환경: java17, spring boot 3.1.5, spring batch 5.0.3, mysql5.7
이슈:
아래 에러가 간헐적으로 발생하며 배치 실패. 재실행 시 정상 처리
Caused by: com.mysql.cj.jdbc.MysqlXAException: XAER_DUPID: The XID already exists
at com.mysql.cj.jdbc.MysqlXAConnection.mapXAExceptionFromSQLException(MysqlXAConnection.java:344)
at com.mysql.cj.jdbc.MysqlXAConnection.dispatchCommand(MysqlXAConnection.java:329)
at com.mysql.cj.jdbc.MysqlXAConnection.start(MysqlXAConnection.java:290)
at com.atomikos.datasource.xa.XAResourceTransaction.resume(XAResourceTransaction.java:217)
... 81 common frames omitted
Caused by: java.sql.SQLException: XAER_DUPID: The XID already exists
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:130)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.StatementImpl.executeInternal(StatementImpl.java:763)
at com.mysql.cj.jdbc.StatementImpl.execute(StatementImpl.java:648)
at com.mysql.cj.jdbc.MysqlXAConnection.dispatchCommand(MysqlXAConnection.java:323)
디비에서 xa recover; 로 검색 시 남아있는 트랜젝션 없는 것 확인
해결:
XID 중복이라 우선 XID가 어떻게 생성되는지 확인
XID: <gtrid>:<bqual>
gtrid (Global Transaction ID): 분산 트랜잭션을 식별하는 고유한 값
bqual (Branch Qualifier): 트랜잭션 내에서 개별 브랜치를 구분하는 값
16진수 → ASCII 디코딩 제공된 XID는 16진수(Hex)로 인코딩 되어 있음. 이를 ASCII 문자로 변환해야 함
Call by Value: 인자로 전달된 변수의 값만 복사하여 사용. 원본 변수에는 영향을 주지 않는다.
Call by Reference: 인자로 전달된 변수의 메모리 주소(참조값, reference)를 전달. 함수 내에서 값이 변경되면 원본 변수에도 영향을 미친다.
자바는 Call by Value
자바의 메서드 호출 방식은 항상 Call by Value다. 즉, 메서드가 인자를 받을 때 원본 변수의 값을 복사하여 전달한다.
기본 타입 (Primitive Type)
기본 타입(예: int, double, char 등)은 Call by Value로 동작하여 원본 변수에 영향을 주지 않는다.
참조 타입 (Reference Type)
객체(Object)와 같은 참조 타입의 경우, 객체의 참조값(메모리 주소)이 값으로 전달된다. 따라서 참조하는 객체의 속성을 변경하면 원본 객체에도 영향을 준다. 하지만 참조 자체를 변경해도(새로운 객체를 할당하면) 원본에는 영향을 주지 않는다.
classPerson{
String name;
}
publicclassExample{
publicstaticvoidchangePerson(Person p){
p = new Person(); // 새로운 객체를 할당
p.name = "Charlie";
}
publicstaticvoidmain(String[] args){
Person person = new Person();
person.name = "Bob";
changePerson(person);
System.out.println(person.name); // 여전히 Bob (새로운 객체는 원본에 영향을 주지 않음)
}
}
changePerson 함수 안에서 p가 새로운 객체를 가리키도록 변경되었지만, 이것은 메서드 내부의 p 변수가 가리키는 참조가 바뀐 것일 뿐, 원래 person 변수에는 영향을 주지 않는다. 만약 메서드 내부에서 새로운 객체를 만들어 원본에도 반영하고 싶다면, 리턴 값을 활용하여 원본 변수를 직접 변경해야 한다.
publicstatic Person changePerson(Person p){
returnnew Person("New Person");
}
publicstaticvoidmain(String[] args){
Person person = new Person("Original");
person = changePerson(person); // 리턴 값을 원본 변수에 할당
System.out.println(person.name); // "New Person"
}
객체의 참조값(메모리 주소)을 복사하여 전달하기 때문에, 객체 내부 값은 변경할 수 있지만, 객체 자체를 변경할 수는 없다.
SimpleDateFormat은 내부적으로 Calendar 인스턴스를 공유하는데, 이 과정에서 공유 자원 변경이 발생하여 멀티스레드 환경에서 예상치 못한 결과를 초래할 수 있다. SimpleDateFormat은 멀티스레드 환경에서 사용할 경우 각 스레드마다 별도 인스턴스를 생성하거나 ThreadLocal을 이용해야 한다.
Java 8부터는 DateTimeFormatter가 제공되며, 이는 불변(immutable) 객체이므로 여러 스레드에서 동시에 안전하게 사용할 수 있다. 따라서 매번 새로 생성할 필요 없이, 재사용하는 것이 성능적으로도 더 유리하다.
index: 인덱스 전용 스캔(Index scan)이 사용된 경우 (테이블 데이터 대신 인덱스만 읽음)
ALL: 전체 테이블 스캔(Full Table scan)이 발생한 경우 (최악의 경우)
ref
참조 조건으로 특정 값을 기준으로 검색
주로 복합 인덱스의 일부를 활용하거나 WHERE 조건의 =, 또는 연산자 IN을 활용
인덱스를 활용하여 특정 값에 대한 행을 검색할 때 주로 출력됩니다.
index
인덱스 전체를 순차적으로 스캔하는 Index Full Scan을 뜻합니다.
Table Full Scan은 테이블 전체를 읽는 것을 뜻하지만, Index Full Scan은 설정된 인덱스 전체를 스캔하는 것을 뜻합니다.
즉, 복합 인덱스의에서는 복합 인덱스에 선언된 모든 컬럼을 순서대로 풀 스캔을 하는 것을 뜻합니다.
extra
(제일 빠름) Using index -> Using where; Using index -> Using index condition -> Null (제일 느림)
Using Index: covering index 사용하여 테이블 데이터를 읽지 않고 인덱스만으로 쿼리 결과를 만족하는 경우
Using where: 인덱스를 사용하여 데이터 접근은 하지만, WHERE 절의 조건 중 일부가 인덱스에 포함되지 않아서 서버에서 추가로 조건 검사를 수행해야 하는 경우. 즉, 인덱스 스캔 후에 반환된 결과에 대해 WHERE 조건을 한 번 더 필터링
Using index condition: 인덱스 컨디션 푸쉬다운 (ICP) 과 관련 있음. 인덱스 스캔 시 인덱스에 포함된 컬럼에 대해 일부 조건을 미리 평가하는데 인덱스만으로 조건을 완전히 만족하지 못하는 경우(예: 인덱스에 포함되지 않은 컬럼의 조건이 있을 때) 실제 테이블 데이터에 접근하여 조건을 최종 확인하게 됨
NULL: 인덱스는 사용하지만, 추가적인 extra 메시지가 표시되지 않는 경우로, 일반적으로 인덱스 스캔 후에도 테이블 데이터에 접근하는 경우, 인덱스 스캔 후 추가로 테이블 조회가 발생하기 때문에 디스크 I/O가 늘어나고, 전체 쿼리 실행 속도가 저하됨
Using temporary: 쿼리 실행 중 임시 테이블이 생성되었음 (ORDER BY나 GROUP BY 등에서 사용)
Using filesort: 인덱스가 아니라 별도의 정렬 알고리즘을 사용하여 정렬했음
Using join buffer: 조인 시 버퍼를 사용한 조인 전략이 사용됨
Using where; Using index 순서?
직관적으로는 인덱스를 먼저 타고 그 후에 WHERE 조건을 적용하므로 "Using index; Using where" 순서가 자연스러워 보이지만, 실제 EXPLAIN의 extra 컬럼에 나타나는 메시지 순서는 반드시 실행 순서를 그대로 반영하지 않는다. 즉, 출력되는 순서는 내부 구현이나 옵티마이저가 수집한 여러 플래그를 특정 순서로 나열한 결과일 뿐, 실제 동작은 인덱스를 사용한 후 WHERE 조건으로 최종 결과를 필터링하는 방식이다. 표시되는 순서는 내부 구현에 따른 것이며, 성능이나 처리 순서를 해석하는 데 큰 영향을 주지 않는다.
인덱스 조건 푸시다운 (ICP)
MySQL 5.6이상 버전부터 도입됐으며, 복합 인덱스의 일부 조건이 충족되면 나머지 조건을 인덱스 스캔 중에 필터링 할 수 있다.
즉, WHERE 조건의 일부 또는 전부를 인덱스에서 먼저 처리한 다음, 필요할 경우 데이터 테이블에 접근한다.
이를 통해 불필요한 디스크 I/O를 줄일 수 있다.
참고
인덱스를 사용하더라도 인덱스의 카디널리티가 낮은 경우, 옵티마이저는 인덱스를 타지 않고 Full Table Scan을 선택할 수 있음
MySQL 옵티마이저는 쿼리의 WHERE 조건을 분석하여 복합 인덱스의 순서에 맞게 조건을 재배열 할 수 있음
복합 인덱스의 첫 번째 컬럼을 타지 않는 상황이더라도, 옵티마이저는 커버링 인덱스를 통해 테이블 풀 스캔이 아닌 인덱스 풀 스캔을 채택해 테이블까지는 접근하지 않고 인덱스의 필터링을 통해서 데이터를 가져올 수 있음
로드밸런서: restful api서버, 양뱡향 유상태 ws서버 앞단에서 부하를 고르게 분산
restful api 서버: 무상태, 친구 추가/삭제, 사용자 갱신 등
ws 서버: 친구 위치 정보 전송, 커넥션 유지
기존 서버 제거 시 기존 연결을 종료하고 진행(LB에서 상태를 연결 종료 중으로 변경)
레디스 위치 정보 캐시: 최근 위치 캐시, ttl 설정 필요(갱신 혹은 비활성화)
사용자 아이디 - 위도/경도/시각 json
영속성 보장 필요 없음
메모리는 괜찮은데 QPS 감당하려면 캐시서버 샤딩 필요
HA를 위해 복제
사용자 디비: 친구 관계 정보 저장(RDB, nosql)
사용자 상세정보; 친구 관계 데이터
RDB사용 시 사용자 아이디 기준으로 샤딩
디비 직접 직의하지 말고 API 서버 호출
위치 이동 이력 디비: 사용자의 위치 변동 이력
사용자 아이디, 위도, 경도, 타임스탬프
막대한 쓰기 연산 부하를 감당하며 수평적 규모 확장 가능한 디비: 카산드라
RDB사용할 경우 사용자 아이디를 기반으로 샤딩 필요..
레디스 펍/섭(메세지 버스): 채널(토픽)만드는 비용이 저렴; 위치 변경 메시지의 라우팅 계층
사용자의 위치가 변경되면 변경 이벤트를 발행하고 친구들이 구독하여 모든 친구의 웹소켓 연결 핸들러가 호출됨. 이벤트를 기반으로 검색 반경 등 계산 후 조건을 만족하면 친구의 앱으로 전송
채널을 유지하기 위해 구독자 관계를 추적하기 위한 해시 테이블과 연결 리스트가 필요한데 아주 소량의 메모리를 사용한다.
오프라인 사용자라 어떤 변경도 없는 채널의 경우 생성된 이후에 CPU자원은 전혀 사용하지 않는다.
주변 친구 기능을 이용하는 모든 사용자에게 채널 하나씩 부여
사용자는 초기화 시 친구 상태 상관없이 모든 친구와 구독 관계 설정
병목은 메모리가 아니라 CPU사용량
분산 레디스 펍섭 클러스터
service discovery사용
해시 링에 활성화된 레디스 서버 보관
주기적 위치 갱신
위치 변경 사실을 LB에 전송
LB는 변경 내역을 이미 연결을 유지하고 있는 ws로 보냄
ws는 해당 이벤트를 위치 이동 이력 디비에 저장
ws는 새 위치를 캐시에 보관, ttl 갱신
레디스 내의 해당 사용자 전용 채널에 새 위치를 발행, 3~5의 과정은 병렬로 진행
발행된 새 이벤트는 모든 구독자에게 브로드캐스드
받은 친구의 웹소켓 핸들러는 새 위치와 친구의 위치 사이 거리를 새로 계산한다. 검색 반경 내에 있다면 갱신 시각을 타임스탬프를 앱으로 전송하고 아니면 보내지 않는다.
Redis Pub/Sub(Publish-Subscribe)
Redis Pub/Sub은 실시간 메시징을 위한 Redis의 기능입니다. **발행자(Publisher)**가 메시지를 특정 채널에 발행하면, 해당 채널을 구독(Subscriber) 중인 모든 클라이언트에게 메시지가 전달됩니다.
작동 방식
채널 생성 및 구독: 구독자는 하나 이상의 채널에 구독 요청을 보냅니다.
메시지 발행: 발행자는 특정 채널에 메시지를 보냅니다.
메시지 전달: Redis는 메시지를 해당 채널에 구독 중인 모든 구독자에게 즉시 전송합니다.
Pub/Sub 특징
실시간 메시징: Redis는 메시지를 즉시 구독자에게 전달합니다.
단순 구조: 메시지를 직접 큐에 저장하지 않고 바로 전송합니다.
비동기 통신: 발행자는 구독자의 상태를 신경 쓸 필요가 없습니다.
패턴 구독 지원: 특정 패턴에 맞는 채널 이름을 구독할 수 있습니다.
제약 사항
메시지 내구성 없음: 메시지는 발행 시점에 구독자가 없으면 소멸됩니다.
확장성 제한: 수많은 구독자가 있는 경우 성능 저하 가능성
수평 확장 어려움(클러스터 모드에서 제한적)
Redis Pub/Sub 특징
메시지 휘발성: 구독자가 없으면 메시지는 즉시 소멸합니다.
빠른 실시간 통신: 짧은 수명의 이벤트나 알림에 적합합니다.
단순한 구조로 설정과 사용이 쉽습니다.
단점: 내구성 부족, 대규모 확장에 한계가 있음.
Kafka 특징
내구성 보장: 메시지를 디스크에 저장하여 장애 복구가 가능합니다.
확장성: 클러스터링으로 대량 데이터 처리가 가능합니다.
높은 안정성: 정확히 한 번 처리(Exactly Once Processing) 모델 지원.
적용 분야: 대규모 데이터 스트리밍, 로그 수집, 이벤트 중심 아키텍처에 적합.
해시 링(Hash Ring)
1. 개념
일관성 해싱을 원형(topology) 구조로 시각화한 표현입니다. 해시 값을 0에서 최대값까지 원형 형태로 배치하고 노드와 데이터 키를 이 링 위에 매핑합니다. 해시 링(Hash Ring)은 데이터 분산 및 노드 추가/제거를 효율적으로 관리하기 위해 사용되는 분산 시스템 기법입니다. 데이터 노드를 원형(ring) 형태로 배치하고, 해싱을 통해 데이터를 특정 노드에 매핑합니다.
2. 동작 방식
모든 노드와 데이터 키에 대해 동일한 해시 함수(예: SHA-1)를 사용하여 해시 값을 계산합니다.
해시 값은 0부터 최대 값까지 이어지는 원형 공간(Ring) 상에 매핑됩니다.
데이터의 해시 값에 가장 가까운 시계 방향 노드가 해당 데이터를 담당합니다.
3. 해시 링의 특징
확장성: 노드를 추가하거나 제거할 때 전체 데이터 재배치 비용이 최소화됩니다.
부하 분산: 데이터가 노드에 고르게 분산됩니다.
내결함성: 특정 노드 장애 발생 시 데이터를 인접 노드로 쉽게 재분배합니다.
4. 장점
노드 추가/제거에 따른 재배치 비용 감소 기존 해싱 방식에서는 노드를 추가하면 모든 데이터의 재분배가 필요하지만, 해시 링에서는 평균적으로 전체 데이터의 1/n만 재분배됩니다.
노드 장애 시 데이터 손실 최소화 특정 노드가 장애가 나더라도 인접 노드가 데이터를 처리하므로 손실이 줄어듭니다.
사용 사례
분산 캐시 시스템:
Redis Cluster
Memcached
분산 데이터 저장소:
Amazon DynamoDB
Apache Cassandra
분산 메시지 큐
Kafka 파티션 데이터 분배
Consistent Hashing (일관성 해싱)
Consistent Hashing은 분산 시스템에서 데이터 분배와 부하 분산을 효율적으로 관리하기 위해 사용되는 해싱 기법입니다. 노드 추가/삭제 시 전체 데이터가 아닌 일부 데이터만 재배치되도록 하여 성능을 개선합니다.
작동 원리
해시 공간의 원형 구조 (Hash Ring)
해시 값이 0부터 최대값까지 연결된 원형 링 형태의 해시 공간을 형성합니다.
노드와 키의 매핑
각 노드(서버)는 해시 함수에 의해 링의 특정 위치에 할당됩니다.
각 데이터 키도 같은 해시 함수로 링 상에 위치합니다.
특정 키는 해시 링에서 **가장 가까운 노드(시계 방향)**에 할당됩니다.
노드 추가/삭제
기존 분배된 대부분의 키는 유지되며, 소수의 키만 재배치되므로 효율적입니다.
분산 레디스 펍섭 서버 클러스터
웹소켓 서버는 해시 링을 참조하여 메시지를 발행할 레디스 서버를 선정
웹소켓 서버는 해당 서버가 관리하는 사용자 채널에 위치 정보 변경 내역을 발행
레디스 펍섭서버는 각 채널의 구독자 목록을 들고 있기 때문에 유상태 서버. 제거 시 채널을 다른 서버로 옮기고 모든 구독자들에게 알려줘야 한다. 보통 유상태 서버 클러스터 규모를 늘리거나 줄이는 것은 큰 운영 부담으로 보통은 여유를 두고 오버 프로비저닝한다.
펍섭서버를 늘리면 대규모 채널 재조정(재구독)이 일어나기 때문에 CPU부하가 올라간다.
기존 서버를 교체하는 것은 채널 재조정 작업이 없기에 더 안전하다.. 교체하면 교체사실은 웹소켓 서버에게 통지되고 새 펍섭서버의 채널을 다시 구독하도록 알린다.
친구 추가 삭제 시: 친구의 펍섭 채널을 구독하거나 구독 취소한다.
친구가 많은 사용자? 친구에 상한선이 있고(5000명) 많은 웹소켓 서버에 분산되어 있으니 핫스팟 문제는 발생하지 않을 것..
주변의 임의의 사용자? 지오 해시별로 펍섭채널을 두어 사용자의 위치가 변경되면 지오해시 아이디를 계산한 후 해당 지오해시 아이디를 담당하는 채널에 새 위치를 전송한다. 근방에 있는 사용자 중 해당 채널을 구독하는 사용자2는 사용자의 위치가 변경되었다는 메시지를 수신한다.
얼랭으로 확장
웹소켓 서비스는 얼랭으로 구현하고 레디스 펍섭클러스터는 아예 분산 얼랭 애플리케이션으로 대체. 이 애플리케이션에서 각 사용자는 얼랭 프로세스로 표현. 이 사용자 프로세스는 클라이언트가 전송하는 갱신된 사용자 위치를 웹소켓 서버를 통해 수신. 또한 친구의 얼랭 프로세스와 구독 관계를 설정하고 변경 내역을 수신한다..
Erlang이란? 분산이 쉽고 경랑이라서 천만명의 활성 사용자 처리 굿,,
Erlang은 동시성(concurrency), 분산 시스템(distributed systems), 고가용성(high availability)을 위해 설계된 함수형 프로그래밍 언어이자 런타임 환경. 원래 스웨덴의 통신 회사 Ericsson에서 1986년에 통신 장비를 개발하기 위해 만들어졌으며, OTP(Open Telecom Platform)이라는 프레임워크와 함께 강력한 분산 시스템을 쉽게 구축할 수 있도록 지원
Erlang의 주요 특징
1. 동시성 (Concurrency)
수천만 개의 경량 프로세스(lightweight processes)를 동시에 관리
프로세스 간 비동기 메시지 전달 기반 아키텍처
Actor Model 기반으로 상태 공유 없이 독립된 프로세스 실행
Actor Model은 동시성(concurrency) 프로그래밍을 위한 추상화 모델입니다. 이 모델에서는 Actor(액터)가 기본 단위로 동작하며, 서로 독립적으로 실행되고 비동기 메시지 전달을 통해 통신합니다.
지도 확대/축소: 사이즈 별로 타일 준비해서 붙여서 보여줌. 완전 줌아웃된 건 지도 한 장으로 가능(이미지)
확대 수준이 증가함에 따라 4장씩 사진이 더 필요하다고 하면 0~21확대 수준까지 대략 440PB만큼 필요한데.. 인간이 살지 않는 지구의 90% 지역은 압축을 할 수 있으므로 지도이미지에 대략 50PB가 필요하다. 추가정보까지 하면 약 100PB가 필요하다.
경로 안내 알고리즘: 교차로를 노드; 도로는 선. 성능은 그래프의 크기에 민감하기 때문에 세계를 작은 격자로 나누고 각 격자 안의 도로망을 노드와 선으로 구성된 그래프 자료구조로 변환한다. 이 때 각 격자는 routing tile이라고 부른다. 각 타일은 도로로 연결된 다른 타일에 대한 참조를 가지고 있다. 이렇게 타일로 분할해 놓으면 메모리 요구량을 낮출 수 있고 한 번에 처리하는 경로의 양이 줄어 성능이 좋아진다.
routing tile은 구체성에 따라 상/중/하로 나누어 준비
위치 서비스
사용자의 위치를 기록
사용자가 주기적으로 위치 정보를 전송
해당 데이터 스트림을 활용하여 시스템을 개선, 실시간 교통 모니터링, 새로만들어진 도로, 폐쇄된 도로 탐지 가능
위치정보가 실시간에 가까우므로 ETA를 더 정확하게 산출할 수 있고 교통상황에 따라 다른 길을 안내할 수 있다.
위치 갱신의 경우 1초마다 서버로 현재 좌표를 보낼수도 있지만 이 요청을 클라이언트에서 모았다가 15초마다 한 번씩 보내 쓰기 QPS를 낮춘다. 몇 초마다 갱신하는지는 사용자의 현재 상태에 따라 달라진다.
쓰기에 최적화되고 규모 확장이 용이한 카산드라와 같은 디비가 필요
사용자 위치는 계속 변화하기 때문에 일관성보다는 가용성이 더 중요
CAP 정리: 가용성과 분할 내성 두 가지 만족시키도록
카프카와 같은 스트림 처리 엔친으로 위치 데이터를 로깅하는 게 좋다
프로토콜은 http keep alive로
데이터: 유저아이디(파티션 키), 타임스탬프(컬러스터링 키), 위도, 경도, 사용자 모드
지도 표시
현재 위치와 인접한 지도 타일을(지오 해싱 기반) url로 준비해 두고 CDN으로 제공
맵 타일 인코딩(지오 해싱)이 바뀌거나 할 때를 대비하여
위/경도 확대 수준을 던지면(새로운 위치로 이동하거나 확대 수준을 변경하면) 필요한 타일들을 결정하여 타일 url을 생성하는 서비스를 별도로 두어 운영 유연성을 높일 수도 있다. 표시할 1개의 타일과 주변 8개의 타일이 포함된다.
최적화 필요 시 벡터 사용; webGL 자바스크립트 사용
경로 안내 서비스
지오코딩 서비스: 주소 -> 위도/경도로 표현
경로 계획 서비스: 최적화 된 경로 제안
최단 경로 서비스: 출발지/목적지 위도/경도받아서 k개의 경로 반환; 교통이나 도로 상황 고려하지 않고 도로 구조에만 의존하여 계산
출발지 타일부터 시작하여 그래프 자료 구조를 탐색해 나가면서 주변 타일을 저장소에서 가져와 연결하여 그래프를 탐색한다.
예상 도착 시간(ETA) 서비스: 위 결과에 대해 각 경로에 대한 소요 시간 추정치를 구한다. 머신러닝 활용하여 현재/과거 이력에 근거하여 예상 도착 시간을 계산한다. 미래 예측에 대한 것은 알고리즘 차원에서 풀어야 한다.
순위 결정 서비스: ETA를 구한 후 사용자가 정의한 필터링 조건(무료도로, 고속도로 제외 등)을 적용, 소요시간 순으로 정렬하여 top k 개를 구한 후 반환
위 서비스들은 카프카 위치 데이터 스트림을 구독하고 있다가 비동기로 데이터를 업데이트하여 그 상태를 항상 최신으로 유지한다.
적응형 ETA 경로 변경: 활성화 사태 유저의 위치 데이터 스트림에서 상황정보를 추출하여 실시간 교통상황에 반영; 이용가능한 경로의 ETA를 주기적으로 재계산하여 더 짧은 ETA를 갖는 경로가 발견되면 알림
전송 프로토콜: 롱폴링, 웹소켓, SSE 가능하나 양방향 통신이 필요한 경우도 있어 웹소켓 사용
1. 롱폴링 (Long Polling)
동작 방식
요청-응답 사이클:
클라이언트가 서버에 HTTP 요청을 보냅니다.
서버는 즉시 응답하지 않고, 새로운 데이터가 발생할 때까지 연결을 열어둡니다.
데이터가 준비되면 응답을 보내고, 클라이언트는 응답을 수신한 후 즉시 다음 요청을 보내는 식으로 주기적으로 연결을 갱신합니다.
주요 특징
비동기/동기 구현 가능:
기본 HTTP 요청-응답 메커니즘을 사용하므로, 서버와 클라이언트 모두 블로킹 I/O 방식으로 구현할 수 있지만, 비동기 방식으로도 구현이 가능합니다.
지속 연결 유지:
각 요청이 데이터가 도착할 때까지 장시간 열려 있으므로, 풀이나 스레드가 해당 연결에 묶입니다.
단점:
매번 새로운 요청을 보내야 하기 때문에 HTTP 헤더 등 오버헤드가 발생합니다.
많은 클라이언트가 동시에 접속할 경우 서버의 커넥션/스레드 리소스가 빠르게 소진될 수 있습니다.
사용 사례
간단한 실시간 알림이나 업데이트가 필요한 경우
서버에서 데이터가 불규칙하게 발생할 때
2. 웹소켓 (WebSocket)
동작 방식
초기 핸드셰이크:
클라이언트가 HTTP 업그레이드 요청을 보내고, 서버가 이를 승인하면 HTTP 연결이 웹소켓 프로토콜로 전환됩니다. ws://
전이중 통신:
연결이 성립된 후, 클라이언트와 서버는 서로 자유롭게 데이터를 주고받을 수 있습니다.
한 번 연결이 만들어지면, 양방향 통신을 위해 지속적으로 연결을 유지합니다.
주요 특징
양방향 통신(Full-Duplex):
클라이언트와 서버 모두 언제든지 데이터를 전송할 수 있어 채팅, 실시간 게임, 협업 도구 등에 적합합니다.
낮은 오버헤드:
초기 연결 설정 후에는 별도의 HTTP 요청/응답 없이 데이터 프레임만 주고받으므로, 반복적인 헤더 전송이 없습니다.
리소스 관리:
비동기 I/O (예: Netty, Undertow 등)를 사용하면, 한정된 스레드로도 많은 연결을 효과적으로 처리할 수 있습니다.
단점:
서버와 클라이언트 모두 웹소켓 프로토콜을 지원해야 하며, 방화벽이나 프록시 환경에서 제약이 있을 수 있습니다.
초기 설정이 다소 복잡할 수 있습니다.
사용 사례
실시간 채팅, 게임, 협업 툴 등 양방향 데이터 교환이 필요한 애플리케이션
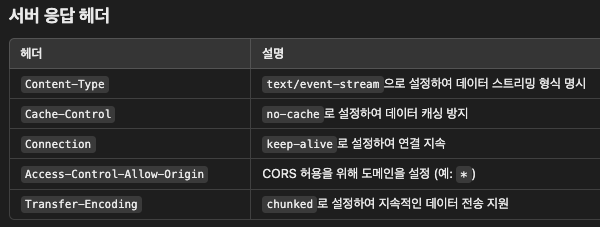
3. 서버 전송 이벤트 (SSE, Server-Sent Events)
동작 방식
단방향 스트리밍:
클라이언트가 HTTP 요청을 보내고, 서버는 해당 연결을 통해 이벤트(텍스트 기반 데이터)를 지속적으로 스트리밍합니다.
연결은 단방향으로 유지되며, 서버 → 클라이언트로 데이터만 전송합니다.
Last-Event-ID 헤더와 id 필드를 활용하여 중단된 연결 복구가 가능합니다.
SSE는 텍스트 기반 프로토콜이므로 이진 데이터 전송이 필요한 경우 Base64로 인코딩하거나 WebSocket 사용을 고려해야 합니다.
자동 재연결:
연결이 끊어질 경우 클라이언트 측에서 자동으로 재연결을 시도하는 기능이 내장되어 있습니다.
주요 특징
단방향 통신:
클라이언트에서 서버로 데이터를 보내려면 별도의 요청(예: AJAX)이 필요합니다.
구현 단순성:
HTTP 기반이므로 기존 인프라와 호환성이 좋고 구현이 비교적 간단합니다.
리소스 효율성:
비동기 HTTP 클라이언트(예: Spring WebFlux의 WebClient, EventSource 등)를 사용하면 많은 연결을 효율적으로 관리할 수 있습니다.
단점:
양방향 통신이 불가능하므로, 서버에서 클라이언트로만 데이터를 보내야 하는 경우에 한정됩니다.
일부 브라우저(특히 오래된 버전)에서 지원이 제한적일 수 있습니다.
사용 사례
실시간 뉴스 업데이트, 주식 가격 모니터링, 알림 시스템 등 서버 → 클라이언트 단방향 데이터 스트리밍