Member member = memberService.saveMember(snsType, token);
member.setSnsType("kakao"); /////<<<<<<<-- 여기서 실수하면 반영됨 상하로 트랜잭션이 있어서
memberService.emptyLogic();
=> dto 리턴 시 해결!
싱글톤 패턴
한 클래스마다 인스턴스를 하나만 생성하여 어디서든 참조
병렬로 여러 스레드에서 돌릴 경우 조심
직접 구현할 일 적음(스프링 빈)
장점
새로운 인스턴스를 계속해서 생성하지 않으므로 메모리 낭비가 적음
단점
코드량 많고, 테스트 어렵고, 자식 클래스 만들기 어렵, 클라이언트가 구체 클래스에 의존(dip 위반)
스프링이 모두 해결해 줌!
public class SingletonService {
private static final SingletonService instance = new SingletonService();
public static SingletonService getInstance() {
return instance;
}
// 생성자를 private으로 적용시켜 외부에서 인스턴스 생성을 막는다
private SingletonService() {
}
}
구조 패턴
클래스나 객체를 조합하여 더 큰 구조를 만들 수 있게 해줌
어댑터 패턴
타사의 라이브러리를 호출부의 변경 없이 사용하고 싶을 경우
Array.AsList(), Collections.enumeration(), Collections.list() 등도 어댑터 패턴을 활용한 예시
@Service
@Primary //얘랑 동일한 빈이 있어도 이게 우선이다라고 해줘야(override)
public class MailAdapter implements MailSenderA {
private final MailSolutionB mailSolutionB;
@Override
public void send(MailSolutionA.MailParam mailParam) {
MailSolutionB.MailParam param = MailSolutionB.MailParam.builder().mailTitle(mailParam.getTitle())
.mailBody(mailParam.getBody()).receiverEmail(mailParam.getEmail()).build();
mailSolutionB.sendApi(param);
}
}
위 처럼 A -> B로 바꿀 때, 기존 호출부를 그대로 두고
A를 쏘는 것 처럼 보이지만 사실 B로 쏘는 것
Interface를 써야 구현체를 교체할 수 있음 그래야 primary로 오버라이딩이 가능
모든 부분을 다 고치지 않고 한 곳만 고칠 때 좋음
브릿지 패턴
기능의 구현 클래스를 런타임 때 자유롭게 지정이 가능
주입을 set을 이용하여 동적으로 받음
기능과 구현을 분리하여 구현이 변경되더라도 기능 클래스 부분에 대한 변경은 필요 없음
if (StringUtils.isNotEmpty(member.getAccountNumber())) {
paymentService.setPaymentMethod(new CardMethodService()); // <<-- 서비스 주입을 런타임에
} else if (StringUtils.isNotEmpty(member.getPhoneNumber())) {
paymentService.setPaymentMethod(new PhoneMethodService());
}
paymentService.pay1(order.getAmount(), member);
컴포지트 패턴
일반적으로 직접 구현하지 않음
클라이언트 전체와 부분을 구별하지 않고 동일한 인터페이스로 사용
트리구조와 상당히 유사한 성격을 가지고 있다
하지만 기능이 너무 다른 클래스들에는 공통 인터페이스를 제공하기 어려움
데코레이터 패턴
일반적으로 직접 구현하지 않음
기존 코드를 수정하지 않고도 행동을 확장 가능
객체를 여러 데코레이터로 래핑하여 여러 행동들을 합성 가능
데코레이터를 너무 많이사용하면 코드가 필요 이상으로 복잡해짐
file, buffered reader 등등 New로 만들어서 래핑해서 합성하는 것
퍼사드 패턴
복잡한 로직들을 숨기고 간단한 인터페이스 함수만을 호출(추상화)
우리는 이미 MVC패턴을 통해서 퍼사드 패턴을 알게 모르게 사용하고 있다.
플라이웨이트 패턴
일반적으로 직접 구현하지 않음
인스턴스가 필요할 때마나 매번 생성하는게 아니라 가능한 공유해서 메모리를 절약
캐시, 레디스.. 디비 접근 최소화
String 객체를 생성하는 리터럴 방식의 String Constant Pool이 대표적인 플라이웨이트 패턴을 적용한 예시
@Test
void 스트링_플라이웨이트패턴_테스트() {
String str1 = "Hello";
String str2 = "Hello";
String str3 = new String("Hello");
// 서로 같다!
Assertions.assertSame(str1, str2);
// 서로 다르다!
Assertions.assertNotSame(str1, str3);
// 서로 같다!
Assertions.assertSame(str1, str3.intern());
/*
클래스가 JVM에 로드되면 모든 리터럴은 constant pool에 위치하게 된다.
그리고 리터럴을 통해 같은 문자를 생성한다면 풀 안의 같은 상수를 참조하게 되는데 이를 String interning이라고 한다.
String을 리터럴로 생성될 때 intern()이라는 메서드가 호출되고 이 intern() 메서드는
constant pool에 같은 문자가 존재하는지 확인 후 존재한다면 그 참조 값을 가지게 된다.
*/
}
@Test
void Integer_플라이웨이트패턴_테스트() {
Integer integer1 = Integer.valueOf("123");
Integer integer2 = Integer.valueOf("123");
// 서로 같다!
Assertions.assertSame(integer1, integer2);
Integer integer3 = Integer.valueOf("128");
Integer integer4 = Integer.valueOf("128");
// 서로 다르다!
Assertions.assertNotSame(integer3, integer4);
//직접 Integer.valueOf 함수 까보기!
//-128 ~ 127 까지는 캐싱이라 같고 그 이외 값은 캐싱안하고 새롭게 인스턴스 생성이라 다름
}
프록시 패턴
SRP와 연관
공통되는 로직 빼서 모듈화
AOP(aspect oriented programming; cglib etc..)
OOP로 독립적으로 분리하기 어려운 부가 기능을 모듈화 하는 방식
oop를 더 oop스럽게 해주는 방법
객체지향을 더 객체지향스럽게 만들어 주는 프로그래밍
transactional, cache, test에 사용하는..
spring 큰 특징 : DI, AOP(aspect), PSA(portable service abstraction)
import com.example.pattern.order.service.OrderService;
import org.springframework.cglib.proxy.Enhancer;
import org.springframework.cglib.proxy.MethodInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.objenesis.SpringObjenesis;
@Configuration
public class ProxyConfig {
private final SpringObjenesis objenesis = new SpringObjenesis();
@Bean
@Primary //order service말고 프락시를 빈으로 등록하도록 해야 aop 적용
public OrderService orderServiceProxy() {
return (OrderService) createCGLibProxy(OrderService.class, new MethodCallLogInterceptor());
}
private Object createCGLibProxy(Class<? extends Object> targetClass, MethodInterceptor interceptor) {
// Create the proxy
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(targetClass);
enhancer.setCallback(interceptor);
return enhancer.create();
}
}
행동 패턴
반복적으로 사용되는 객체들의 커뮤니케이션을 패턴화, 결합도를 최소화 하는 것이 목적
책임 연쇄 패턴
스프링 필터 사용(필터 체인)
검증 절차는 자유롭게 추가될 수 있어야 하고, 순서도 자유롭게 변경할 수 있어야 할 때
기존 클라이언트 코드를 수정하지 않고 앱에 새 핸들러를 도입 가능
@Configuration
public class FilterConfig {
// @Bean
// @Order(0)
public FilterRegistrationBean userAgentCheckFilter() {
FilterRegistrationBean registrationBean = new FilterRegistrationBean(new UserAgentCheckFilter());
registrationBean.addUrlPatterns("/orders/*");
return registrationBean;
}
// @Bean
// @Order(1)
public FilterRegistrationBean memberCheckFilter() {
FilterRegistrationBean registrationBean = new FilterRegistrationBean(new MemberCheckFilter());
registrationBean.addUrlPatterns("/orders/*");
return registrationBean;
}
}
커맨드 패턴
잘 사용하지 않음
기존 클라이언트 코드를 수정하지 않고 새로운 커맨드들을 도입 가능
요청부와 동작부를 분리시켜 주기 때문에 결합도를 낮출 수 있음
보통 비동기
@Test
void 혜택_발송_스레드_테스트() throws InterruptedException {
int numberOfThreads = 5;
CountDownLatch latch = new CountDownLatch(numberOfThreads);
//ExecutorService 객체가 Invoker를 의미
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
//Runnable 구현 객체가 Command를 의미;
// runnable interface 특징? 구현할 함수가 1개, callable과 디르게 반환타입이 없음
//CouponApiService 객체가 Receiver를 의미
Runnable doThread = new CouponService(new CouponApiService());
//위 대신 lambda로 대체가능
executorService.execute(() -> {
doThread.run();
latch.countDown();
});
}
latch.await();
}
Runnable -> void
Callable -> return 있음
반복자 패턴
잘 사용하지 않음
혜택이 아이템을 어떻게 구현하였는지 호출하는 쪽에서는 알 필요가 없음
즉 캡슐화가 잘 되어 있음
내부 구현을 외부로 노출시키지 않으면서도 모든 항목에 접근 가능
적용 시 덜 효율적이거나 과도하지는 않은지 확인
옵저버 패턴
한 객체의 상태가 변경되어 다른 객체들을 변경해야 할 필요성이 생겼을 때 사용(Pub/Sub 패턴이라고도 함)
message push, pull 하는 방식을 통해 결합도를 낮출 수/없앨 수 있음
rabbitMQ, kafka 등
느슨한 결합으로 객체간의 의존성 제거
너무 많이 사용하게 되면 상태 관리가 힘듦
private final ApplicationEventPublisher eventPublisher;
//함수 내부에서 호출 publish
eventPublisher.publishEvent(new OrderEvent(order.getId(), OrderType.CREATE));
//
import com.example.pattern.order.model.OrderEvent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.event.EventListener;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;
@Component
@Slf4j
@Async
public class OrderListener {
@EventListener
public void onApplicationEvent(OrderEvent event) {
log.info("주문이벤트 Published [orderId : {}, orderType : {}]", event.getOrderId(), event.getOrderType().toString());
log.info("이후 리뷰 알림 발송이 시작됩니다.");
log.info("이후 정산 API 호출이 시작됩니다.");
}
}
중재자 패턴
옵저버 패턴
1개의 publish에 대해 N개의 subcriber가 존재하고, observer가 pulling 이나 push방식을 통해 관리
중재자 패턴
M개의 publisher와 N개의 subcriber 사이에서 1개의 mediator를 통해 통신
메멘토 패턴
상태정보 저장 관련 메모리에 들고 있을 일 없음; 잘 사용하지 않음
캡슐화를 위반하지 않고 객체의 state 스냅샷을 생성할 수 있음
메멘토를 너무 자주 생성하면 많은 Ram을 소모할 수 있음
상태 패턴
잘 사용하지 않음
전략 패턴
하나의 메시지와 책임을 정의하고 이를 수행할 수 있는 다양한 전략을 만든 후, 다형성을 통해 전략을 선택해 구현을 실행
유사한 패턴들
팩토리, 추상 팩토리, 브릿지, 커맨드 패턴 등 이미 사용 중
특징
OCP 준수, 하지만 과도하게 복잡해질 수 있음
템플릿 메서드 패턴
잘 사용하지 않음, 요즘은 implement
interface는 내부 instance를 둘 수 없음 -> 필요 시 abstract class 를 사용
상속을 통해 슈퍼 클래스의 기능을 확장할 때 사용하는 대표적인 방법
변하지 않는 기능은 슈퍼 클래스에 만들어 두고, 확장할 기능은 서브 클래스에서 만듦
단점
알고리즘 변경 시 거의 모든 클래스에 수정이 가해질 수 있음
상속의 단점.. 결합이 커서
public abstract class Review { //abstract 사용예시
public void review() {
//부모 클래스에서 알고리즘의 골격을 정의
login();
selectBooks();
putContent();
selectEvaluation();
}
public void login() {
log.info("로그인 성공!");
}
public void selectBooks() {
log.info("리뷰 대상 상품 선택");
}
public void selectEvaluation() {
log.info("별점 선택");
}
public abstract void putContent(); //
}
방문자 패턴
잘 사용하지 않음
맴버는 맴버 클래스로, 리워드는 리워드 클래스로.. 둘을 섞지 않는다
OCP : 다른 클래스를 변경하지 않으면서 새로운 행동 도입 가능
SRP : 같은 행동의 여러 버전을 같은 클래스로 이동할 수 있음
public class PointBenefit implements Benefit {
@Override
public void getBenefit(GoldMember member) {
log.info("골드 멤버를 위한 포인트 제공 혜택");
}
@Override
public void getBenefit(VIPMember member) {
log.info("VIP 멤버를 위한 포인트 제공 혜택");
}
@Override
public void getBenefit(SilverMember member) {
log.info("실버 멤버를 위한 포인트 제공 혜택");
}
}
public class GoldMember implements Member {
// public void point() {
// log.info("골드 멤버를 위한 포인트 제공 혜택");
// }
// public void discount() {
// log.info("골드 멤버를 위한 할인 혜택");
// }
@Override
public void getBenefit(Benefit benefit) {
benefit.getBenefit(this);
}
}
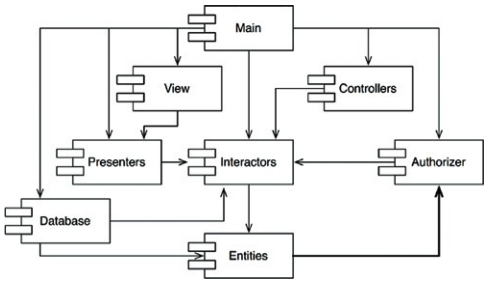
세 컴포넌트는 하나의 거대 컴포넌트가 되며, 개발자 서로가 얽매여 모두 항상 정확하게 동일한 릴리스를 사용해야 함
Entities를 테스트하려면 Authorizer와 Interactors도 빌드하고 통합해야 하면서 어려워짐
모듈의 개수가 많아짐에 따라 빌드 관련 이슈는 기하급수적으로 증가함
컴포넌트를 어떤 순서로 빌드해야 올바른지 파악하기 힘들어지며, 올바른 순서라는 것 자체가 없을 수 있음
순환 끊기
컴포넌트 사이의 순환을 끊고, DAG로 복구하는 것은 언제든 가능하며, 의존성 역전 원칙 또는 새로운 컴포넌트 생성으로 가능함
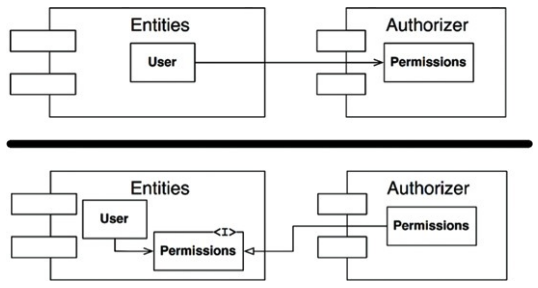
의존성 역전 원칙(DIP)
User가 필요로 하는 메소드를 제공하는 인터페이스(permissions in Entity)를 제공함
그리고 이 인터페이스는 Entities에, 구현체는 Authorizer에 위치시킴
DIP
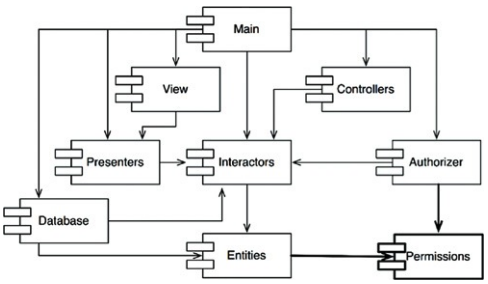
새로운 컴포넌트 생성
Entities와 Authorizer가 의존하는 새로운 컴포넌트를 만듬
그리고 두 컴포넌트가 모두 의존하는 클래스들을 새로운 컴포넌트로 이동시킴
흐뜨러짐(Jitters)
두 번째 해결책(새로운 컴포넌트 생성)이 시사하는 바는 요구사항이 변경되면 컴포넌트 구조도 변경될 수 있다는 사실
실제로 애플리케이션이 성장하면서 컴포넌트 의존성 구조는 서서히 흐트러지며 또 성장함
따라서 의존성 구조에 순환이 발생하는지를 항상 관찰해야 하며, 어떤 식으로든 끊어내야 함
하향식(top-down) 설계
프로젝트 초기에는 컴포넌트 구조를 설계할 수 없음. 즉, 컴포넌트 구조는 하향식(top-down)으로 설계될 수 없음
컴포넌트 의존성 다이어그램은 애플리케이션 기능과는 거의 관련이 없고, 빌드 가능성과 유지보수성의 지도와 같음
컴포넌트는 시스템에서 가장 먼저 설계할 수 있는 대상이 아니며, 시스템이 성장하고 변경될 때 함께 진화함
하지만 모듈들이 점차 쌓이기 시작하면 의존성 관리에 대한 요구가 점차 늘어남
변경되는 범위가 시스템의 가능한 한 작은 일부로 한정되기를 원함
함께 변경되는 클래스는 같은 위치에 배치시킴: 단일 책임 원칙(SRP), 공통 폐쇄 원칙(CRP)
의존성 구조와 관련된 최우선 관심사는 변동성의 격리(자주 변경되는 컴포넌트로 부터 다른 컴포넌트를 보호함)
애플리케이션이 계속 성장하면서 재사용 가능한 요소를 만드는 일에 관심을 기울이기 시작함: 공통 재사용 원칙(CRP)
결국 순환이 발생하면 컴포넌트 의존성 그래프는 조금씩 흐트러지고 또 성장함: 의존성 비순한 원칙(ADP)
"아무런 클래스도 설계하지 않은 상태에서 컴포넌트 의존성 구조를 설계하려고 시도하면 큰 실패를 맛볼 수 있다. 공통 폐쇄 원칙에 대해 그다지 파악하지 못하고 있고, 재사용 가능한 요소도 알지 못하며, 컴포넌트를 생성할 때 거의 확실히 순환 의존성이 발생할 것이다. 따라서 컴포넌트 의존성 구조는 시스템의 논리적 설계에 발맞춰 성장하며 또 진화해야 한다."
SDP: 안정된 의존성 원칙
정의: 안정성의 방향으로(더 안정된 쪽에) 의존하라.
변경이 어려운 컴포넌트는 최대한 독립적으로
변경이 어려운 컴포넌트에 한번 의존하게 되면 변동성이 큰 컴포넌트도 결국 변경이 어려워짐
즉, 변경하기 쉽도록 모듈을 설계해도 이 모듈에 누군가가 의존성을 메달아 버리면 이 모듈도 변경하기 어려워짐
안정성(stability)
안정성은 변경의 발생 빈도와는 직접적인 관련이 없고, 변경을 위해 필요한 작업과 관련됨
안정적이라는 것은 변경을 위해 상상한 수고를 감수해야 한다는 것
컴포넌트를 변경하기 어렵게 만드는 많은 요인(컴포넌트의 크기, 복잡도, 간결함 등)이 존재하는데, 이중 다른 컴포넌트가 해당 컴포넌트에 의존하게되면 변경이 특히 어려워짐
왜냐하면 사소한 변경이라도 의존하는 모든 컴포넌트를 만족시키면서 변경하려면 상당한 노력이 들기 때문임
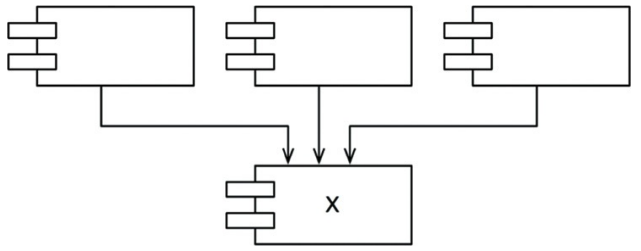
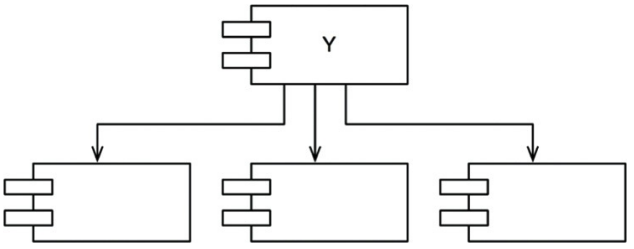
x is stable
X는 안정된 컴포넌트인데, 세 컴포넌트가 X에 의존하며 X는 변경하지 말아야 할 이유가 3가지나 됨
이때 X는 세 컴포넌트를 책임진다고 말하며, 반대로 X는 어디에도 의존하지 않음
X가 변경되도록 만들 수 있는 외적인 영향이 전혀 없으므로, X는 독립적이라고 말함
t is unstable
아래의 Y는 상당히 불안정한 컴포넌트임
어떤 컴포넌트도 Y에 의존하지 않으므로 Y는 책임성이 없음
Y는 세 컴포넌트에 의존하므로 변경이 발생할 수 있는 외부 요인이 3가지이므로, Y는 의존적이라고 함
안정성 지표
컴포넌트로 들어오고 나가는 의존성의 개수를 통해 컴포넌트의 불안정성(I)을 계산할 수 있음
fan-in: 안으로 들어오는 의존성으로 컴포넌트 내부의 클래스에 의존하는 컴포넌트 외부의 클래스 개수
fan-out: 바깥으로 나가는 의존성으로 컴포넌트 외부의 클래스에 의존하는 컴포넌트 내부의 클래스 개수
불안정성(I)은 fan-out / (fan-in + fan-out)으로 계산 가능하며, [0, 1] 사이의 값을 가짐
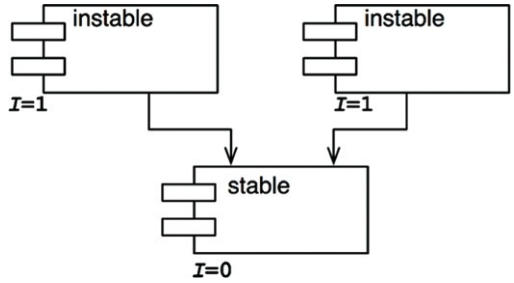
불안정성(I)가 0인 경우(X)
해당 컴포넌트에 의존하는 다른 컴포넌트는 있지만, 해당 컴포넌트 자체는 다른 컴포넌트에 의존하지 않음
이는 컴포넌트가 가질 수 있는 최고로 안정된 상태이며, 이러한 컴포넌트는 다른 컴포넌트를 책임지며 독립적임
X에게 의존하는 컴포넌트가 있으므로 변경이 어렵지만, X를 강제하는 의존성은 갖지 않음
불안정성(I)가 1인 경우(Y)
어떤 컴포넌트도 해당 컴포넌트에 의존하지 않지만, 해당 컴포넌트는 다른 컴포넌트에 의존함
최고로 불안정한 상태이며 책임성이 없으므로 의존적임
의존하는 컴포넌트가 없으므로 변경하지 말아야 할 이유가 없음
Y가 다른 컴포넌트에 의존한다는 뜻은 Y를 변경할 이유가 있다는 것임
모든 컴포넌트가 안정적이어야 하는 것은 아니다
우리가 기대하는 것은 불안정한 컴포넌트와 안정된 컴포넌트가 모두 존재하는 상태
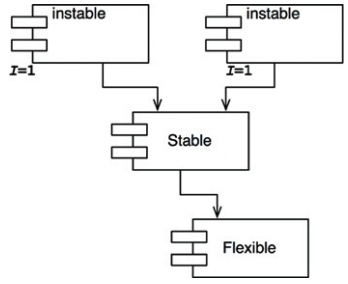
위 다이어그램은 세 컴포넌트로 구성된 시스템이 갖는 이상적인 구조임
상단에는 변경 가능한 컴포넌트들이 있고, 하단의 안정된 컴포넌트에 의존함
위로 향하는 화살표가 있으면 안정된 의존성 원칙(SDP)에 위배되는 것인데, 존재하지 않음
Flexible은 변경하기 쉽도록 설계한 컴포넌트임
우리는 Flexible이 불안정한 상태이기를 바라지만, Stable에서 Flexible에 의존성을 걸게 되면 SDP를 위배함
Flexible을 변경하려면 Stable과 Stable에 의존하는 나머지 컴포넌트에도 조치를 취해야 함
이를 해결하려면 Flexible에 대한 Stable의 의존성을 끊어야 함
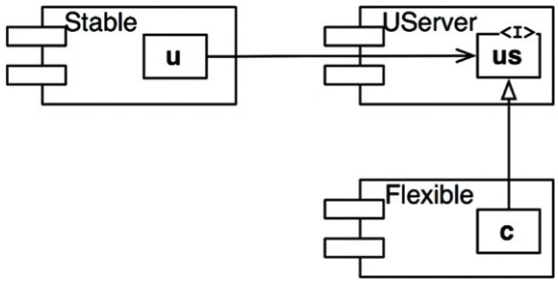
예를 들어 Stable의 내부 클래스 U가 Flexible의 내부 클래스 C를 사용할 때, DIP를 도입하면 이 문제를 해결할 수 있음
DIP 적용
US라는 인터페이스를 생성하고 이를 UServer 컴포넌트에 넣은 후 C가 해당 인터페이스를 구현하도록 만듦
이를 통해Flexible에 대한Stable의 의존성을 끊고, 두 컴포넌트는 모두 UServer에 의존하도록 강제함
UServer는 매우 안정되며(I=0) Flexible은 불안정성(I=1)을 유지할 수 있고,모든 의존성은 I가 감소하는 방향으로 향함
오로지 인터페이스만을 포함하는 컴포넌트(UServer)를 생성하는 방식이 이상하게 보일 수도 있음
하지만 자바와 같은 정적 타입 언어에서는 이 방식이 흔히 사용되며 꼭 필요한 전략으로 알려져 있음
이러한 추상 컴포넌트는 상당히 안정적이며, 따라서 덜 안정적인 컴포넌트가 의존할 수 있는 이상적인 대상임
SAP: 안정된 추상화 원칙
정의: 컴포넌트는안정된 정도만큼만 추상화되어야 한다.
고수준 정책(자주 변경해서는 안되는 소프트웨어)을 어디에 위치시켜야 하는가?
고수준 정책을 캡슐화하는 소프트웨어는 안정된 컴포넌트에, 변동성이 큰 소프트웨어는 불안정한 컴포넌트에 포함시켜야 함
하지만 고수준 정책을 안정된 곳에 위치시키면, 그 정책을 포함하는 소스 코드 수정이 어려워져 시스템 전체 아키텍처가 유연성을 잃음
해결: 개방 폐쇄 원칙(OCP)
이 원칙을 준수하는 클래스가 추상 클래스임
안정된 추상화 원칙(SAP)
안정된 추상화 원칙은 안정성과 추상화 정도 사이의 관계를 정의
안정된 컴포넌트는 추상 컴포넌트여야 하며, 이를 통해 안정성이 컴포넌트를 확장하는 일을 방해해서는 안됨
불안정한 컴포넌트는 반드시 구체 컴포넌트로써, 컴포넌트가 불안정하므로 내부의 구체적인 코드를 쉽게 변경할 수 있어야 함
안정된 추상화 원칙(SAP)와 안정된 의존성 원칙(SDP)를 결합하면 컴포넌트에 대한 의존성 역전 원칙(DIP)
추상화 정도 측정하기
A = Na / Nc
Nc는 컴포넌트의 클래스 개수다.
Na는 컴포넌트의 추상 클래스와 인터페이스 개수다.
A = 0 : 컴포넌트에 추상 클래스가 하나도 없다.
A = 1 : 오로지 추상 컴포넌트만 있다.
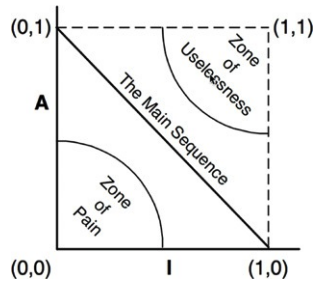
주계열
안정성(I)과 추상화 정도(A) 사이의 관계를 표현하면 다음과 같음
최고로 안정적이며 추상화된 컴포넌트는 좌측 상단(0,1)
최고로 불안정하며 구체화된 컴포넌트는 (1,0)에 위치함
모든 컴포넌트가 이 두 지점에 위치하지는 않으며, 컴포넌트는 추상화와 안정화의 정도가 다양함
컴포넌트가 위치할 수 있는 합리적인 궤적을 표현하면 다음과 같음
고통의 영역(Zone of Pain)
(0, 0) 주변 구역에 위치한 컴포넌트들
매우 안정적이며 구체적인데, 컴포넌트가 뻣뻣한 상태이므로 바람직하지 않음
추상적이지 않으므로 확장이 어렵고, 안정적이므로 변경이 어려움
제대로 설계된 컴포넌트라면 여기에 위치하지 않으며, 배제해야 하는 구역임
ex) 데이터베이스 스키마 or String 클래스(String은 변동성이 없으므로 해롭지는 않음) 등
쓸모없는 구역(Zone of Uselessness)
(1, 1) 주변 구역에 위치한 컴포넌트들
최고로 추상적이지만, 누구도 그 컴포넌트에 의존하지 않음(쓸모 없음)
이는 누구도 구현하지 않은 채 남겨진 추상클래스인 경우가 많음
주계열(The Main Sequence)
변동성이 큰 컴포넌트들을 두 배제 구역으로부터 가능한 멀리 떨어뜨리는 선분
쓸모없지 않으면서도 심각한 고통을 안겨주지도 않음
가장 바람직한 지점은 주 계열의 종점이긴 하지만 일부 컴포넌트는 불가능할 수 있음
주계열 바로 위에 또는 가깝게 위치할 때 가장 이상적
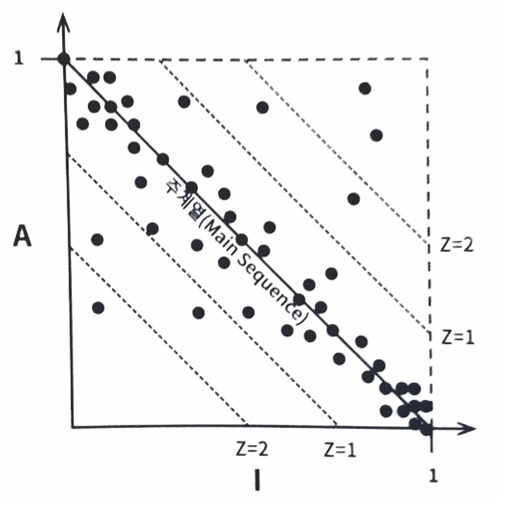
주계열과의 거리
주계열로부터 얼마나 떨어져 있는지 측정하는 지표.
D=| A + I -1 |
D가 0에 가까울수록 이상적(주계열 선 위)
D가 0에서 가깝지 않다면 해당 컴포넌트는 재검토한 후 재구성하도록 계획 가능
D지표의 평균과 분산을 통해 다른 컴포넌트에 비해 예외적인 컴포넌트 추출 가능 -> 리팩
컴포넌트 산점도
반대로 한 컴포넌트의 D를 시간 별(릴리즈 별)로 측정하여 주계열에서 멀리 떨어진 시점에 들어간 feature에 대해 리뷰 가능
의존성 관리 지표는 설계의 의존성과 추상화 정도가 내가 “흘륭한” 패턴이라고 생각하는 수준에 얼마나 잘 부합하는지를 측정함
지표는 임의로 결정된 표준을 기초로 한 측정값에 지나지 않기에, 다음 단계에 대한 힌트로 사용하면 충분
Unix Shell • Kernel을 둘러싸고 있는 껍데기 • 사용자가 제어할 수 있는 명령행 해석기
Bourne Shell • 1977, Stephen Bourne • /bin/sh
BASH (Bourne Again Shell) • 1989, Brian Fox • /bin/bash
ssh -> secure shell
-> 이걸로 게이트웨이까지 가고 그 이후론
rlogin -l 아이디 호스트명
이걸로 로그인
pwd: present working directory
id
uname: unix system name -> os 정보 아키텍쳐 등
hostname
배쉬 내부 명령
command line argument(parameter)
echo는 기본적으로 new line이 나가기 때문에 그걸 무시하려면 -n옵션
ls
ls -1 파일 이름만 한줄에 하나씩
-a 숨겨진 것도
-F 파일
-l 롱포맷
ls 중 어떤 규칙만 필터 치고 싶다면..(패턴)
glob pattern
임의의 길이(wildcard) *
임의의 한 글자 ?
ls * -> 전체
ls .* -> 히든 전체
ls [a-f]*.txt -> a~f로 시작하는 텍스트 파일
ls *.tx? -> .txa 등의 확장자를 가진 파일
파일 시스템
File
OS에서 데이터를 디스크와 같은 저장소에 저장해 둘 때의 단위 형태
넓은 의미에서는 일반 파일, 디렉토리와 각종 입출력 장치를 모두 파일로 간주
Directory
파일을 담아두는 공간 (폴더)
디렉토리 안에 디렉토리를 담을 수 있기 때문에 트리 구조로 형상화
cd : change directory
pwd
~ : 홈디렉토리
ls ~ 아이디 : 다른사람의 홈디렉토리
history
히스토리 중 다시 실행하고 싶다면
!12 : 히스토리 중 12번 재실행
!find : 히스토리 중 마지막 find로 실행했던 구문 재실행
!! : 바로 직전 명령 재실행
!$ : 바로 직전 명령의 마지막 argument
직전 명령 편집
echo "hello world"
^hello^java :hello -> java 변환(^ 캐럿이라고 부름)
touch
빈 파일 만들기, last modify date 바꿀 때
mkdir : make directory
rmdir : remove directory 빈 디렉토리만 삭제
cp 복사
mv 장소 이동, 이름 변경
rm 파일 삭제
rm -r : recursive하게 안에서부터 쫙 지우고 마지막으로 폴더 삭제
file /bin/gzip(파일) : 어떤 파일인데? 확인하는 용도
변수
사용자 변수 • 보통 소문자로 명명 • x=1 • x="hello world" • x=hello world (x)
주의사항
= 주위에 공백 없음
값을 꺼내쓰기(de-reference)
echo $x / ${x} / "$x"
single quote
literal, 문자열
치환이 안됨
double quote(기본적으로 이거 사용)
변수임
실행 결과를 변수로 저장
: backquote(`) 또는 $( )로 둘러싸기
date_str=`date +"%Y%m%d"`
// -> 날짜를 오른쪽 형식으로
date_str=$(date +"%Y%m%d")
명령 문자열을 실행하기
eval 명령문자열
cmd="ls –alF"
eval "$cmd
환경 변수
환경(environment)
프로세스를 둘러싼 주변 정보
env
상속가능
export var1 = 2
exporting
sub-shell (쉘 안의 쉘)에서 상속받아 사용할 수 있도록 변수를 공개
사용자 변수를 환경 변수로 전환
export나 declare –x로 지정
권한
u/g/o
chmod u+x test1.sh
// -> owner에게 실행권한을 주기
실행 시 경로를 주거나 어떤걸로 실행할지 알려주면 됨
./test.sh
bash test.sh
소유자 변경
chown 아이디 파일
Boolean expression
&&, ||, !, –a, –o
-a = &&이고 -o = ||
(( 0 && 1 )) && echo true || echo false
-> then else
((식)) && 참이면 실행 || 거짓이면 실행
(( 0 || 1)) && echo true || echo false
integer -eq -ne -gt -ge -lt –le
string < <= > >= = != -z –n
-z : zero length?
-n : null?
if
세미콜론, 공백과의 싸움
if [ 조건 ]; then
실행문
fi
한 줄 쓰기
x=3; if [ $x –eq 3 ]; then echo "x is 3"; fi
주의사항
-eq 연산자는 정수 연산자
= 연산자는 문자열 연산자
변수가 정의되지 않았거나 공백을 포함할 수 있으므로 quotation 필요
x="he llo"
if [ "$x" = "he llo" ]; then echo "$x"; fi
==는 shell마다 약간 호환성 차이가 있음, 하나(=)를 써라
for/while
for loop은 foreach 형식만 지원
for(int i = 0; i <10; i++)의 형식은 while문으로 작성해야 함
while [ 조건 ]; do
실행문
done
i=3; while [ "$i" -lt 10 ]; do echo "$i"; i=$((i+1)); done
3
4
5
6
7
8
9
무한루프 :
while :; do
date
sleep 5
done
or watch 명령어로 주기적으로 감시 가능
watch -n 5 "date"
for
for 변수명 in 리스트; do
실행문
done
for dir in *; do
//* : 현재 경로의 파일/디렉토리를 dir에 바인딩
[ -d "$dir" ] && (echo -n "$dir "; cd "$dir"; ls | wc –l)
//[ ] 가 참이면 ()를 실행
// -d dir이 디렉토리냐?
//에코쓰고 이동하고 안에 있는 파일의 갯수를 찍어(현재 디렉토리 하위 디렉토리 안의 파일 갯수 확인)
//서브쉘이 끝나면 원래 디렉토리로 돌아옴; 돌아오는 코드 귀찮아서 서브쉘
//서브쉘 중간에 실패 시 자동으로 오니까..
done
swtich-case 문
case 변수 in
케이스1)
실행문;;
케이스2)
실행문;;
*)
실행문;;
esac
입출력 리다이렉트
1(생략) 이거 아니고 0(생략) 이거임! 0번이 표준입력
합칠 수도 있다!
필터
프로세서의 출력을 다른 프로세스의 입력으로 전달
| 파이프 기호를 이용
ls | head : ls의 출력을 head의 입력으로 받아
line by line으로 세서 출현 빈도 수로 정렬
cat test.txt | sort | uniq –c | sort -n
sort 알파벳순 정렬
uniq -c 중복을 없애면서 중복 갯수를 출력(카운트 옵션)
sort -nr 맨 앞을 숫자로 보겠다, 출현 빈도수가 높은걸 맨 앞으로 두고 나머지를 두라(r옵션이 desc)
find /etc 2>&1 | grep 허가
//찾아 여기서 에러랑 아닌거 같이 모아서 허가 찾아
문서 보기
cat은 페이징 없음
more/less 페이지씩 보여줌 엔터치면 더 보여줌(pager)
grep문자열 파일
grep -r (모든 파일에 대해 recursive 하게 검색)
grep bash .bashrc | less -eMR
head 앞에 몇 줄만
tail 뒤에 몇 줄만 tail -f 최근 접속 실시간 출력
잘라내서 쓰기
cut –d 구분자 –f 필드번호 파일
구분자로 split해서 시작번호는 1번부터
1,3,4,7번째를 모아서 :로 붙여서 보여줌
grep irteam /etc/passwd | cut –d: –f1,3-4,7
shebang(#!)쉐벵
어떤 인터프리터 프로그램을 사용할 것인가를 지정
#!/bin/bash
#!/usr/bin/env python
권장하는 방식
지정해주면 파이선으로 실행하지 않고 배쉬로 실행해도 배쉬가 첫 줄을 보고(인터프리터) 파이선인지 파악하여 파이선으로 실행 함
리눅스 포직스(?)
commane line arguments
$0 자기자신 쉘 이름
$# 변수 몇 개?
$? 실행 결과 0:정상; 0이 아니면 에러
설정
Bourne shell
~/.profile
Bash
login shell
bashrc
non-login shell
bash_profile -> 이거 하나 만 만들고 그 안에서 rc를 불러오도록 하는게 좋음
탭으로 여러개 띄우면 안되고, 브라우저 자체를 여러개 해야하는데 동시 요청이 사실상 힘듦..
정 탭으로 해야하면 url 뒤에 fragment를 다르게 요청하면 된다고 한다.
In Chrome, the calls get queued when you call the same resource from two tabs, but executed in parallel when you make the calls from different windows.
In IE11, they always get executed in parallel
In Firefox, it doesn't matter whether the calls are from different tabs or windows, they always get queued.
All of them execute them in parallel when the URLs are slightly different, by adding a different fragment or parameter.
서로 다른 레이어에서 변수들을 전달할 때 서로 다른 dto를 사용하는데, 얼핏 비슷하면서도 한두 개 다른 변수들을 하나씩 매핑해 주는 게 매우 귀찮고 번거로웠다.
어휴..
그래서 이를 자동(?)으로 해주는 라이브러리 같은 게 있을까 싶어서 몇 개 찾아보았다.
구글링 해보면 여러 개가 나오는데 아래 3개를 먼저 확인해 보았다.
1. 스프링에 기본 내장되어 있는 BeanUtils.copyProperties
2. 사용하기 편해 보이는 ModelMapper
3. 요즘 제일 인기 있는 Mapstruct
실제로 사용하려는 목적이기에 현실적인 사용성을 중심으로 살펴보았다.
dependency
di주입
원리(setter 선언 필요?)
필드 커스텀 가능 여부
Mapstruct
추가 필요(4개)
빈 주입 필요 interface 작성
리플랙션X - 컴파일 시 작성된 getter/setter or 빌더 or 생성자 등 관련 코드를 이용하여 변환 class 만듦 - setter 없어도 됨
매핑으로 커스텀 설정 가능
ModelMapper
추가 필요(1개)
주입 필요 없음
리플렉션O getter/setter 기반 - 필드명/타입이 동일할 경우 필드 엑서스 레벨을 private으로 설정하면 setter가 필요없지만 - 커스텀 시 setter 선언 필요
커스텀을 위해 typeMap과 addMapping 을 이용하여 손수 매핑해줘야 함
BeanUtils.copyProperties
추가 필요 없음 spring 내장
주입 필요 없음 static method void type
리플렉션O getter/setter 기반 - setter 선언 필요 - 커스텀 시 setter 수정 필요
더 복잡한 변환이 필요할 경우 사용 불가하며spring BeanWrapper를 직접 구현해야 함
Mapstruct
lombok과 함께 사용가능(lombok compile 이후에 작동)
implementation 'org.mapstruct:mapstruct:1.5.3.Final'
annotationProcessor 'org.mapstruct:mapstruct-processor:1.5.3.Final'
testAnnotationProcessor 'org.mapstruct:mapstruct-processor:1.5.3.Final'
//If you are using Lombok 1.18.16 or newer you also need to add lombok-mapstruct-binding in order to make Lombok and MapStruct work together.
implementation 'org.projectlombok:lombok-mapstruct-binding:0.2.0'