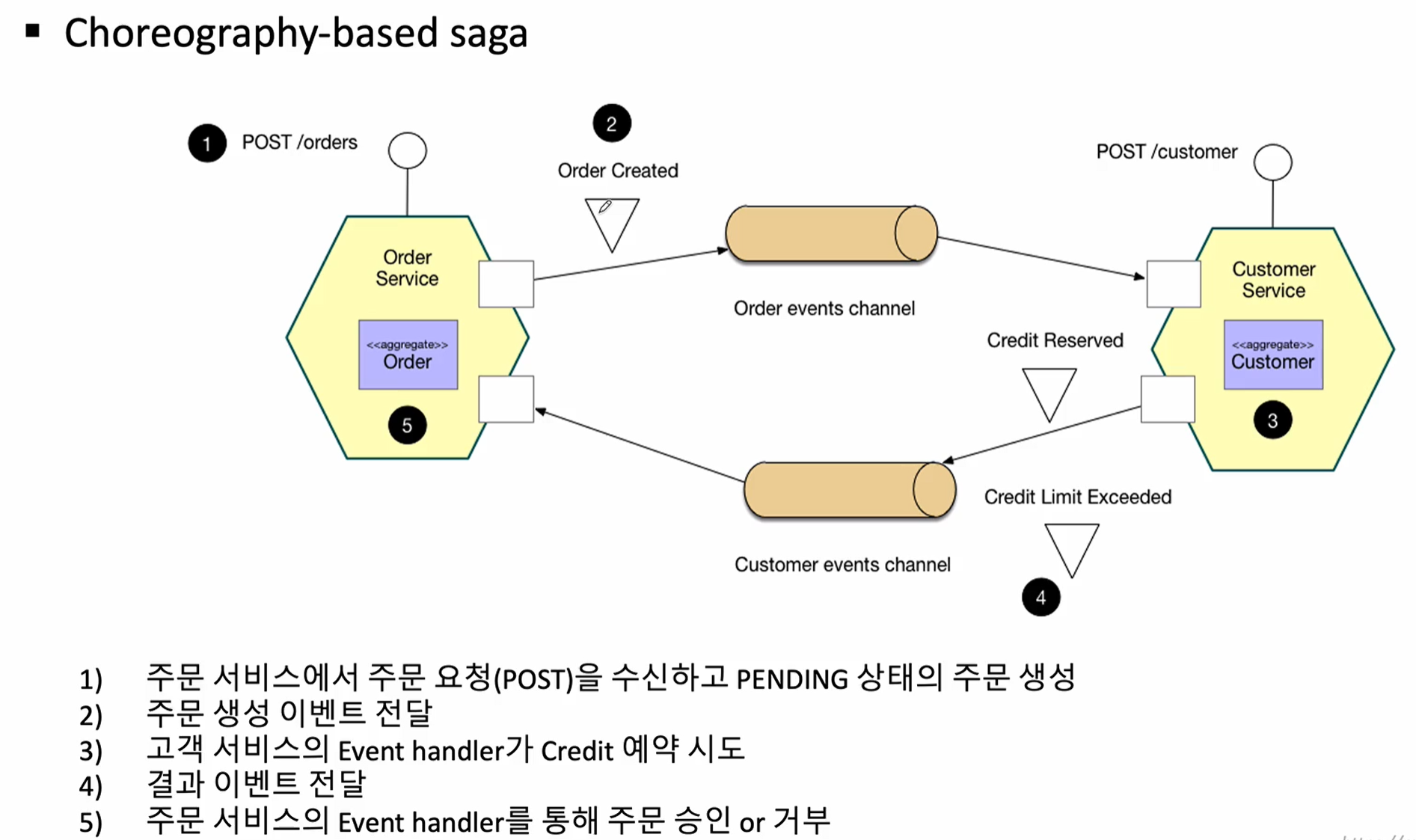
choreography-based saga
비동기 메시징:
코레오그라피 사가는 각 서비스가 이벤트를 발행하고, 다른 서비스들이 이 이벤트를 구독하여 작업을 수행(상태를 조정)하는 방식으로 진행됩니다. 이 과정은 비동기로 이루어지며, 각 서비스는 서로의 상태를 직접 알지 않고 이벤트를 통해 통신합니다. 확장성이 높음
자율성:
각 서비스는 스스로/독립적으로 행동하며, 다른 서비스와의 상호작용을 이벤트로만 처리합니다. 이러한 자율성 덕분에 서비스 간의 결합도가 낮아지고, 시스템의 유연성이 증가합니다.
상태 관리:
코레오그라피 사가는 각 서비스가 자신의 상태를 관리합니다. 서비스는 다른 서비스의 상태에 의존하지 않고, 이벤트에 따라 자신의 행동을 결정합니다.
장애 복구:
장애 발생 시 각 서비스는 발행된 이벤트에 따라 적절한 복구 작업을 수행할 수 있습니다. 실패한 작업을 롤백하기 위한 이벤트를 수신하고 처리할 수 있기 때문에 전체 시스템의 복원력을 높일 수 있습니다.
SAGA Choreography의 장점
서비스 간의 느슨한 결합: 각 서비스는 자신의 트랜잭션만 신경 쓰며, 다른 서비스와는 이벤트를 통해 통신하므로 결합도가 낮습니다.
확장성: 서비스들이 독립적으로 동작하므로, 새로운 서비스를 쉽게 추가할 수 있습니다.
비동기 처리: 이벤트 기반 아키텍처이기 때문에 각 서비스는 비동기로 트랜잭션을 처리할 수 있습니다.
SAGA Choreography의 단점
복잡성 증가: 여러 서비스 간에 발생하는 이벤트 흐름을 추적하기 어려워지며, 트랜잭션 경로가 복잡해질 수 있습니다.
순환 참조 문제: 서비스 간의 이벤트 의존도가 높아지면 이벤트가 서로 꼬이는순환 참조문제가 발생할 수 있습니다.
보상 트랜잭션 관리: 오류가 발생했을 때 롤백을 위한 보상 트랜잭션을 관리하는 로직이 복잡해질 수 있습니다.
SAGA의 코레오그래피 패턴을 안정적으로 운영하려면 여러 가지 고려 사항이 필요합니다. 코레오그래피에서는 각 서비스가 자신의 비즈니스 로직을 처리하면서 필요한 메시지를 전송하고, 실패 처리도 자체적으로 관리하는 방식입니다. 이 방식의 주요 장점은 중앙 관리자가 없다는 것입니다. 하지만 이로 인해 시스템의 복잡성도 높아지고, 신뢰성과 일관성 확보가 어려운 경우도 있습니다. 안정적인 운영을 위한 몇 가지 중요한 점들을 아래에 정리해 보겠습니다. (다운타임 고려)
1. 메시지 브로커의 안정성 확보
코레오그래피에서는 서비스 간의 통신을 비동기적으로 메시지를 통해 이루어지기 때문에, 메시지 브로커(예: Kafka, RabbitMQ)가 핵심적인 역할을 합니다. 이 시스템이 다운되거나 메시지 유실이 발생하면 전체 사가가 실패할 수 있습니다.
메시지 영속성: 메시지 브로커는 재시작되더라도 메시지가 손실되지 않도록 보장 / 메시지를 영속적으로 저장할 수 있도록 설정
Kafka는 기본적으로 로그 기반 아키텍처를 사용하여 메시지를 디스크에 영속적으로 저장하므로 높은 내구성을 제공합니다. 메시지가 파티션에 기록되고, 각 파티션은 순서가 보장되며, 복제 설정을 통해 장애 발생 시에도 데이터 손실을 방지할 수 있습니다.소비자는 이전에 처리된 메시지로부터 다시 시작할 수 있는 유연성을 제공합니다.
스토리지: Kafka는 로그 기반 시스템으로, 메시지가 디스크에 지속적으로 기록되며, 지정된 기간 동안 또는 설정된 크기까지 보존됩니다.
반면RabbitMQ는 기본적으로 메모리 기반 큐로, 영속성을 위해 추가적인 설정이 필요합니다. 영속성을 위해 메시지를 디스크에 저장하면 성능 저하가 발생할 수 있습니다. 따라서 대규모 데이터 처리 및내구성이 중요한 시스템에서는 Kafka가 더 적합할수 있습니다.
메세지 보장:
래빗 - 메시지 확인 및 재처리:
소비자가 메시지를 처리할 때ACK(Acknowledge) 또는NACK(Negative Acknowledge)를 사용하여 메시지의 처리가 성공적으로 완료되었는지 여부를 브로커에 알립니다.
ACK: 소비자가 메시지를 성공적으로 처리한 후에 ACK를 보내면, RabbitMQ는 해당 메시지를 큐에서 제거합니다.
NACK: 메시지 처리가 실패했을 경우 소비자는 NACK를 보내어 메시지를 다시 큐에 추가하거나 다른 큐로 이동할 수 있습니다. 이는 메시지 손실을 방지하는 데 도움을 줍니다.
만약 소비자가 다운될 경우, 처리되지 않은 메시지는 브로커에 남아 있게 되어, 후에 재시도할 수 있습니다. 이로써 서비스가 다시 시작되면 미처리된 메시지를 재처리할 수 있습니다.
카프카 - 오프셋 관리:
Kafka와 같은 로그 기반의 메시징 시스템을 사용하면, 각 소비자는 자신의 오프셋(offset)을 관리할 수 있습니다. 이를 통해 서비스가 재시작되더라도마지막으로 처리한 메시지 이후의메시지만 읽을 수 있어, 데이터 손실 없이 안정적으로 운영할 수 있습니다.
오프셋 관리: 소비자가 메시지를 처리한 후 해당 메시지의오프셋을 커밋하여 카프카 브로커에 저장합니다. 오프셋은 각 파티션에서 메시지가 몇 번째인지에 대한 정보입니다. 이 커밋은 소비자가 해당 메시지를 성공적으로 처리했음을 카프카에 알려주는 역할을 합니다.
메시지 처리 완료 확인: 소비자는 커밋된 오프셋을 기준으로 메시지가 이미 처리되었음을 확인하고, 다음에 읽을 메시지를 결정합니다.
메시지 중복 방지: 카프카는 마지막 커밋된 오프셋부터 메시지를 소비하므로, 오프셋을 잘 관리하면 메시지의 중복 처리를 방지할 수 있습니다.
재시도 메커니즘: 메시지 브로커에서 메시지 처리가 실패했을 때 일정 횟수까지재시도를 할 수 있는 메커니즘을 도입합니다. 재시도 횟수를 제한하거나, 실패한 메시지는 DLQ(Dead Letter Queue)에 보관하고, 해당 메시지에 대해 수동 또는 자동으로 복구할 수 있는 절차를 마련합니다.
RabbitMQ는 Dead Letter Queue(DLQ)와 Retry Queue를 활용하여 메시지가 처리되지 않았을 경우 이를 다시 시도하도록 할 수 있습니다.
2. 모니터링과 트레이싱 / 알람
코레오그래피 패턴에서는 각 서비스가 독립적으로 행동하기 때문에, 문제 발생 시 전체 시스템에서 어떤 서비스가 문제를 일으켰는지 추적하는 것이 중요합니다. 메시지 처리 지연, 실패율 등을 관찰하고, 문제가 발생할 경우 경고를 받을 수 있습니다.
분산 추적 시스템: 예를 들어, OpenTelemetry, Zipkin, Jaeger 등을 사용하여 분산 트레이싱을 설정합니다. 이를 통해 각 서비스에서 발생하는 요청과 응답을 추적하고, 실패나 지연이 발생한 지점을 쉽게 파악할 수 있습니다.
로그 집합 시스템: 각 서비스에서 발생하는 로그를 통합하여 분석할 수 있는 시스템(예: ELK Stack, Prometheus, Grafana)을 구축합니다. 서비스 간 메시지 흐름을 추적하고, 오류를 신속하게 발견할 수 있도록 합니다.
3. 상태 관리와 보상 트랜잭션
코레오그래피 패턴에서는 각 서비스가 자신만의 상태를 관리하며, 실패 시 보상 트랜잭션을 처리해야 합니다. 보상 트랜잭션이란 이전 단계에서 발생한 변경을 되돌리는 작업을 의미합니다.
보상 트랜잭션 설계: 각 서비스는 실패가 발생할 경우 보상 작업을 자동으로 실행해야 합니다. 예를 들어, 결제 처리 서비스에서 결제가 실패하면 이전에 발생한 예약을 취소하는 등의 처리를 해야 합니다.
보상 트랜잭션의 신뢰성: 보상 트랜잭션이 실패하지 않도록, 처리되는 모든 작업은 idempotent(멱등성; 중복 실행 시 동일한 결과를 보장하는) 방식이어야 합니다. 이를 통해 여러 번 재시도가 이루어져도 시스템이 일관성 있게 동작할 수 있습니다.
보상 트랜잭션의 회복: 보상 트랜잭션 역시 실패할 수 있기 때문에, 보상 작업이 실패하면 이를 다시 시도하거나 수동으로 복구할 수 있는 시스템을 마련해야 합니다.
4. 데이터 일관성 확보
코레오그래피 패턴에서는 이벤트 기반으로 서비스가 통신하므로, 데이터 일관성 문제를 해결하는 것이 중요합니다. 서비스 간의 데이터 변경이 일관되게 이루어지도록 해야 합니다.
최종 일관성 보장: 코레오그래피 패턴은 강력한 일관성(ACID) 대신 최종 일관성(eventual consistency)을 제공합니다. 즉, 시간이 조금 걸릴 수 있지만 모든 서비스가 일관된 상태에 도달하도록 설계해야 합니다. 이를 위해 서비스들이 동일한 이벤트를 처리하는 순서를 보장하거나, 가능한 한 빠르게 일관된 상태로 수렴할 수 있도록 해야 합니다.
5. SLA(서비스 수준 계약, Service Level Agreement)와 트랜잭션의 타임아웃
서비스들이 비동기적으로 처리되기 때문에 각 단계의 응답 시간이 지연될 수 있습니다. 각 서비스가 적절한 시간 내에 작업을 완료하지 않으면 전체 SAGA가 실패할 수 있습니다.
SLA 설정: 각 서비스의 작업에 대해 적절한 SLA(Service Level Agreement)를 설정하고, 이 SLA를 기준으로 타임아웃을 설정하여 시스템이 적절한 시간 내에 작업을 완료할 수 있도록 합니다.
ex. 모든 API 요청에 대한 응답 시간은 200ms 이내로 처리
응답 시간의 95%는 200ms를 초과하지 않아야
최대 응답 시간은 500ms를 초과할 수 없음
타임아웃 처리: 각 서비스가 SLA를 지키지 않으면, 적절한 처리(예: 오류 로그 기록, 알림 발송, 재시도 등)를 통해 전체 트랜잭션을 관리합니다.
6. 이벤트 소싱
모든 상태 변경을 이벤트로 기록하고 이를 통해 현재 상태를 재구성할 수 있는이벤트 소싱(Event Sourcing)패턴을 활용할 수 있습니다. 이렇게 하면 각 서비스가 발생한 이벤트를 기반으로 자신의 상태를 재구성할 수 있어, 데이터의 일관성을 유지하는 데 도움이 됩니다.
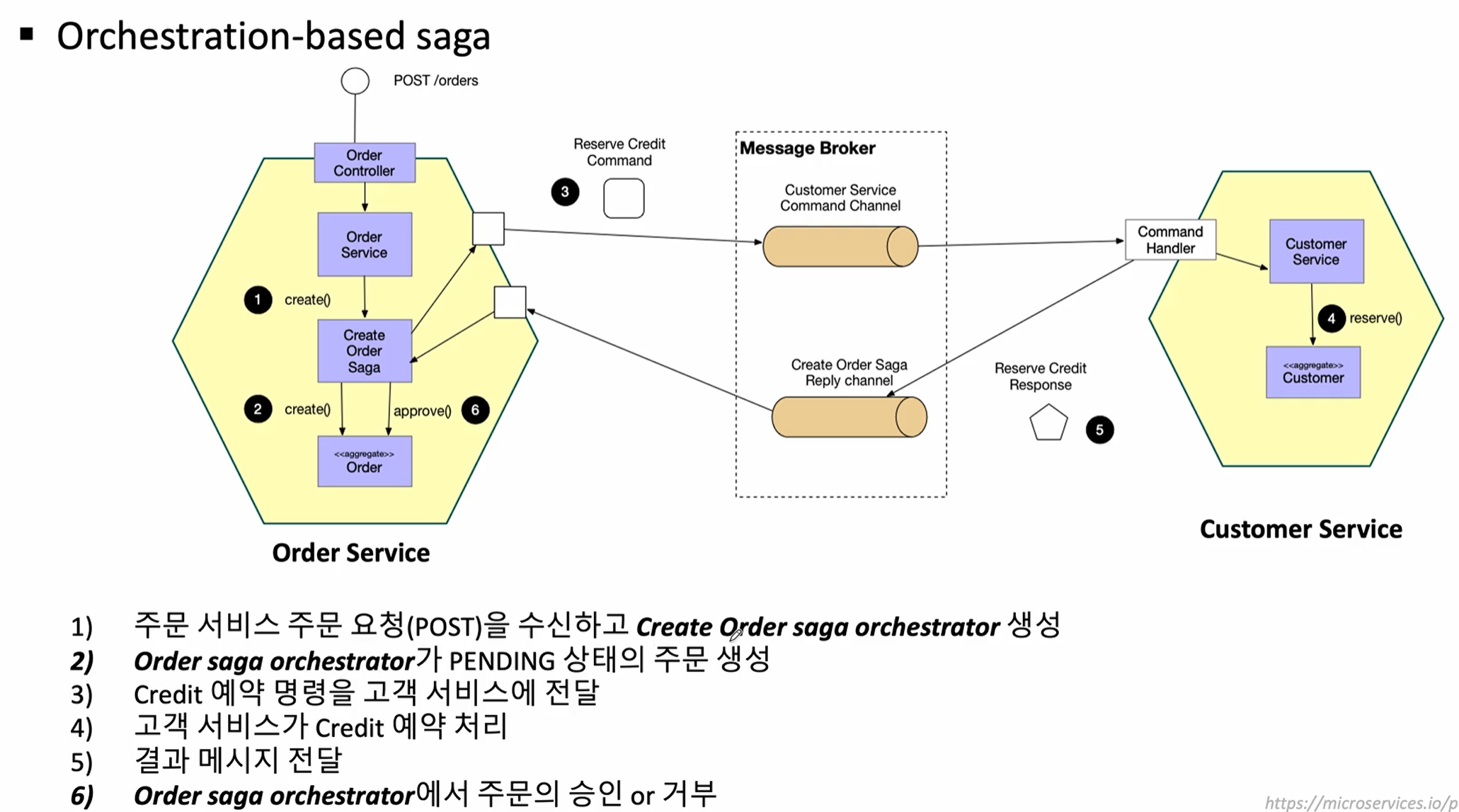
orchestration-based saga
중앙 통제자: 중앙 조정자(orchestrator) 역할을 하는 서비스가 각 서비스의 트랜잭션을 관리합니다. 이 조정자는 트랜잭션 단계를 순차적으로 실행하고, 필요한 경우 보상 작업을 수행합니다.
흐름 제어: 오케스트레이터는 각 서비스 호출의 순서를 정의하고, 에러 처리나 롤백도 중앙에서 관리합니다. 동기/비동기 모두 가능
장점:
단순한 흐름 제어: 중앙에서 모든 것을 관리하기 때문에 트랜잭션 흐름이 명확합니다.
에러 처리 및 롤백이 통합되어 관리되므로 일관성을 유지하기 쉽습니다.; 오류 처리 쉬움
단점:
Single Point of Failure: 중앙 통제자가 다운될 경우 전체 트랜잭션이 영향을 받습니다.
확장성 문제: 모든 트랜잭션을 중앙에서 관리하기 때문에 트랜잭션 수가 많아질수록 부담이 커질 수 있습니다.
1. 동기식 오케스트레이션
설명: 모든 서비스 호출이 순차적으로 진행되며, 각 서비스 호출이 완료될 때까지 대기합니다. 즉, 오케스트레이터가 각 서비스에 요청을 보내고 응답을 받을 때까지 기다립니다.
장점:
단순한 흐름: 트랜잭션의 흐름이 명확하고 예측 가능하여 디버깅과 모니터링이 용이합니다.
즉각적인 오류 처리: 오류가 발생하면 즉시 대응할 수 있으며, 다음 단계로 진행하기 전에 에러 처리를 수행할 수 있습니다.
단점:
지연: 각 서비스 호출이 완료될 때까지 기다려야 하므로 전체 트랜잭션의 실행 시간이 늘어날 수 있습니다.
스케일 문제: 동기식 호출이 많아지면 시스템의 성능이 저하될 수 있습니다.
2. 비동기식 오케스트레이션
설명: 서비스 호출이 비동기적으로 이루어지며, 오케스트레이터는 각 서비스에 요청을 보내고 응답을 기다리지 않고 다음 작업을 진행합니다. 일반적으로 메시지 큐를 사용하여 서비스 간의 통신을 처리합니다.
장점:
성능 향상: 각 서비스가 독립적으로 작동하므로 동시에 여러 요청을 처리할 수 있어 성능이 향상됩니다.
유연성: 서비스 간의 느슨한 결합을 유지할 수 있으며, 서비스가 독립적으로 확장될 수 있습니다.
단점:
복잡성: 비동기 통신은 흐름을 이해하고 디버깅하기 더 어렵게 만들 수 있습니다.
오류 처리: 각 서비스가 비동기적으로 작동하므로 에러 발생 시 처리하기가 더 복잡해질 수 있습니다.
오케스트레이터는 복잡한 프로세스나 워크플로우를 관리하고 조정하는 시스템입니다. 마이크로서비스 아키텍처에서는 다양한 서비스 간의 상호작용을 관리하는 데 사용됩니다. 오케스트레이터는 일반적으로 다음과 같은 역할을 합니다:
서비스 간의 호출 순서 및 의존성을 관리
오류 처리 및 재시도 로직 구현
상태를 모니터링하고 필요한 경우 알림 전송
오케스트레이터는 여러 형태로 구현될 수 있습니다:
전용 프로그램:
Apache Airflow, Camunda, Temporal과 같은 오케스트레이션 도구는 비즈니스 프로세스를 자동화하고 조정하는 데 사용됩니다. 이들 도구는 복잡한 워크플로우를 설계하고 실행하는 데 필요한 기능을 제공합니다.
메시지 브로커:
Kafka와 같은 시스템은 메시지를 전달하고 여러 서비스 간의 통신을 조정할 수 있지만, 기본적으로는 오케스트레이션 기능을 제공하지 않습니다. Kafka는 주로 데이터 스트리밍 및 이벤트 기반 아키텍처에 사용되며, 오케스트레이션과는 다릅니다. 하지만 오케스트레이터와 메시지 브로커를 함께 사용하여 전체 시스템을 구성하는 것이 일반적..
서비스 메쉬:
Istio와 같은 서비스 메쉬는 마이크로서비스 간의 통신을 관리하고 보안, 트래픽 관리, 모니터링 등의 기능을 제공합니다. 이러한 솔루션도 오케스트레이션의 일종으로 간주될 수 있습니다.
2 phase commit
2PC(2-Phase Commit, 2단계 커밋)는 분산 데이터베이스 시스템에서 트랜잭션을 안전하게 커밋하기 위해 사용하는 프로토콜입니다. 이 프로토콜은 여러 데이터베이스 또는 서비스가 관련된 트랜잭션을 일관성 있게 처리하기 위해 설계되었습니다.
2-Phase Commit 동작 단계
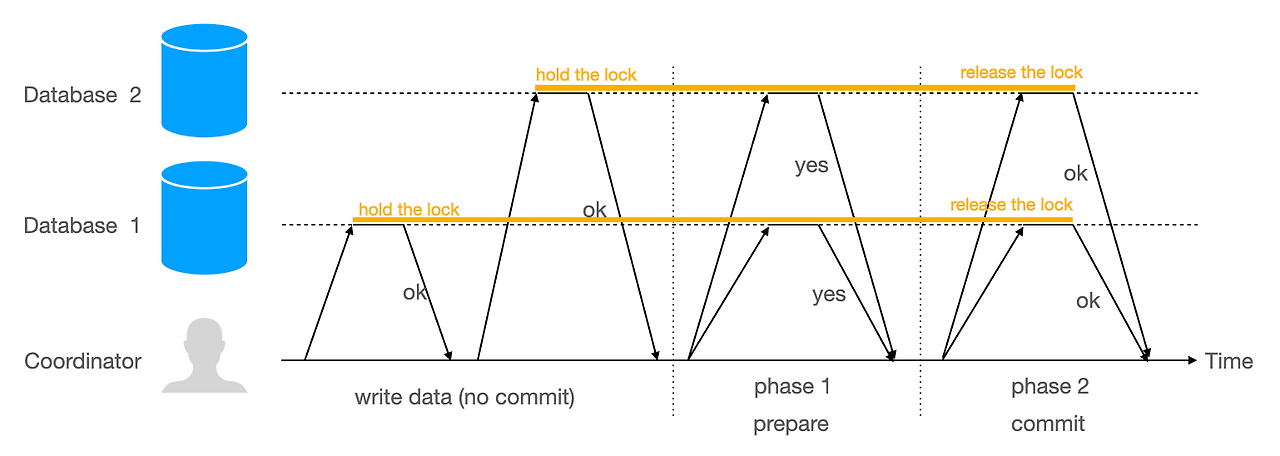
Prepare 단계:
**트랜잭션 코디네이터(Coordinator)**가 모든 참여 노드(또는 서비스)에 "Prepare" 메시지를 전송합니다.
각 참여자는 트랜잭션을 수행할 준비가 되면 로컬로 락을 설정하고 "Yes"(준비 완료) 응답을 보냅니다.
만약 어떤 노드가 준비되지 않거나 실패하면 "No"(준비 실패) 응답을 보냅니다.
Commit 단계:
코디네이터가 모든 노드로부터 "Yes" 응답을 받으면, 각 노드에 **트랜잭션을 커밋(commit)**하도록 지시하고 트랜잭션이 완료됩니다.
위 코드에서 2PC의 Prepare 단계와 Commit 단계는 트랜잭션 매니저(JtaTransactionManager)에 의해 관리됩니다. 코드 자체에는 Prepare와 Commit이라는 명시적인 단계가 보이지 않지만, JtaTransactionManager가 내부적으로 이 과정을 수행합니다.
MySQL에서 UPDATE 쿼리를 실행할 때, InnoDB는 기본적으로 **행 잠금(Row Lock)**을 사용하여 UPDATE 대상이 되는 행을 잠급니다. 다른 트랜잭션에서 읽을 수는 있지만, 실제로 쓰기를 시도하려면 트랜잭션이 완료될 때까지 기다려야 하므로 일시적인 충돌은 방지됩니다. 하지만 다수의 트랜잭션에서 동시에 동일한 데이터를 수정하려고 하면 **경쟁 조건(Race Condition)**이 발생할 수 있습니다.
INSERT 쿼리에서 InnoDB는 기본적으로 행 잠금을 사용하지 않습니다. 즉, INSERT가 실행될 때는 행에 락을 걸지 않으며, 다른 트랜잭션은 동시에 다른 행을 삽입할 수 있습니다.
auto_increment 필드를 사용하는 경우, InnoDB는 자동 증가 값을 생성할 때 해당 레코드에 잠금을 걸 수 있습니다. 이 값이 충돌하지 않도록 내부적으로 관리되기 때문입니다.
예를 들어, 여러 트랜잭션이 동시에 INSERT를 시도할 때, 자동 증가 값에 대한 충돌을 피하기 위해 자동 증가 번호를 추적하기 위한 락이 필요합니다. 이 경우 다른 트랜잭션은 번호가 할당될 때까지 대기할 수 있습니다.
1. Prepare 단계
Prepare 단계는 트랜잭션 관리자가 각 데이터 소스에 트랜잭션을 시작하고 작업을 준비시키는 과정입니다. 여기서 중요한 역할을 하는 부분은 @Transactional 애너테이션입니다. 이 애너테이션을 통해 트랜잭션이 시작되면 다음과 같은 작업들이 순서대로 진행됩니다.
트랜잭션 매니저는 각각의 데이터 소스에 대해 트랜잭션을 시작합니다.
updateWarehouse1와 updateWarehouse2 쿼리를 실행하여 각 데이터베이스에 변경 사항을 기록합니다.
Prepare 단계에서는 실제 커밋을 수행하지 않고, 각 데이터베이스에 잠금(Lock)을 통해 데이터의 일관성을 보장합니다.
만약 이 단계에서 에러가 발생하면 JtaTransactionManager가 rollback을 호출하여 전체 트랜잭션이 취소됩니다.
2. Commit 단계
Commit 단계는 모든 준비가 완료된 후, 각 데이터 소스에 대해 트랜잭션을 실제로 커밋하는 과정입니다. 이 단계에서는 다음 작업들이 수행됩니다.
트랜잭션 매니저가 각 데이터 소스에 commit 명령을 내리고, 모든 변경 사항을 데이터베이스에 영구적으로 반영합니다.
각 데이터베이스가 성공적으로 커밋되면, 트랜잭션이 완료됩니다.
만약 이 과정에서 하나라도 실패하면 rollback이 호출되어 모든 데이터베이스의 작업이 원상복구됩니다.
정리하면:
@Transactional 애너테이션을 통해 시작되는 트랜잭션이 Prepare 단계에서 두 데이터베이스에 모두 준비된 상태로 변경 작업을 적용한 후 잠금을 유지합니다.
트랜잭션 매니저가 커밋을 호출하면서, 실제 변경 사항이 모든 데이터베이스에 커밋되는 것이 Commit 단계입니다.
2-Phase Commit에서의 락(Lock)과 문제점
락의 사용:
각 참여 노드는 "Prepare" 단계에서 트랜잭션에 관련된 자원을 락합니다. 이 락은 트랜잭션의 커밋 또는 롤백이 완료될 때까지 유지되어, 다른 트랜잭션이 해당 자원에 접근하지 못하게 합니다.
이 락은 데이터 일관성을 유지하는 데 필수적이지만, 락을 길게 유지하면 성능 저하가 발생할 수 있습니다.
문제점:
블로킹(Blocking): 한 노드가 준비 상태에서 응답을 보내지 못하거나 장애가 발생하면, 코디네이터는 트랜잭션의 커밋 또는 롤백을 기다려야 하므로 전체 트랜잭션이 중단될 수 있습니다.
확장성 문제: 트랜잭션이 많아지고 락을 획득하는 시간이 길어질수록 시스템의 성능이 저하됩니다.
고립된 락: 참여자가 죽거나 네트워크 분리가 발생하면 락이 해제되지 않는 문제가 발생할 수 있습니다.
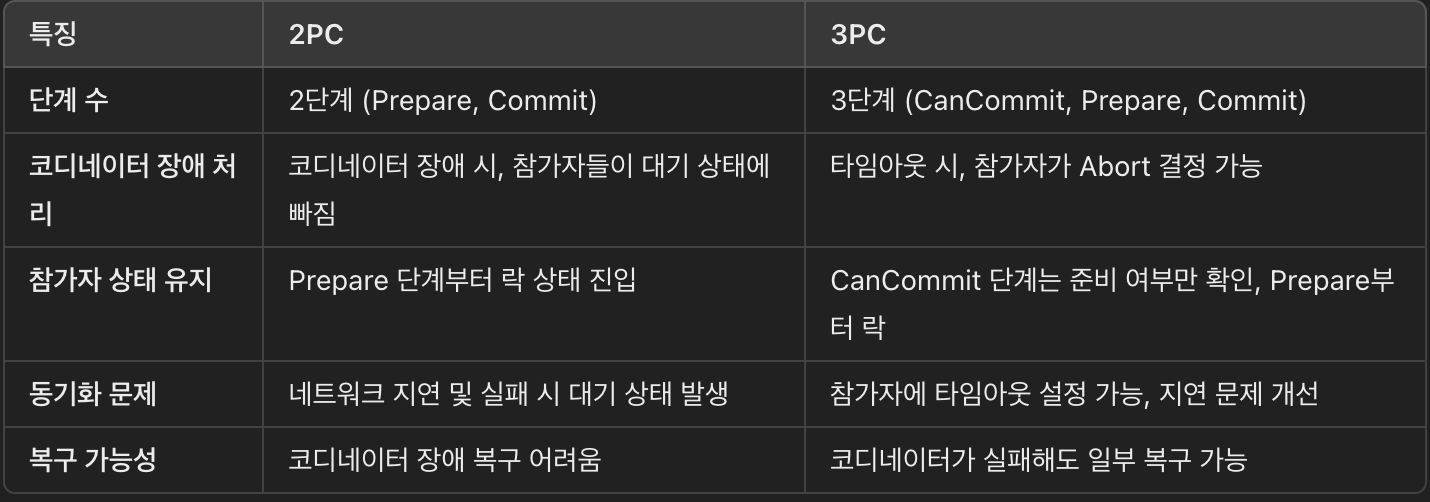
이러한 문제로 인해, 2PC는 락 비용이 크고 고가용성을 요구하는 시스템에는 적합하지 않으며, 대신 SAGA 패턴이나 **3-Phase Commit(3PC)**과 같은 대안이 사용되기도 합니다.
실패 가능 시나리오
1. Prepare 단계에서 참가자 실패
상황: 코디네이터가 각 참가자에게 Prepare 메시지를 보내고 승인을 기다리는 동안, 한 참가자가 응답하지 않거나 실패하는 경우입니다.
처리 방식:
대기 하다가
타임아웃 설정(권장): 참가자가 Prepare 단계에서 정해진 시간 내에 응답하지 않으면, 코디네이터는 해당 참가자를 실패로 간주합니다.
롤백 결정: 코디네이터는 전체 트랜잭션을 롤백하기로 결정하고 모든 응답한 참가자에게 Rollback 명령을 보냅니다.
일관성 보장: 응답하지 않은 참가자 역시, 복구 시 자신의 트랜잭션을 롤백하는 규칙을 따릅니다.
2. Commit 단계에서 참가자 실패
상황: 모든 참가자가 Prepare 요청에 승인했으나, Commit 명령을 기다리는 도중에 일부 참가자가 실패합니다.
처리 방식:
Commit 의무: Prepare에서 Commit을 승인한 참가자는 이후 반드시 Commit을 완료해야 합니다.
복구 프로세스: 실패한 참가자는 복구되었을 때 로그를 확인하여 Commit 또는 Rollback을 수행합니다. 참가자는 Prepare 단계에서 승인 후 실패하면, 복구 후 반드시 Commit을 실행해야 일관성이 유지됩니다.
코디네이터가 '대기'하는 것이 아닌, 참가자가 로그를 확인하는 방식: 코디네이터는 더 이상 해당 트랜잭션을 대기하지 않고 종료
3. Prepare 단계에서의 코디네이터 실패:
대기 상태 유지: 참가자는 Commit 또는 Rollback 명령을 받을 때까지 대기합니다.
코디네이터가 Prepare 메시지를 보낸 후 실패하면, 참가자들은 각자의 상태를 Prepared로 유지하며 Commit 또는 Rollback 명령을 기다립니다.
이 시점에서는 코디네이터의 복구나 교체 없이는 참가자들이 개별적으로 Commit이나 Rollback을 결정하지 못하므로, 참가자들은 일시적으로 대기 상태에 들어갑니다.
타임아웃 및 복구: 코디네이터가 복구되면 로그를 확인해 Prepare 상태를 마친 참가자에게 Commit 또는 Rollback을 지시합니다. 새로운 코디네이터가 지정되거나 기존 코디네이터가 복구되기를 기다리며 재시도를 합니다.
재시도 메커니즘: 참가자가 코디네이터의 상태를 감지할 수 있도록 재시도 메커니즘을 적용할 수 있습니다. 코디네이터가 다시 살아날 경우 트랜잭션을 다시 시도할 수 있습니다.
참가자들은 일정 시간 동안 코디네이터의 응답을 기다리도록 타임아웃을 설정할 수 있습니다. 타임아웃이 발생하면 참가자는 문제가 생겼음을 인식하고 롤백 프로세스를 시작하게 됩니다.
코디네이터가 복구되거나 새로운 코디네이터가 지정되면 모든 참가자들의 상태 로그를 검토하여 트랜잭션 상태(Commit 또는 Rollback)를 확인합니다.
4. Commit 단계에서의 코디네이터 실패:
Commit 명령을 받은 후 코디네이터가 실패한 경우:
코디네이터가 모든 참가자에게 Commit 명령을 전달한 후에 실패했다면, 대부분의 참가자는 이미 Commit을 완료했을 것입니다.
각 참가자는 트랜잭션 로그에 Commit 완료 상태를 기록하여 코디네이터가 없는 상태에서도 트랜잭션 완료 상태를 기억할 수 있습니다.
새로운 코디네이터가 복구되면 참가자들의 로그 상태를 조회해 일관성을 검증하고, 트랜잭션이 Commit으로 완료되었는지 확인합니다.
Commit 명령이 일부 참가자에게 전달되지 않은 경우:
코디네이터가 일부 참가자에게 Commit 명령을 보내기 전에 실패하면, 이 경우 일부 참가자만 Commit을 수행하고 나머지 참가자는 Prepared 상태로 남아 있을 수 있습니다.
이때 참가자들은 코디네이터의 복구나 새로운 코디네이터가 지정될 때까지 로그를 통해 자신의 상태를 유지하며 대기하게 됩니다.
새로운 코디네이터는 각 참가자의 상태를 확인하여, 이미 Commit을 완료한 참가자가 있으면 전체 트랜잭션을 Commit하도록 모든 참가자에게 지시합니다.
최종적으로 Commit을 보장하기 위한 절차:
새로운 코디네이터가 지정되면, 각 참가자에게 현재 트랜잭션 상태를 질의하고 이를 바탕으로 트랜잭션의 일관된 완료 상태를 결정합니다.
만약 일부만 Commit을 완료한 상태로 확인되면, 모든 참가자에게 Commit 명령을 다시 전달하여 트랜잭션을 완결시킵니다.
이 과정을 통해 트랜잭션은 무조건 동일한 최종 상태(Commit 또는 Rollback)로 마무리되며, 코디네이터가 Commit 단계에서 실패하더라도 로그와 상태 확인을 통해 일관성을 보장합니다.
2PC의 장점
트랜잭션 일관성 보장:
모든 참여 시스템이 트랜잭션을 동시에 커밋하거나 롤백하기 때문에 데이터 일관성을 유지할 수 있습니다. 이는 금융 시스템이나 다른 중요한 데이터가 관련된 애플리케이션에서 필수적입니다.
구현의 단순성:
두 가지 단계(Prepare 및 Commit)로 이루어져 있어 구현이 상대적으로 단순합니다. 트랜잭션 관리가 필요한 경우 쉽게 적용할 수 있습니다.
2PC의 단점
코디네이터의 단일 실패점:
코디네이터가 실패하면 모든 참가자가 해당 트랜잭션에 대해 무기한으로 대기하게 되어 시스템이 불안정해집니다. 코디네이터 장애 복구가 어려워 전체 트랜잭션에 영향을 줄 수 있습니다.
참가자의 무한 대기 문제:
Prepare 단계에서 승인 후 // 코디네이터가 Commit이나 Rollback 명령을 전달하지 않으면 참가자들은 대기 상태에 빠집니다. 이는 네트워크 장애나 코디네이터 장애로 인한 무한 대기 문제로 이어질 수 있습니다.
락 유효성 문제
2PC 프로토콜에서는 참가자들이 트랜잭션 상태를 준비하는 동안 데이터에 락을 걸고 대기하므로, 데이터베이스 자원의 락이 장기간 유지될 수 있습니다.
트랜잭션이 길어지면 데이터베이스 자원에 대한 경합이 심해져, 다른 트랜잭션들이 성능 저하를 겪을 수 있습니다.
네트워크 지연 문제:
코디네이터와 각 참가자 간의 통신에서 지연이 발생할 경우 트랜잭션 완료까지 시간이 길어집니다. 이로 인해 자원이 오랫동안 잠금 상태로 유지되어 성능 저하가 발생할 수 있습니다.
네트워크 파티션 문제:
2PC는 네트워크 파티션이 발생할 경우 각 노드가 올바른 결정을 내리기 어려운 문제가 있습니다. 네트워크가 복구될 때까지 모든 시스템이 일관성을 보장할 방법이 없어 데이터 일관성 유지가 어려워질 수 있습니다.
확장성 제한:
2PC는 동기화 방식으로 작동하므로 확장성(scalability) 문제에 직면할 수 있습니다. 분산 시스템에서 많은 참가자가 동시에 참여하는 경우, 각 단계에서 지연이 누적되기 때문에 트랜잭션의 성능 저하가 발생할 수 있으며, 네트워크 지연, 대기 시간, 동기화 비용 등이 시스템 성능에 큰 영향을 미칠 수 있습니다.
로그 활용과 복구 절차
참가자와 코디네이터의 로그 기록: 모든 참여자는 트랜잭션 진행 상황을 로그에 기록하여, 장애 발생 시 트랜잭션 상태를 복구하는 데 사용합니다. 예를 들어, Prepare 승인 여부, Commit 및 Rollback 상태 등을 기록합니다.
복구 절차:
코디네이터 복구: 코디네이터는 복구 시 자신의 로그를 확인하여 아직 완료되지 않은 트랜잭션을 찾고, 참가자에게 나머지 명령을 수행하도록 합니다.
참가자 복구: 참가자는 복구 시, 마지막 로그 상태에 따라 트랜잭션을 Commit 또는 Rollback합니다.
동기화 문제와 대안
2PC는 장애 시 동기화 문제로 인해 성능 저하가 발생할 수 있습니다. 이런 상황을 최소화하기 위해 많은 분산 시스템에서는 SAGA 패턴과 같은 비동기 트랜잭션 관리 방식을 선택하기도 합니다.
SAGA 패턴은 복구(데이터 일관성이 맞던 시점으로 돌아가) 및 보상 트랜잭션(되돌리기; 롤백)을 사용하여, 전체 시스템을 잠그지 않고 트랜잭션을 처리하는 대안을 제공합니다.
2-Phase Commit (2PC)은 일반적으로 동기적으로 동작합니다. 즉, 모든 참가자가 각 단계에서 응답을 제공하기 전까지 다음 단계로 진행하지 않는 구조입니다.
Prepare 단계의 동기성:
코디네이터는 각 참가자에게 Prepare 요청을 보내고, 모든 참가자가 성공을 응답할 때까지 대기합니다. 모든 참가자가 준비 완료 상태임을 확인할 때까지 다음 단계인 Commit으로 넘어가지 않습니다.
모든 응답을 기다리기 때문에 각 참가자는 해당 트랜잭션에 대해 락을 걸고 대기하며, 이는 다른 트랜잭션의 접근을 막아 동시성에 영향을 미칩니다.
Commit/Abort 단계의 동기성:
모든 참가자가 Prepare에 응답한 후, 코디네이터는 각 참가자에게 Commit 또는 Abort 명령을 동기적으로 보냅니다.
코디네이터는 모든 참가자의 Commit 응답이 도착할 때까지 최종 완료를 확인하지 않으며, 트랜잭션이 완전히 완료된 것을 보장하기 위해 이 과정을 동기적으로 처리합니다.
동기적 특성으로 인한 제약사항
성능 저하: 모든 참여자의 응답을 기다리는 과정에서 응답 지연이 발생할 수 있습니다.
지연 시간 증가: 네트워크 지연이나 참가자의 성능 문제로 인해 2PC의 완료 시간이 길어질 수 있습니다.
로컬에서 개발할 때, 그리고 운영 환경으로 배포할 때 내용물에 따라 설정파일을 분리할 수 있으며, 환경에 따라 다르게 가져가야 한다.
-- 소스 실행
mvn spring-boot:run -Dspring-boot.run.arguments=--spring.profiles.active=production
-- jar 로 빌드해서 배포
java -Dspring.profiles.active=production service.jar
설정파일은 파일명 자체를 여러가지로 둘 수도 있고, 그 안에서 환경(profile)을 줄 수도 있다.
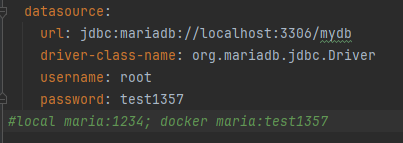
알고보니 로컬에서는 1234로 설정해서 설정파일에 1234로 되어 있었는데, 도커에 마리아 세팅할 때는 다른 패스워드로 하는 바람에 실패난 것. 패스워드를 외부에서 주입받거나 하는 방식도 있겠지만, 우선 수정하고 다시 컴파일하고 도커 이미지 지우고 다시 런하니 성공하였다..
참고로 - v 이후 입력하는 파일 경로에 대문자나 띄어쓰기가 있으면 아래와 같은 에러가 나서 임시로 C아래로 이동해서 실행시켰다.
docker: invalid reference format: repository name (Downloads/prometheus-2.49.1.windows-amd64/prometheus-2.49.1.windows-amd64/prometheus.yml) must be lowercase.
그라파나
docker run -d -p 3000:3000 --network ecommerce-network --name grafana grafana/grafana
기존에 도커로 작업했던 ecommerce-network와 묶이도록 아래처럼 지정, 카프카와 주키퍼는 뜨는 ip를 지하여 후에 프로젝트에서 해당 ip로 접근하도록 수정해야 함.
저장하고 docker daemon(docker desktop)을 실행한다.
아래와 같은 명령어로 docker compose 실행
docker compose로 실행하면 그 안에 여러개의 컨테이너가 들어있어도 마치 하나의 컨테이너처럼 실행 가능하다.
docker-compose -f docker-compose-single-broker.yml up -d
위 명령어를 치면 이미지를 열심히 풀링하다가 아래와 같은 에러가 발생하면서 종료된다.
time="2024-02-25T15:00:21+09:00" level=warning msg="a network with name ecommerce-network exists but was not created by compose.\nSet `external: true` to use an existing network"
network ecommerce-network was found but has incorrect label com.docker.compose.network set to ""