
포인트
- 탑 10 표시
- 특정 유저의 등수
- 특정 유저 +-4등
- 점수 업데이트는 실시간
점수 갱신 시 다른 곳에서도 사용되거나 여러 기능을 지원해야 한다면 2번에 카프카를 넣을 수도 있다.
- 분석 서비스, 푸시 알림 서비스 등

데이터모델
RDB
규모 확장성이 중요하지 않고 사용자 수가 많지 않다면 (유저아이디-점수)
레코드가 수백만 개로 많아지면 성능이 너무 나빠진다.
인덱스를 걸어도 결국 순위를 알려면 기본적으로 전체 테이블을 훑어야 하므로 성능이 떨어진다.
레디스
메모리 기반 키-값 저장소, sortedSet 이용
탑 10에 해당하는 유저의 추가 정보는 hash로 올려주면 순위표 작성 시 수월
개념
- Redis의 Sorted Set(ZSET)은 유니크한 값(value)과 함께 각 값에 대응하는 점수(score)를 저장하는 데이터 구조
- 데이터는 점수(score) 기준으로 정렬되어 저장되며, 동일한 점수일 경우 삽입 순서에 따라 유지됨
- 내부적으로 hash table과 skip list라는 두 자료구조 사용
- skip list: sorted singly linked list 에 다단계 색인(아래 그림)을 두는 구조; 대량 데이터에서 특정 범위 검색에 효과적
구성 요소
- Key: Sorted Set의 이름
- leaderboard_feb_2024
- Value: 유일한 요소(데이터)
- user id
- Score: 실수(double) 형태의 정렬 기준 값
- 1
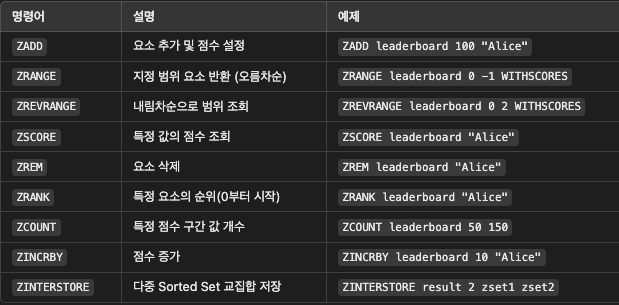
- zincrby leaderboard_feb_2024 'nancy1234' 1 //점수 +1
- zrevrange leaderboard_feb_2024 0 9 withscores //탑 10
- zrevrange leaderboard_feb_2024 'nancy1234' //특정 유저 등수 :234가 나왔다면
- zrevrance leaderboard_feb_2024 234-4 234+4 //+- 4등 유저

저장소 요구사항
- 메모리
- ID 24자 문자열, 점수가 16비트 -> 한 항목당 26바이트 -> 26바이트 * 2500만 명 = 6억 5000만 바이트 = 650mb
- 이런 식으로 대충 계산해서 메모리 할당 가능한지 확인
- CPU & IO사용량
- 최대 QPS 2500/초 -> 한대로도 감당가능
- 영속성
- 레디스 replica 두어 ha 대비
- 탑 10 정도는 캐시
일반적인 세팅
AWS 사용
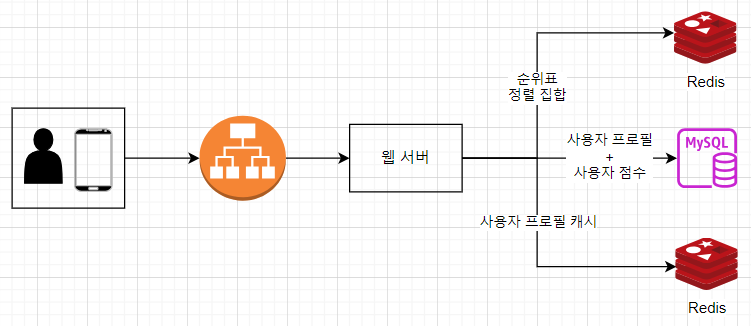
게이트웨이 + 람다
- 람다는 서버리스 컴퓨팅 플랫폼
- 서버를 준비하거나 관리하지 않고 코드를 실행할 수 있음. 필요할 때만 실행되며 트래픽에 따라 그 규모가 자동으로 확장됨.
- api gw가 호출되면 게이트웨이는 적절한 람다 함수를 호출한다. 람다 함수는 스토리지 계층을 호출하고 그 결과를 게이트웨이에 반환한다.
레디스 샤딩
고정 파티션
- 점수 범위별로 샤드를 나눠(0~100점, 100~200점 등)
- 점수가 고르게 분포되었을 때 유리
- 점수가 증가하면 다른 샤드로 옮겨야 함
- 사용자가 어떤 샤드에 알기 위해 mysql에 현재 점수를 저장하거나 2차 캐시를 사용해야 한다
해시 파티션
- 사용자 점수가 몰려있을 경우
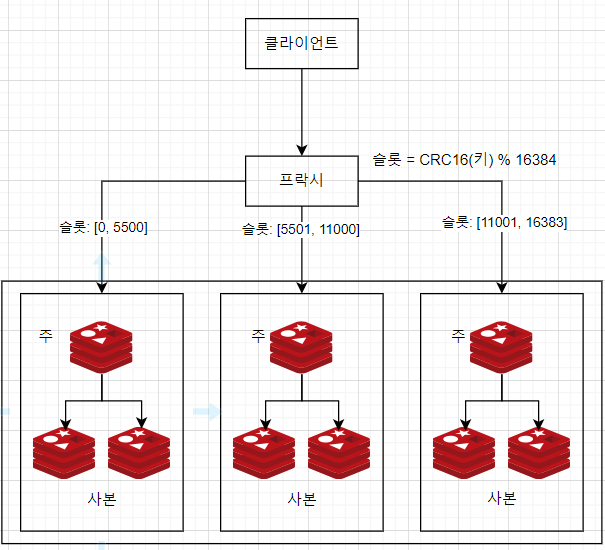
- Redis 클러스터는 데이터 분산을 위해 해시 슬롯(Hash Slots)을 사용하여 클러스터 내 여러 노드에 데이터를 효율적으로 분배
해시 슬롯 구조
- Redis 클러스터는 0부터 16383까지의 해시 슬롯(총 16384개)으로 구성
- 각 슬롯은 특정 키 범위를 담당하며, 여러 노드에 균등하게 분배
SLOT = CRC16(key) % 16384데이터 분배
- 클러스터에 노드가 추가되면 슬롯들이 여러 노드에 나누어 배정
- 예: 3개의 노드로 구성된 클러스터 → 각 노드는 약 5461개 슬롯을 담당
- Node A → 슬롯 0 ~ 5460
- Node B → 슬롯 5461 ~ 10922
- Node C → 슬롯 10923 ~ 16383
해시 태그(Hash Tag)
- 특정 키들을 같은 슬롯에 저장하려면 중괄호 {}를 사용
- 예를 들어, "user:{123}:name"와 "user:{123}:email"은 같은 해시 슬롯에 저장
- 이유: 해시 계산 시 중괄호 안의 문자열인 123만 사용
데이터 접근 방식
- 클라이언트는 요청할 키에 대해 해시 슬롯을 계산
- 해당 해시 슬롯에 연결된 노드로 요청이 라우팅
- 노드 장애 시 복제본 노드(Replica)가 활성화되어 고가용성 보장
Redis 클러스터 운영 예시
- 노드 A 장애 → 자동으로 슬롯 재분배 및 복제본 승격
- 새로운 노드 추가 → 슬롯 자동 이동
- 노드가 추가되거나 제거되면 Redis는 슬롯 재배정을 통해 데이터를 균등하게 분산
- 분배는 항상 균등성을 지향
- 하지만 수동 설정이 가능하므로 특정 노드에 더 많은 슬롯을 할당할 수도 있음
장점
- 데이터 자동 분산
- 확장성 증가
- 장애 복구 기능(Replication)
단점
- 설정 및 운영 복잡성
- 일부 명령어(KEYS, MULTI, EXEC) 제한
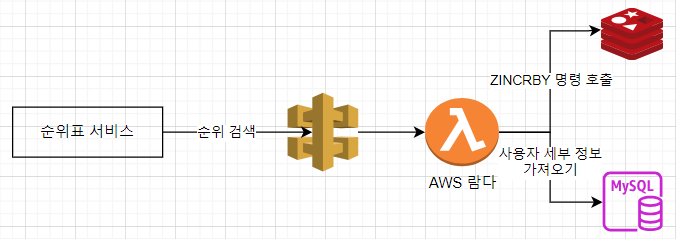
위 방법에서 탑 10을 추리려면 각 샤드에서 탑 10 뽑아서 애플리케이션 단에서 재정렬하여 추려야 한다. 샤드가 많으면 시간이 지연됨
쓰기가 많은 애플리케이션에서는 장애에 대비해 스냅숏을 찍을 때 모든 쓰기 연산을 감당해야 하기 때문.. 보통 메모리를 두 배 더 할당하는 것이 안전하다.
레디스 성능 벤치마킹을 위해 redis-benchmark를 사용하여 초당 얼마나 많은 요청을 처리할 수 있을지 시뮬 해보는 것도 필요하다.
레디스 클러스터에도 레디스 데이터가 유실되는 경우를 대비해 Mysql에 시간과 함께 로그를 저장해 주면 해당 값을 다시 레디스로 옮기는 script를 사용하여 복구 가능하다.
NoSQL
쓰기 연산 최적화, 같은 파티션의 항목을 정렬
- 아마존 dynamoDB, mongo..
레디스 대신 dynamo로 바꾸면,, 비정규화 데이터를 담어야 하고
파티션 키를 game_name#{year-month}로 잡고 점수를 정렬 키로 잡는 게 좋다.
파티션 키가 최근 달이라 hot partition이 될 거고 부하가 높으면 문제다.
한 달을 n개 파티션으로 분할하고 userId % n으로 샤딩 할 수 있다. 읽기/쓰기 모두 복잡해진다.
n은 쓰기 볼륨이나 daily active user 수를 고려해서 정하면 된다.
탑 10을 고를때 각 파티션별로 탑10 골라서 애플리케이션 단에서 최종 탑10을 선정한다(분산-수집 법)
개인의 정확한 등수를 구하는 것보다 상위 x% 인지 알려주는 게 더 나을 수 있다.
'개발 > 도서 스터디' 카테고리의 다른 글
| [대규모 시스템 설계 기초2] 3장 구글맵(SSE, ws) (2) | 2025.02.02 |
|---|---|
| [대규모 시스템 설계 기초2] 1장 근접성 서비스(지오해시) (0) | 2025.01.31 |
| [대규모 시스템 설계 기초2] 9장 S3와 유사한 객체 저장소 (0) | 2025.01.28 |
| [대규모 시스템 설계 기초2] 8장 분산 이메일 서비스 (0) | 2025.01.27 |
| [대규모 시스템 설계 기초2] 7장 호텔 예약 시스템 (0) | 2025.01.27 |