
아마존 S3 저장소
restful api로 이용 가능한 객체 저장소

블록저장소, 파일저장소, 객체저장소



- 블록 저장소 (Block Storage) - 초기 기술
- 등장 배경: 가장 기본적인 데이터 저장 방식으로, 물리적인 디스크를 논리적인 블록 단위로 분할하여 데이터를 저장.
- 이유: 초기 컴퓨터 시스템에서는 데이터를 빠르고 효율적으로 관리하기 위해 디스크의 저수준 접근 방식이 필요했음.
- 특징: 파일 시스템이 없었고, 데이터를 단순히 블록 단위로 읽고 쓰는 구조.
- 파일 저장소 (File Storage) - 블록 저장소 기반
- 등장 배경: 사용자가 데이터를 더 쉽게 관리할 수 있는 고수준 인터페이스가 필요.
- 이유: 디렉터리 구조와 파일 경로를 통해 사용자가 데이터를 논리적으로 구분하고 접근할 수 있도록 하기 위해 블록 저장소 위에 파일 시스템을 개발.
- 특징: 블록 저장소를 기반으로 동작하며, 데이터를 파일 단위로 관리.
- 객체 저장소 (Object Storage) - 현대적 기술
- 등장 배경: 클라우드 컴퓨팅 및 대규모 데이터 관리의 요구 증가.
- 이유: 메타데이터를 포함한 객체 단위의 저장과 확장성을 제공하기 위해 파일 저장소의 한계를 극복.
- 특징: HTTP API를 통해 접근하며, 데이터 불변성과 확장성이 강조됨.
객체 저장소는 디스크 용량이나 초당 디스크 IO가 병목이 될 가능성이 높다.
- 객체 불변성: 변경 불가능하고 삭제 후 새 객체로 대체해야
- 저장은 한번만 읽기는 여러 번
- 다양한 크기의 객체를 문제없이 저장
- 키-값 저장소: URI-데이터로 연결됨
- 메타데이터와 객체의 실제 데이터를 분리; 메타데이터는 가변; 실제 데이터는 불변
- 객체는 버킷 안에 두어야 한다: 버킷 생성 -> 객체 생성 (요청 각각)
- 버킷은 디렉터리 같은 계층 구조를 지원하지 않지만 버킷 이름과 객체이름을 연결하여 폴더 구조를 흉내 내는 논리적 계층을 만들 수 있다.


placement service와 consensus protocol
데이터 저장소를 다중화할 때 이 데이터를 어디에 저장할지 선정하는 placement service는 모든 데이터 노드와 heartbeat을 주고 받으며 상태를 모니터링한다. 매우 중요한 서비스이기에 5-7개의 노드를 갖고 을 사용하여 구축할 것을 권장한다.
- 데이터 일관성 (Consistency)
- 모든 참여 노드가 동일한 데이터에 동의.
- 내결함성 (Fault Tolerance)
- 일부 노드가 장애를 일으키거나 악의적으로 동작해도 시스템이 안정적으로 작동.
- 결정성 (Deterministic Agreement)
- 합의가 끝나면 모든 노드가 동일한 결과를 갖도록 보장.
main하나와 다수의 replica 노드가 존재할 때 모든 replica에 복사되는 것을 모두 기다릴지 일부만 기다릴지에는 데이터 일관성과 지연시간 사이에 trade off가 있다. 어쨌건 모두 결과적 일관성(eventual consistency)은 보장된다.
데이터를 저장할 때는 작은 객체들은 모아서 처리. 이미 존재하는 파일에 추가하는 방식. 용량 한계치에 도달하면 읽기 전용 파일로 변경하고 새로운 파일을 만든다. 멀티 코어인 경우 코어별로 읽기/쓰기 파일을 두어야 blocking 되지 않는다.
uuid로 객체 찾기
관련 정보는 한번 쓰면 수정하지 않고 읽기만 하므로 읽기 성능이 좋은 RDB가 좋다. 이 디비는 노드마다 두면 된다.
데이터 내구성
Erasure Coding (EC) 의미
- Erasure Coding은 데이터를 다수의 블록으로 분할하고 복구를 위한 패리티 블록을 생성하는 데이터 보호 방식
- 일부 데이터 블록이 손실되더라도 남은 데이터와 패리티 블록을 이용해 데이터를 복구할 수 있음
- 분산 시스템, 클라우드 저장소(Amazon S3, Ceph) 등에서 스토리지 효율성과 장애 복구 능력을 위해 활용
예시: EC(4,2)는 4개의 데이터 블록과 2개의 패리티 블록을 포함하며, 전체 6개의 블록 중 최소 4개만 있어도 데이터 복구가 가능
Parity 의미
- Parity(패리티)는 데이터를 검증하거나 복구하기 위해 계산된 검사 코드
- 주로 XOR 연산을 통해 데이터 블록 값을 합성하여 패리티 블록을 생성
- 패리티 블록은 오류가 발생한 데이터 블록을 역으로 계산하여 복구할 수 있음
응답 지연은 높아지지만 내구성은 향상되고 저장소 비용은 낮아진다
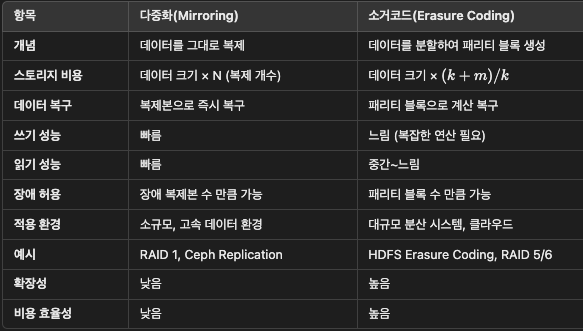
응답 지연이 중요하면 다중화가 좋고 저장소 비용이 중요하면 소거 코드가 좋다.
정확성 검증
데이터 훼손 문제는 디스크에 국한되지 않으며 메모리의 데이터가 망가지고 한다.
원본의 체크섬(해쉬)을 계산하고 전송받은 데이터의 체크섬과 비교하여 정확성을 검증한다. 파일이 읽기 전용으로 전환되기 전에 전체 파일의 체크섬을 파일 말미에 둔다.
메타 데이터 저장소
버켓 테이블은 replica를 마련
객체 테이블은 샤딩; 균등하게 분포하기 위해 샤딩 키를 버킷이름과 객체 이름을 결합하여 사용(URI에서 사용되는 값)
이러면 객체 목록 출력 시 전체 객체를 불러와서 페이징 할 때 번거롭다(union & paging..). 목록 데이터를 비정규화 하여 이 테이블만으로 리스트를 내리게 설계할 수도 있다.
파일 버저닝
덮어쓰지 않고 새로운 버전의 파일을 추가
삭제도 바로 하지 않고 마킹으로
큰 파일 업로드 성능 최정화
멀티파트: 객체를 작게 쪼개서 독립적으로 업로드한 후(etag사용) 그 조각을 모아서 원본 객체를 복원
복원이 끝나야 성공 메시지 반환. 복원 끝나면 조각을 사제하여 저장 용량 확보해야
GC(압축)
객체의 지연 삭제: 삭제 표시된 객체
갈 곳 없는 데이터: 반만 업로드되거나 취소된 데이터
훼손된 데이터: 체크섬 검증 실패
바로 지우지 않고 정리 메커니즘을 주기적으로 실행하여 지운다. main-replica 모두 적용해야 한다.
보통 객체를 새로 복사하면서 삭제할 거 제외하고 복사하며 이때 메타데이터 테이블의 fileName, offset 등을 한 트랜젝션 내에서 수정한다.
'개발 > 도서 스터디' 카테고리의 다른 글
| [대규모 시스템 설계 기초2] 1장 근접성 서비스(지오해시) (0) | 2025.01.31 |
|---|---|
| [대규모 시스템 설계 기초2] 10장 실시간 게임 순위표(레디스, dynamo) (0) | 2025.01.29 |
| [대규모 시스템 설계 기초2] 8장 분산 이메일 서비스 (0) | 2025.01.27 |
| [대규모 시스템 설계 기초2] 7장 호텔 예약 시스템 (0) | 2025.01.27 |
| [대규모 시스템 설계 기초2] 6장 광고 클릭 이벤트 집계 (0) | 2025.01.26 |