반응형
포인트
- 안정성: 데이터는 소실되면 안됨
- 가용성: 이메일과 사용자 데이터를 여러 노드에 복제하여 계속 동작하게
- 확장성: 사용자 수가 늘어나도 성능 저하 안되게
- 막대한 저장 용량 필요
구 프로토콜과 방식


저장소는 파일 시스템의 디렉터리 but 수십억 개의 이메일을 검색하고 백업하기엔 디스크 IO가 병목이 되고 서버 장애 등 안정적이지 못함
단일 장비 위에서만 동작하도록 설계
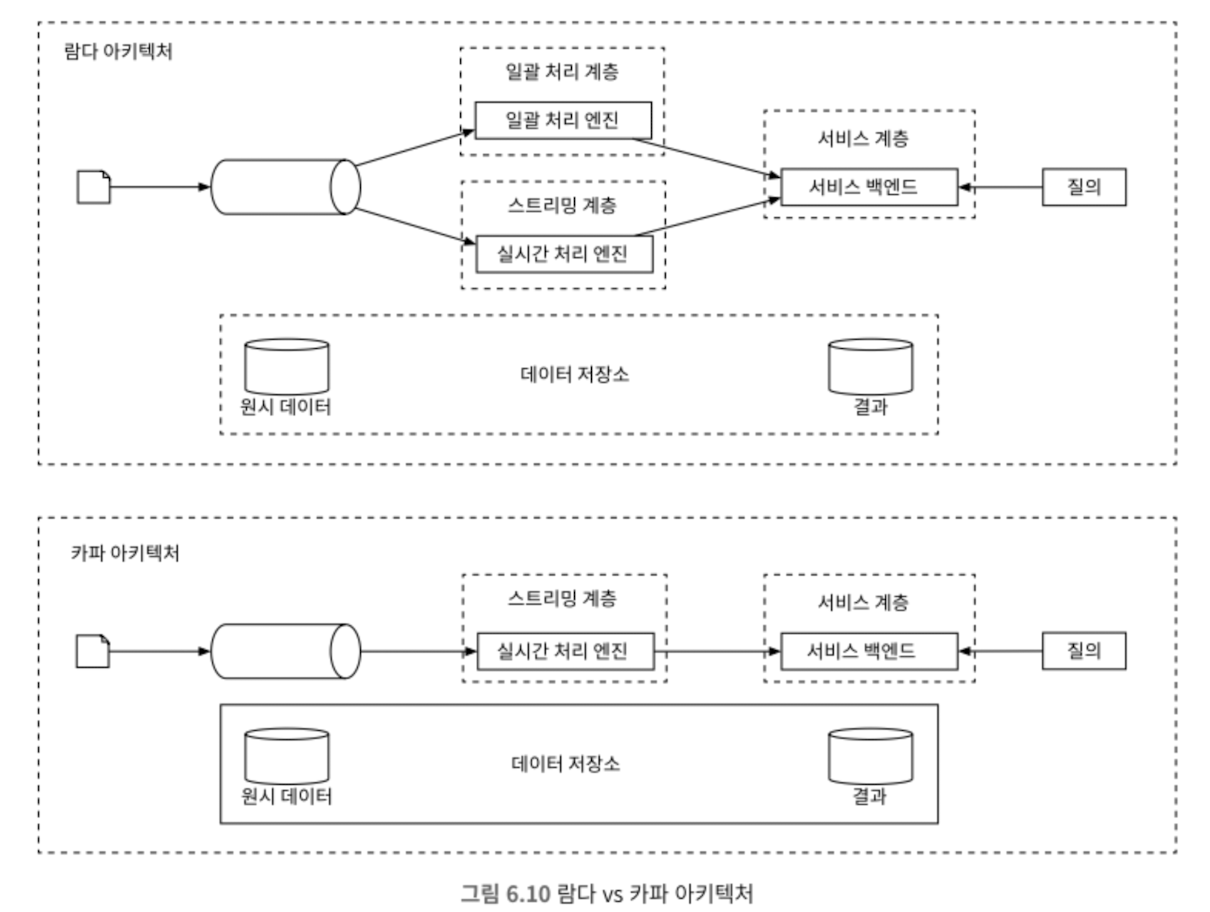
분산 메일 서버 아키텍쳐
보낼 때
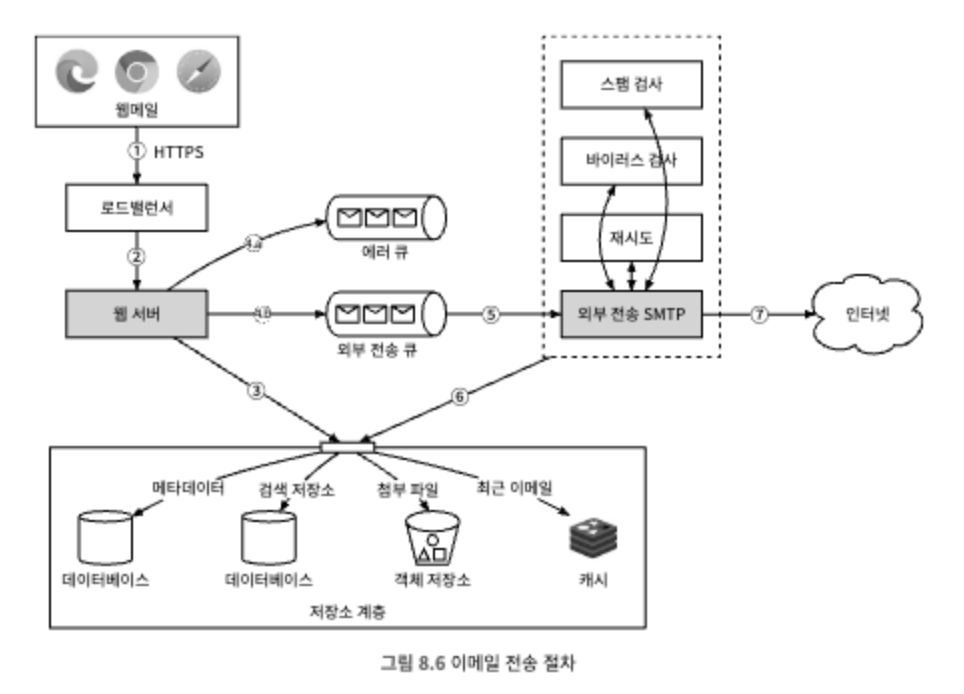
외부 전송 큐에 보관되는 모든 메시지에는 이메일을 생성하는데 필요한 모든 메타데이터가 포함되어 있음
위 5번 과정으로 인해 외부 SMTP규모를 독립적으로 조정할 수 있게 된다.
외부 전송 큐에 오래 남아 있으면 확인 필요
1. 이메일을 보낼 큐의 소비자를 추가
2. 받는 서버에 장애 발생: 재전송 필요; 지수적 백오프
받을 때

디비는? 완벽한 디비는 없음..
RDB? 데이터 크기가 작을 때 적합. BLOB 써도 접근할 때마다 많은 디스크 IO발생
분산 객체 저장소나 Nosql은 키워드 검색이나 읽음 표시 등의 기능을 제공하기 어려움
- 강력한 데이터 일관성 보장
- 디스크 IO 최소화
- 가용성 아주 높아야 하고 일부 장애를 감냉해야
- incremental backup이 쉬워야
유저 키를 파티션키로 사용하여 같은 샤드에 저장
파티션키: 데이터를 여러 노드에 분산하는 역할; 데이터가 모든 노드에 균등하게 분배되도록(유저 키)
클러스터키: 같은 파티션에 속한 데이터를 정렬하는 역할(폴더)
noSQL 기반으로 할 경우 파티션키/클러스터키 외의 필터링을 어플리케이션에서 하거나 쿼리로 하기보단
테이블을 비정규화해서 테이블 자체를 나눠버리는 게 질의 성능을 향상시켜야 하는 대규모 서비스에 더 맞다.
일관성을 위해 replica 필요
- 장애가 발생하면 클라이언트는 main이 복원될 때까지 동기화/갱신 작업을 완료할 수 없음
- 일관성을 위해 가용성을 희생해야
- 가용성을 위해서는 여러 지역의 데이터 센터에 다중화하고 일반적으로는 가까운 데이터센터에서 통신하다 장애가 났을 때 타 지역 데이터센터에 보관된 메시지를 이용한다.
이메일 스레딩
JWZ 알고리즘의 주요 목적
- 이메일 간 Reply-To 관계를 파악해 계층적 트리 구조를 만듦
- 이메일 클라이언트에서 스레드 형태로 메시지를 표시하기 위해 사용.
- 이메일 그룹화를 통해 사용자에게 논리적이고 직관적인 대화 흐름을 제공.
알고리즘 작동 원리
- 헤더 정보 수집
- Message-ID: 각 이메일의 고유 식별자.
- In-Reply-To: 답장 대상 이메일의 Message-ID.
- References: 해당 이메일이 참조한 이전 이메일의 Message-ID 목록.
- 이메일 헤더의 아래 정보를 기반으로 스레드 관계를 결정합니다:
- 스레드 생성 과정
- 모든 이메일의 Message-ID와 **Reply 관계(In-Reply-To, References)**를 분석.
- 이메일을 **노드(Node)**로 보고, Message-ID를 키로 하여 초기 노드 목록을 생성.
- 각 이메일의 In-Reply-To 및 References를 순회하며 부모-자식 관계를 설정.
- 스레드 트리를 형성하며, 루트 노드(시작 이메일)부터 트리가 확장됨.
- 루트 노드와 고아 처리
- 루트 노드: Reply 관계가 없는 독립된 이메일로, 새로운 스레드의 시작점이 됨.
- 고아 메시지: 부모가 없는 이메일. (헤더 정보가 손상되거나 누락된 경우 발생)
- 별도의 루트 노드로 처리하거나, 관련성이 가장 높은 메시지에 병합.
- 정렬
- 시간 순서(예: 날짜/시간) 또는 논리적 Reply 순서에 따라 트리를 정렬.

이메일 검색을 위해
- elastic search 활용하거나 자체 개발할 솔루션
- 디스크 I/O 병목 주의
- 색인을 구축하는 프로세스는 다량의 쓰기 연산을 발생시키므로 LSM(Log Structured Merge) 트리를 사용하여 디스크에 저장되는 색인을 구조화하는 것이 바람직
LSM 트리가 색인 구축에 적합한 이유
- 쓰기 연산의 효율성
- LSM 트리는 데이터를 먼저 메모리(RAM) 내의 MemTable에 기록하고, 특정 조건(예: 크기 초과)이 충족되면 이를 **정렬된 SSTable(파일 단위)**로 디스크에 순차적으로 저장합니다.
- 디스크에 순차 쓰기가 이루어지므로 디스크 I/O 비용이 감소하고, 색인을 구축할 때 발생하는 다량의 쓰기 작업을 효율적으로 처리할 수 있습니다.
- 쓰기 병목 현상 완화
- 기존의 B-트리와 같은 데이터 구조는 **랜덤 쓰기(Random Write)**가 많아지는 단점이 있습니다.
- 반면, LSM 트리는 랜덤 쓰기를 최소화하고, 데이터를 버퍼링 후 배치 처리하여 쓰기 병목을 완화합니다.
- 색인 업데이트의 성능 향상
- 색인을 업데이트할 때, 기존 데이터를 즉시 덮어쓰지 않고 새로운 데이터를 추가한 뒤 Compaction(압축) 과정을 통해 병합합니다.
- 이를 통해 쓰기와 병합 작업이 분리되어 성능이 향상됩니다.
- 다량의 색인 생성
- 색인을 구축하는 도중에 읽기 연산이 발생하더라도, LSM 트리는 메모리 내 데이터와 디스크 데이터를 병합하여 읽기 요청을 처리할 수 있습니다.
- 색인 작업 도중에도 안정적으로 데이터를 처리할 수 있는 구조를 제공합니다.
LSM 트리 작동 과정
- MemTable: 데이터를 메모리에 기록 (쓰기 연산 집중).
- Flush: MemTable이 가득 차면, 이를 디스크에 **SSTable(Sorted String Table)**로 기록.
- Compaction: 여러 개의 SSTable을 병합하여 디스크 공간을 최적화하고 읽기 성능을 향상.
728x90
반응형
'개발 > 도서 스터디' 카테고리의 다른 글
| [대규모 시스템 설계 기초2] 10장 실시간 게임 순위표(레디스, dynamo) (0) | 2025.01.29 |
|---|---|
| [대규모 시스템 설계 기초2] 9장 S3와 유사한 객체 저장소 (0) | 2025.01.28 |
| [대규모 시스템 설계 기초2] 7장 호텔 예약 시스템 (0) | 2025.01.27 |
| [대규모 시스템 설계 기초2] 6장 광고 클릭 이벤트 집계 (1) | 2025.01.26 |
| [대규모 시스템 설계 기초2] 5장 지표 모니터링 및 경보 시스템 (0) | 2025.01.25 |