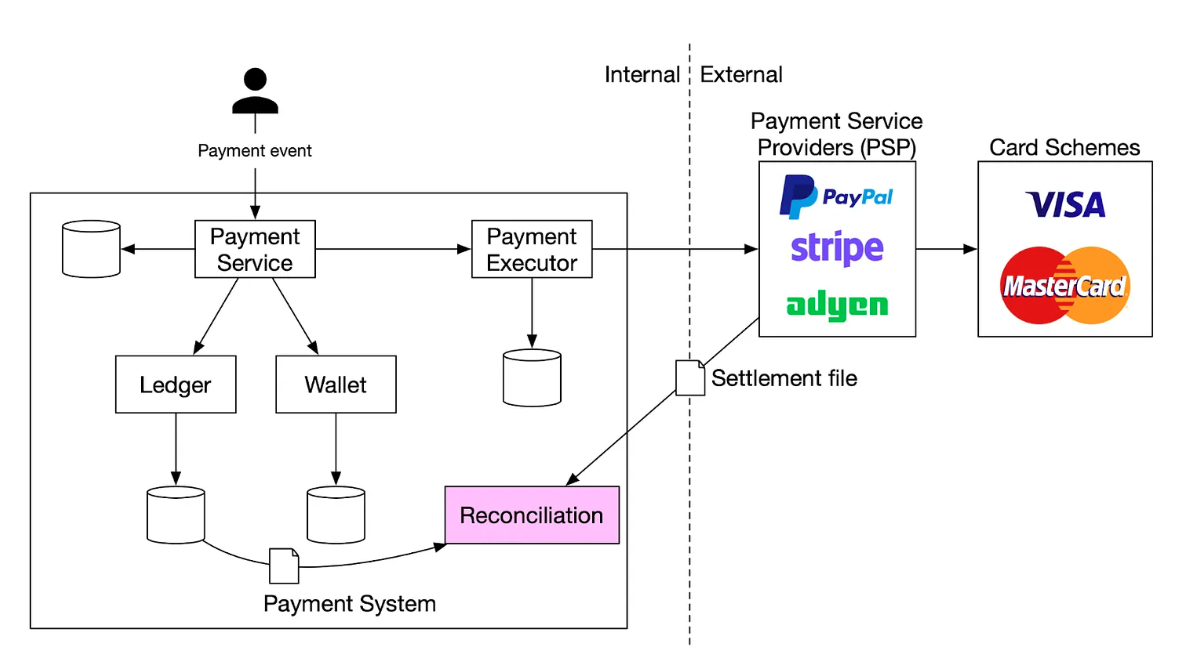
포인트
- QPS: 43,000
- max QPS = 215,000
지연시간
평균 지연 시간은 낮아야 하고 전반적인 지연 시간 분포는 안정적이어야 함.
- 지연시간 = 중요 경로상의 컴포넌트 실행 시간의 합
지연시간을 줄이기 위해서는
- 네트워크 및 디스크 사용량 경감
- 중요 경로에는 꼭 필요한 구성 요소만 둔다. 로깅도 뺀다.
- 모든 것을 동일 서버에 배치하여 네트워크를 통하는 구간을 없앤다. 같은 서버 내 컴포넌트 간 통신은 이벤트 저장소인 mmap를 통한다.
- 각 작업 실행 시간 경감
- 꼭 필요한 로직만
- 지연 시간 변동에 영향을 주는 요소 조사 필요
- gc...
속도
주문 추가/취소/체결 속도: O(1)의 시간 복잡도를 만족하도록
- 추가: 리스트의 맨 뒤에 추가
- 체결: 리스트의 맨 앞에 삭제
- 취소: 리스트에서 주문을 찾아 삭제
주문 리스트는 DoubleLinkedList여야 하고 Map을 사용하여 주문을 빠르게 찾아야 한다.
영속성
시장 데이터는 실시간 분석을 위해 메모리 상주 칼럼형 디비(KDB)에 두고 시장이 마감된 후 데이터를 이력 유지 디비에 저장한다.
- KDB+는 Kx Systems에서 개발한 고성능 시계열 데이터베이스로, 대규모 데이터 분석에 최적화되어 있다. 주로 금융 업계에서 빠른 데이터 처리와 분석을 위해 사용된다.
- 초고속 데이터 처리 능력
- 시계열 데이터를 효율적으로 저장 및 분석
- 시간에 따라 변화하는 데이터를 저장하고 관리하는 데 최적화된 데이터베이스
- 시계열 데이터는 각 데이터 포인트가 타임스탬프와 함께 기록되는 데이터
- 금융 거래 데이터, 센서 데이터 등 대규모 데이터를 실시간으로 처리 가능
어플리케이션 루프
- while문을 통해 실행할 작업을 계속 폴링하는 방식
- 지연시간 단축을 위해 목적 달성에 가장 중요한 작업만 이 순환문 안에서 처리
- 각 구성 요소의 실행 시간을 줄여 전체적인 실행 시간을 예측 가능하도록 보장
- 효율성 극대화를 위해 어플리케이션 루프는 단일 스레드로 구현하며 CPU에 고정
- context switch가 없어지고
- 상태를 업데이트하는 스레드가 하나뿐이라 락을 사용할 필요 없고 잠금을 위한 경합도 없다.
- 단 코딩이 복잡해짐
- 각 작업이 스레드를 너무 오래 점유하지 않도록 각 작업 시간을 신중하게 분석해야 함
mmap
mmap은 메모리 맵핑 (Memory Mapping)을 의미하며, 운영체제에서 제공하는 기능으로, 파일을 프로세스의 메모리에 맵핑하여 파일의 내용을 메모리 주소 공간에서 직접 읽고 쓸 수 있도록 한다. 이를 통해 파일 입출력(I/O) 속도를 향상시키고, 프로세스 간의 메모리 공유를 효율적으로 처리할 수 있다.
/dev/shm 메모리 기반 파일 시스템으로 여기에 위치한 파일에 mmap를 수행하면 공유 메모리에 접근해도 디스크io는 발생하지 않는다.
이벤트 소싱
현재 상태를 저장하는 대신 상태를 변경하는 모든 이벤트의 변경 불가능한(immutable) 로그를 저장
이벤트를 순서대로 재생하면 주문 상태를 복구 가능(이벤트 순서가 중요)
지연시간에 대한 엄격한 요구사항으로 카프카 사용 불가, mmap 이벤트 저장소를 메세지 버스로 사용(카프카 펍섭 구조와 비슷)
- 주문이 들어오면 publish되고 주문 데이터가 필요한 각 컴포넌트가 subscribe 한다.
이벤트는 시퀀스, 이벤트 유형, SBE(simple binary encoding; 빠르고 간결한 인코딩을 위해) 인코딩이 적용된 메시지 본문으로 구성되어 있다.
게이트웨이는 이벤트를 링 버퍼에 기록하고 시퀀서가 링 버퍼에서 데이터를 가져온다(pull). 시퀀서가 이벤트 저장소(mmap)에 기록한다(pub).
- 링 버퍼(Ring Buffer), 또는 원형 버퍼(Circular Buffer)는 고정된 크기의 버퍼로, 마지막 위치에 도달하면 다시 처음 위치로 돌아가서 덮어쓰는 방식으로 동작하는 자료구조. 링 버퍼는 주로 고정 크기의 메모리 할당을 유지하면서 데이터를 효율적으로 관리하고, FIFO(First In, First Out) 방식으로 데이터를 처리하는 데 사용됨. 데이터를 넣고 꺼내기만 하고 생성이나 삭제하는 연산은 필요 없다. 락도 사용하지 않는다.
고가용성
서비스 다운 시 즉시 복구
- 거래소 아키텍처의 단일 장애 지점을 식별해야 한다.
- 장애 감지 및 백업 인스턴스로 장애 조치 결정이 빨라야
서버 재시작 후 이벤트 저장소 데이터를 사용해 모든 상태를 복구한다.
주 서버의 문제를 자동 감지해야 하는데, 위에서 단일 서버로 설계했기 때문에 클러스터로 구성해야 하며 주서버의 이벤트 저장소는 모든 부 서버로 복제해야 한다.
이때 reliable UDP를 사용하면 모든 부 서버에 이벤트 메시지를 효과적으로 broadcast 할 수 있다.
- 모든 수신자가 동시에 시장 데이터를 받도록 보장
- 멀티캐스트: 하나의 출처에서 다양한 하위 네트워크상의 호스트로 보냄, 그룹에 가입한 수신자들만 데이터를 수신. 브로드캐스트와 유니캐스트의 중간
부 서버도 죽으면? fault tolerant
DRM마냥 여러 지역의 데이터 센터에 복제 필요..
- 주 서버가 다운되면 언제, 어떻게 부서버로 자동 전환하는 결정을 내리나
- request가 이상하면? 소스 자체가 문제라면? => 운영 노하우를 쌓을 동안 수동으로 장애 복구
- 부 서버 가운데 새로운 리더는 어떻게 선출
- 검증된 리더 선출 알고리즘(주키퍼, raft..)
- 복구 시간 목표(Recovery Time Objective)는 얼마
- 어플리케이션이 다운되어도 사업에 심각한 피해가 없는 최댓값
- 어떤 기능을 복구(Recovery Point Objective) 해야 하나
- 손실 허용 범위, 거의 0에 가깝게
보안
- 공개 서비스와 데이터를 비공개 서비스에서 분리하여 디도스 공격이 가장 중요한 부분에 영향을 미치지 않도록. 동일한 데이터를 제공해야 하는 경우 읽기 전용 사본을 여러 개 만들어 문제를 격리
- 자주 업데이트되지 않는 데이터는 캐싱
- 디도스 공격에 대비해 아래와 같이 쿼리 파람에 제한을 둔다. 이렇게 바꾸면 캐싱도 유리하다.
- before: /data?from=123&to=456
- after: /data/recent
- 블랙리스트/화이트리스트 작성
- 처리율 제한 기능 활용
'개발 > 도서 스터디' 카테고리의 다른 글
| [대규모 시스템 설계 기초2] 4장 분산 메세지 큐 (0) | 2025.01.24 |
|---|---|
| [대규모 시스템 설계 기초2] 12장 전자 지갑(분산 트랜젝션, 이벤트소싱, CQRS) (0) | 2025.01.19 |
| [대규모 시스템 설계 기초2] 11장 결제시스템(exactly once) (1) | 2025.01.17 |
| 자바와 Junit을 활용한 실용주의 단위 테스트 7장 (0) | 2023.08.08 |
| 자바와 Junit을 활용한 실용주의 단위 테스트 5장 (0) | 2023.07.25 |