
반응형
ForkJoinPool은 Java 7에 도입된 병렬 처리 프레임워크로, 작업을 작은 단위로 분할(fork)하고 병렬로 처리한 후 다시 합치는(join) 방식으로 동작한다. 병렬 프로그래밍과 작업 스케줄링을 위한 강력한 도구로, 특히 대규모 데이터 처리나 계산 집약적인 작업에 유용하다.
이게 프레임워크?
- 고수준의 작업 관리: ForkJoinPool은 작업 스케줄링, 워크 스틸링, 병렬 처리 등을 관리하는 메커니즘을 제공한다. 개발자가 세부적인 스레드 관리나 큐 처리 등을 직접 코딩하지 않아도 된다.
- 제어 역전 (IoC, Inversion of Control): 작업 실행과 스레드 관리는 ForkJoinPool이 수행하며, 개발자는 작업의 논리만 작성
- 작업 분할 및 병합 전략: RecursiveTask와 RecursiveAction이라는 추상 클래스를 기반으로 작업을 설계하며, 내부적으로는 효율적인 작업 분할 및 병합을 자동으로 처리한다.
- 워크 스틸링 (Work Stealing): 스레드 풀에서 작업 큐를 관리하며, 비활성 스레드가 다른 활성 스레드의 큐에서 작업을 가져와 실행하는 동적 작업 분배를 한다.(처리량을 최적화); 개발자가 구현할 필요 없이 forkjoinpool이 자동으로 처리
- 표준화된 인터페이스: 개발자가 사용할 수 있는 명확한 API (invoke, submit, fork, join 등)를 제공. 이로 인해 복잡한 병렬 프로그래밍을 간단히 구현할 수 있음.
장점
- 멀티코어를 활용하여 작업을 병렬로 처리하므로 CPU 사용률이 최적화
- 워크 스틸링을 통해 비효율적인 작업 분배를 방지
단점
- 작업 분할 및 병합에 대한 오버헤드가 존재
- I/O 중심 작업에서는 비효율적이며, CPU 집약적인 작업에 적합
적합한 상황
- 데이터가 많고, 병렬로 처리할 수 있는 작업
- 재귀작업/반복적으로 작업을 나눌 수 있을 때 (예: 합계, 정렬)
- CPU 집약적인 작업에서 최적의 성능을 얻고자 할 때
개발 시 전체적인 흐름
- 큰 작업이면 Fork하여 병렬 처리.
- 작은 작업이면 직접 계산으로 효율적 처리.
- 모든 계산이 끝나면 병렬 결과를 Join하여 최종 결과를 얻음.
작은 작업은 직접 계산하는 이유
- 작업 분할의 비용 문제:
- Fork/Join Framework는 큰 작업을 작은 작업으로 나누고 각 작업을 병렬적으로 실행
- 하지만 작업을 너무 많이 나누면 작업 분할과 작업 병합(merge)에 드는 오버헤드(비용)가 커질 수 있음
- 작은 작업에 대해서는 작업 분할을 하지 않고 직접 계산하여 오버헤드를 줄임
- 효율성 최적화:
- 일정 크기 이하의 작업은 더 이상 병렬로 처리할 필요가 없으므로 직접 계산이 더 효율적
- 예를 들어, 배열의 일부를 합산하거나 특정 범위의 숫자를 더하는 간단한 작업이라면, 병렬처리 대신 반복문을 통해 순차적으로 계산하는 것이 빠름
ForkJoinPool의 주요 메서드
- invoke(ForkJoinTask<?> task): 기다리고 결과를 받음
- execute(ForkJoinTask<?> task): 작업을 비동기로 실행
- submit(ForkJoinTask<?> task): 작업을 실행하고 Future를 반환
ForkJoinPool 개발 시 RecursiveTask와 RecursiveAction의 역할
- RecursiveTask<V>:
- 반환값이 있는 병렬 작업을 정의할 때 사용
- 작업을 분할하고 결과를 합산하여 반환(compute() 메서드)
- RecursiveAction:
- 반환값이 없는 병렬 작업을 정의할 때 사용.
- 단순히 작업을 수행하고 결과를 반환하지 않는 경우 적합(compute() 메서드)
꼭 써야해?
RecursiveTask를 상속하지 않고도 직접 ForkJoinTask 또는 Runnable과 같은 인터페이스를 사용할 수 있다. 하지만 이는 더 복잡하고 비효율적이며 코드 복잡성을 증가시킨다.
ForkJoinPool
스레드 갯수를 생략하면, 기본적으로 가용한 CPU 코어 수에 따라 동작
- 스레드 수 = Runtime.getRuntime().availableProcessors()
즉, 현재 시스템의 CPU 코어 수(논리적 코어 포함)가 기본 스레드 수로 사용됨
ForkJoinPool pool = new ForkJoinPool(); //내부적으로 가용한 프로세서 수를 기반으로 스레드 풀 크기를 결정
ForkJoinPool pool = new ForkJoinPool(4); // 스레드 4개 사용예시
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.ForkJoinPool;
public class ForkJoinExample {
static class SumTask extends RecursiveTask<Integer> {
private final int[] arr;
private final int start, end;
private static final int THRESHOLD = 10;
public SumTask(int[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= THRESHOLD) {
// 작은 작업은 직접 계산
int sum = 0;
for (int i = start; i < end; i++) {
sum += arr[i];
}
return sum;
} else {
// 작업 분할
int mid = (start + end) / 2;
SumTask leftTask = new SumTask(arr, start, mid);
SumTask rightTask = new SumTask(arr, mid, end);
leftTask.fork(); // 병렬 처리
int rightResult = rightTask.compute(); // 동기 처리
int leftResult = leftTask.join(); // 병합
return leftResult + rightResult;
}
}
}
public static void main(String[] args) {
int[] arr = new int[100];
for (int i = 0; i < arr.length; i++) arr[i] = i + 1;
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(arr, 0, arr.length);
int result = pool.invoke(task);
System.out.println("Sum: " + result); // 출력: Sum: 5050
}
}1. leftTask.fork();
- 작업 분할:
- leftTask를 병렬로 처리할 수 있도록 Fork-Join Pool에 작업 큐로 제출
- fork() 메서드는 현재 작업을 Fork-Join Pool의 스레드가 처리하도록 요청하며, 비동기적으로 실행
- 이 시점에서 leftTask는 아직 결과를 계산하지 않음
2. int rightResult = rightTask.compute();
- 동기 실행:
- rightTask는 직접 현재 스레드에서 동기적으로 계산
- compute() 메서드는 RecursiveTask에서 작업을 처리하는 메인 로직
- 이렇게 함으로써 하나의 스레드가 rightTask를 바로 계산하여, 자원을 최대한 활용
3. int leftResult = leftTask.join();
- 결과 병합:
- join() 메서드는 leftTask가 완료될 때까지 대기하고 결과를 반환
- 만약 leftTask가 이미 완료되었으면, 바로 결과를 반환
- 이를 통해 leftTask와 rightTask의 결과를 병합
왜 이런 방식으로 처리?
- 자원의 효율적 활용:
- leftTask는 병렬로 실행하도록 요청 (fork())
- 한편, rightTask는 현재 스레드에서 처리 (compute())
- 이렇게 하면 다른 작업 스레드가 leftTask를 처리하는 동안, 현재 스레드가 놀지 않고 rightTask를 계산하여 자원을 최대한 활용
- 병렬성과 동기화의 조합:
- fork()로 비동기 작업을 시작하고 join()으로 결과를 기다리며 동기화.
- 병렬성과 동기화의 균형을 유지하면서 성능을 최적화
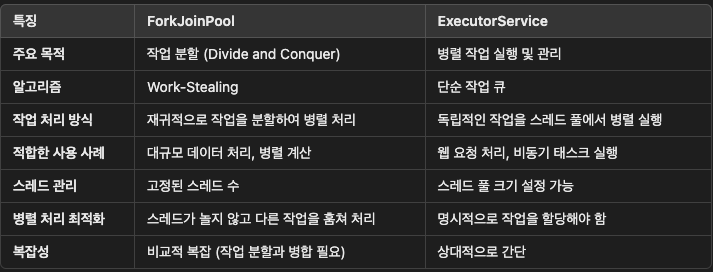
ForkJoinPool
- 특징:
- Java 7에서 도입.
- 작업 분할(divide-and-conquer)을 기반으로 병렬 처리를 수행.
- Work-Stealing 알고리즘을 사용해 작업이 끝난 스레드가 다른 스레드의 작업을 훔쳐 효율성을 높임.
- 주로 재귀적인 작업 처리나 작업 분할에 사용.
- RecursiveTask(결과 반환)와 RecursiveAction(결과 없음)을 통해 작업 정의.
- 사용 사례:
- 큰 작업을 작은 작업으로 나눠 처리하는 경우.
- 예: 대규모 데이터 처리, 배열 합산, 병렬 검색.
- 장점:
- 스레드 수를 효율적으로 관리 (스레드 풀 크기 설정 가능).
- Idle(대기) 상태인 스레드가 다른 작업을 훔쳐 병렬 처리 최적화.
- 단점:
- 작업 분할이 필요 없는 간단한 병렬 작업에는 적합하지 않을 수 있음.
- Work-Stealing 비용이 단순 작업에서는 오히려 비효율적.
ExecutorService
- 특징:
- Java 5에서 도입.
- 병렬 작업을 스레드 풀에서 실행하여 스레드 관리를 자동화.
- Java의 스레드 풀을 관리하는 인터페이스로, 스레드의 생성, 실행, 종료를 간편하게 처리.
- 개발자는 스레드 풀을 직접 관리할 필요가 없음!
- 스레드 풀이 다양한 종류로 제공:
- FixedThreadPool: 고정된 크기의 스레드 풀.
- CachedThreadPool: 동적으로 크기가 변하는 스레드 풀.
- ScheduledThreadPool: 예약 및 지연 실행 작업용.
- SingleThreadExecutor: 단일 스레드로 작업 처리.
- 사용 사례:
- 병렬 작업이 분할되지 않거나 작업 분할을 수동으로 처리해야 할 때.
- 예: 웹 서버 요청 처리, 비동기 작업 관리.
- 장점:
- API가 간단하고 다양한 스레드 풀 종류 제공.
- 반복적이고 독립적인 병렬 작업에 적합.
- 작업 분할 없이 단순 병렬 실행 가능.
- 단점:
- ForkJoinPool만큼 작업 분할에 최적화되지 않음.
- 대규모 데이터 병렬 처리에는 적합하지 않을 수 있음.
import java.util.concurrent.*;
public class ExecutorServiceExample {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//4개의 스레드로 구성된 고정 크기 풀 생성
ExecutorService executor = Executors.newFixedThreadPool(4);
Callable<Integer> task1 = () -> {
Thread.sleep(1000);
return 1;
};
Callable<Integer> task2 = () -> {
Thread.sleep(1000);
return 2;
};
Future<Integer> result1 = executor.submit(task1);
Future<Integer> result2 = executor.submit(task2);
//Future.get() 호출로 각각의 결과를 대기하고 출력
//task1과 task2는 1초 동안 대기 후 각각 1과 2를 반환
System.out.println("Result 1: " + result1.get());
System.out.println("Result 2: " + result2.get());
//스레드 풀 종료
executor.shutdown();
}
}
728x90
반응형
'개발 > java' 카테고리의 다른 글
| [함수형 프로그래밍] 일급객체, 고차함수 (0) | 2025.01.06 |
|---|---|
| [대규모, 비용 낮은] coroutine vs virtual thread (0) | 2024.12.24 |
| [동기화] 뮤텍스/세마포어 (0) | 2024.11.24 |
| DB로 분산락 구현 (2) | 2024.11.21 |
| [test] org.mockito.exceptions.misusing.PotentialStubbingProblem (1) | 2024.11.15 |