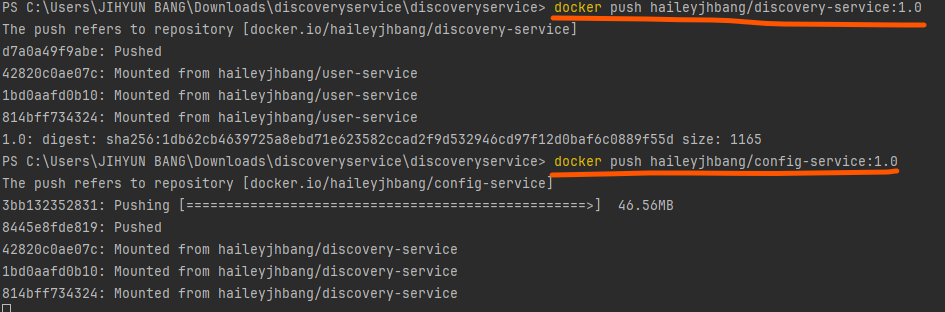
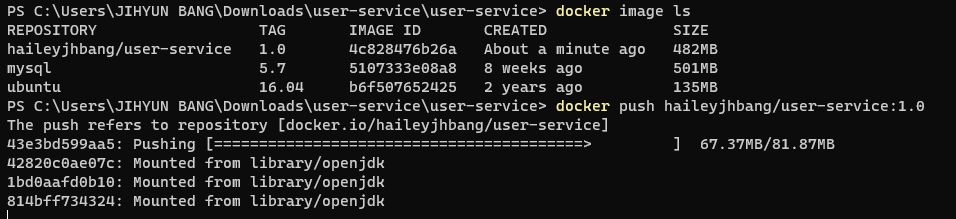
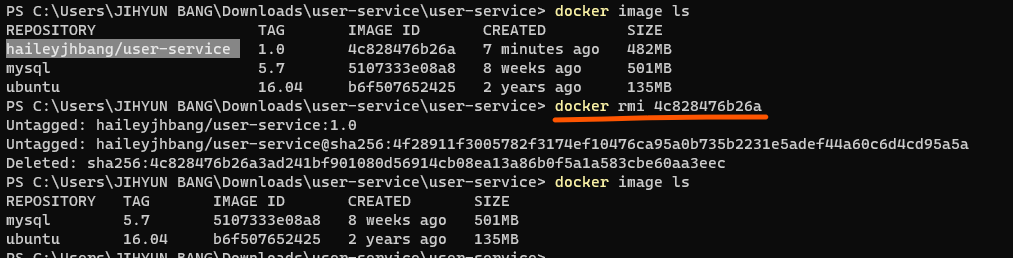
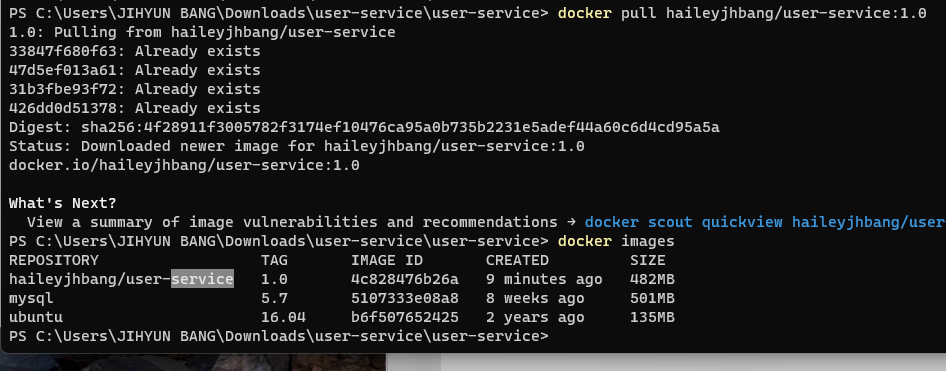
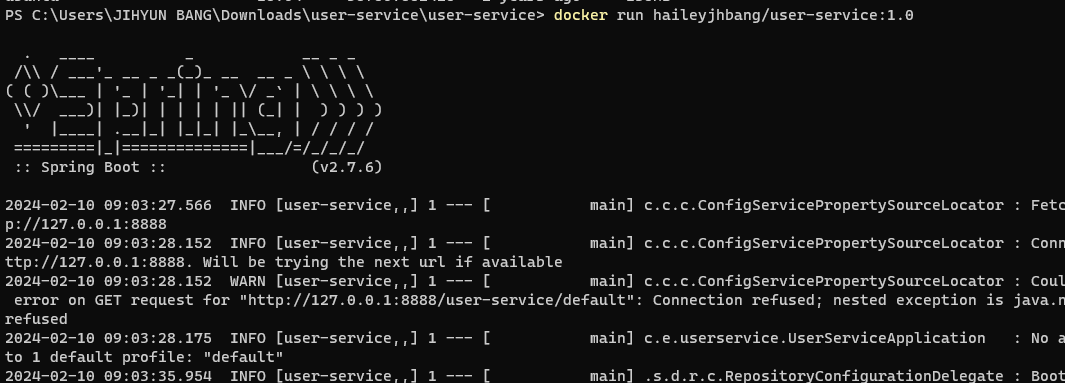
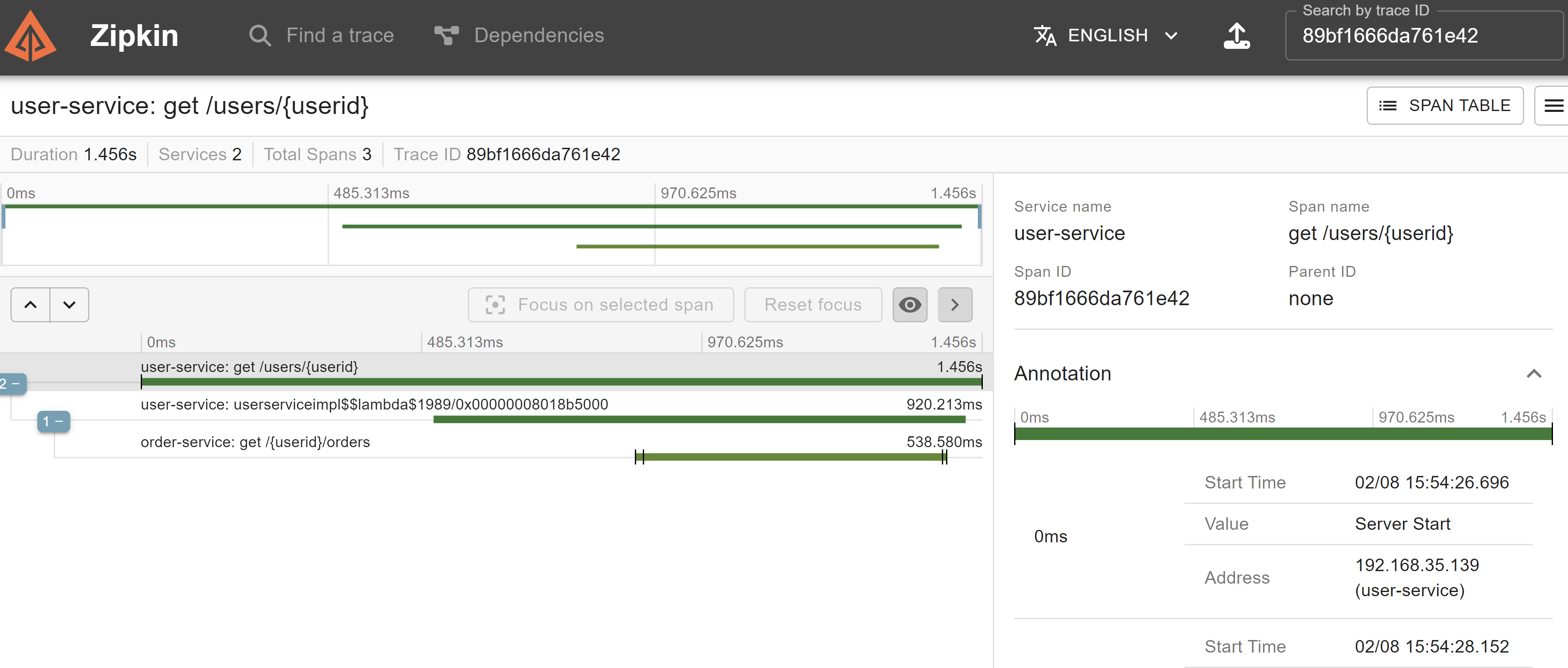
해당 config server 정보는 도커에서는 다르게 적용되어야 하므로 실행 시 정보 추가 필요
docker run -d -p 8761:8761 --network ecommerce-network \
-e "spring.cloud.config.uri=http://config-service:8888" \
--name discovery-service haileyjhbang/discovery-service:1.0
//포트 포워딩; 네트워크 설정
//설정 추가; 같은 네트워크로 묶여있기 때문에 컨테이너 이름을 명시해도 문제없음
//네임, 이미지 이름 명시
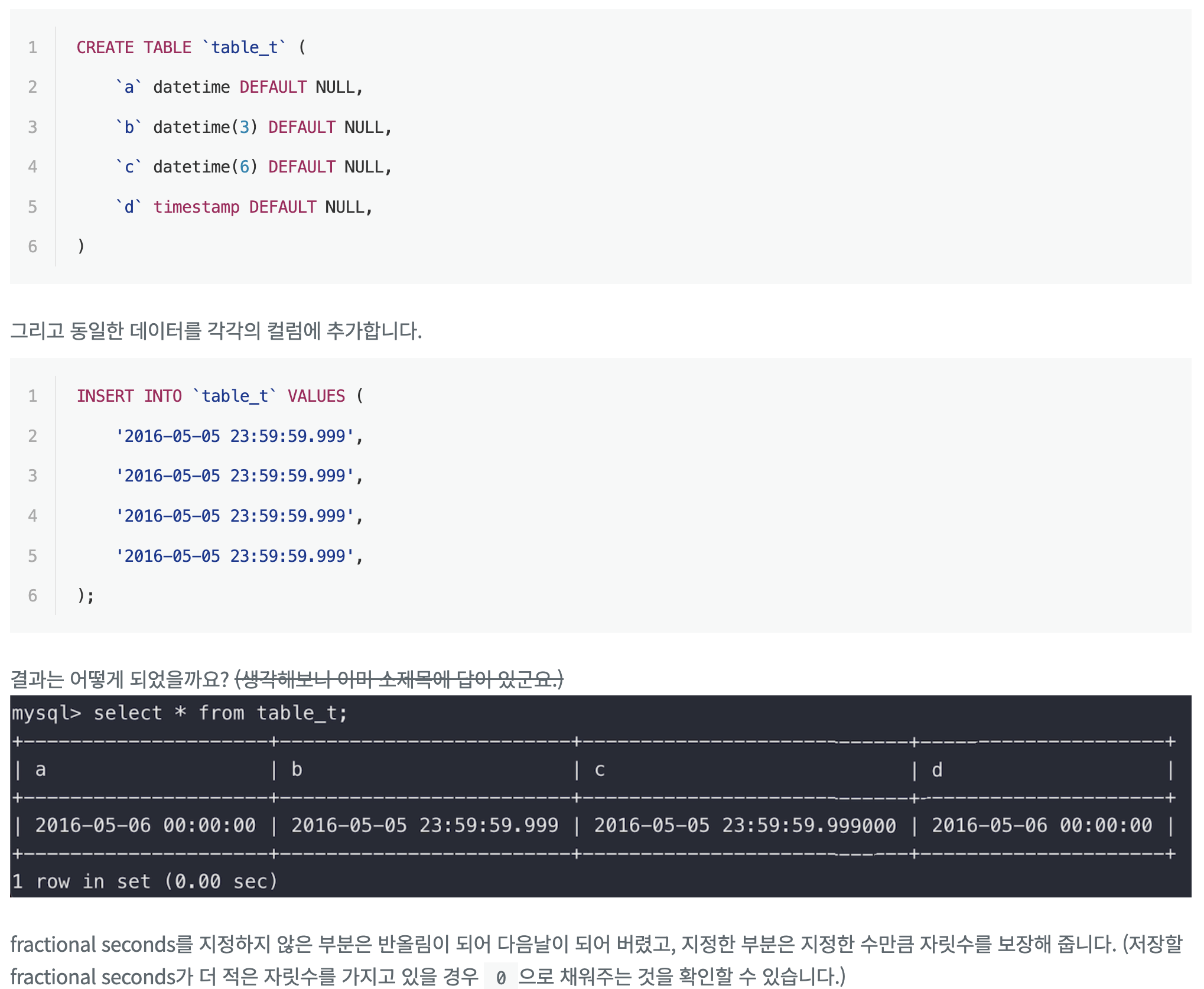
그리고 JPA/mysql-connector 내부적으로도 반올림하는 부분이 있어 시간에 민감한 데이터인 경우 LocalDateTime.now()를 사용하는 것도 문제가 될 수 있다고 한다. 이럴 땐 DB connect 시 설정에 sendFractionalSeconds=false를 추가해줘야 한다.
docker network create --driver bridge 브릿지이름
docker network is
host network
네트워크를 호스트로 설정하면 호스트의 네트워크 환경을 그대로 사용 가능
포트 포워딩 없이 내부 애플리케이션 사용
none network
네트워크 사용하지 않음
IO네트워크만 사용, 외부와 단절
네트워크 세팅
docker desktop을 실행하여 docker daemon을 실행하고 초기화
docker container ls -a // 꺼진 컨테이너들까지 확인
docker system prune // 이미지와 남는 것들 까지 다 삭제
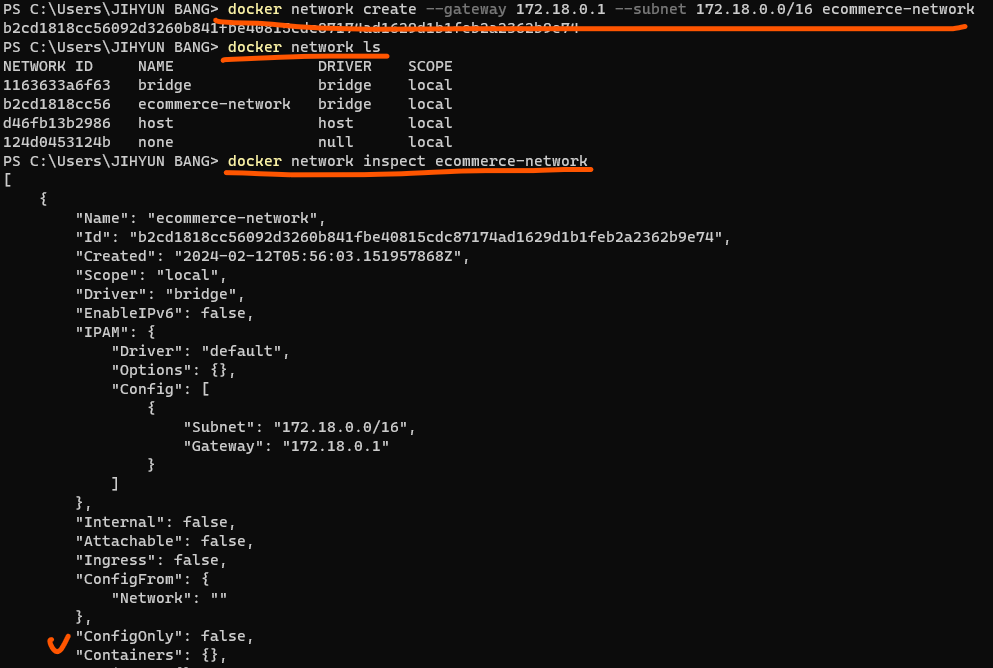
docker network create --gateway 172.18.0.1 --subnet 172.18.0.0/16 ecommerce-network
// docker network create ecommerce-network
// gateway와 subnet 정보를 안주면 랜덤으로 되긴하는데 설정해주는게 관리가 편함
// 이름은 꼭 주도록; 그러면 ip가 바뀌어도 이름으로 접근가능
docker network ls
// 네트워크 리스트
docker network inspect 네트워크이름
// 네트워크 상세 정보
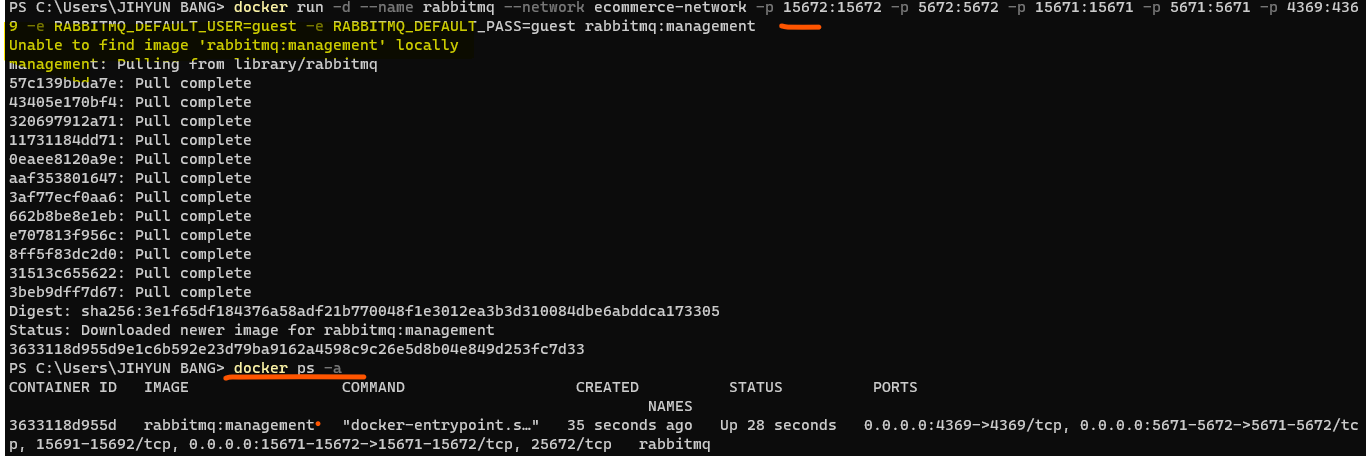
rabbitmq 도커 세팅
docker run -d --name rabbitmq --network ecommerce-network \
-p 15672:15672 -p 5672:5672 -p 15671:15671 -p 5671:5671 -p 4369:4369 \
-e RABBITMQ_DEFAULT_USER=guest \
-e RABBITMQ_DEFAULT_PASS=guest rabbitmq:management
//도커를 백그라운드에서 돌리고 이름을 부여하고 특정 네트워크 안에서 돌 수 있게 지정
//rabbitmq 내부에서 사용하는 포트 포워딩
//환경변수
//이미지 이름이 rabbitmq:management
run으로 실행하면 기존에 rabbitmq:management 라는 이미지가 없으므로 다운로드하는 작업이 포함됨
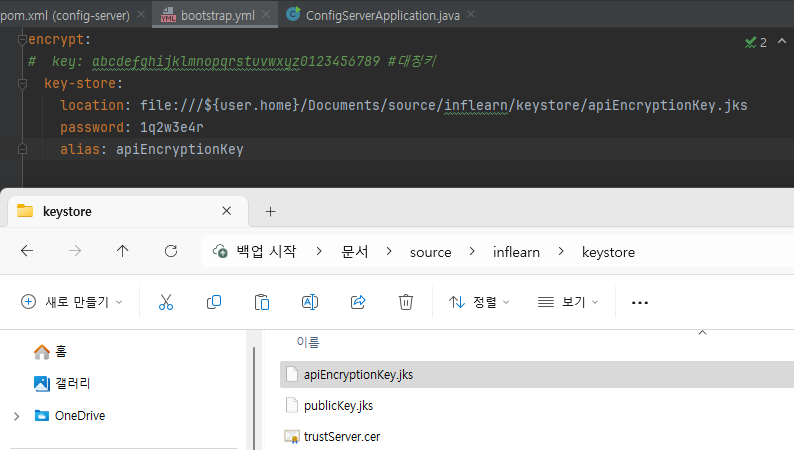
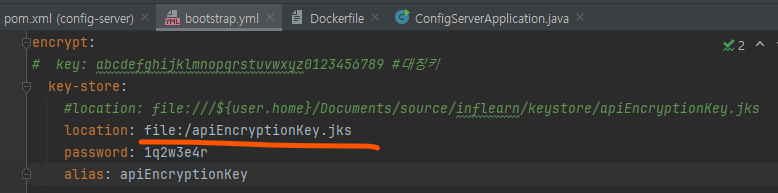
해당 파일 경로가 바뀌고 remote에서는 본 파일로 실행해야 하기 때문에 아래처럼 설정파일 경로도 수정해야 함.
참고로 맥에서는 file:/ 의 슬래시도 지워야 된다는 말이 있는데 나는 우선 이걸로 성공..
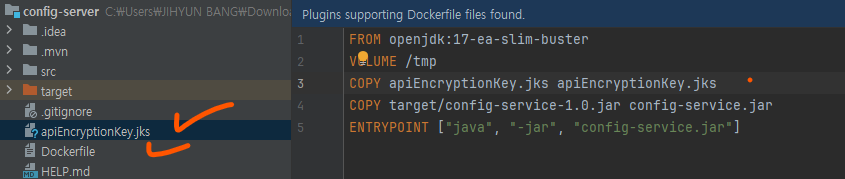
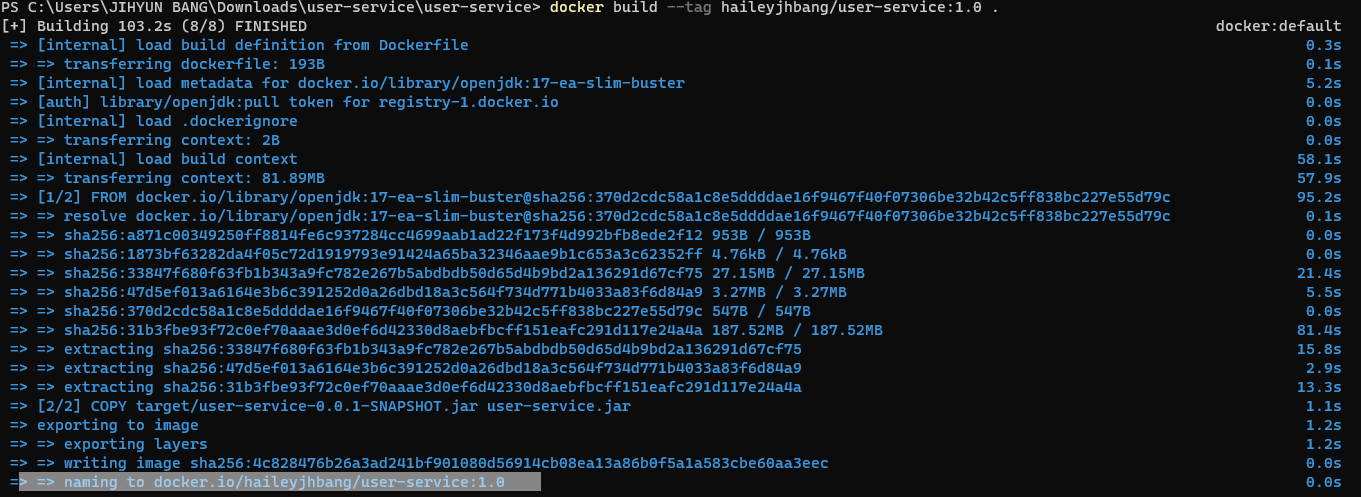
jar 파일 빌드
mvn clean compile package -DstkpTests=true
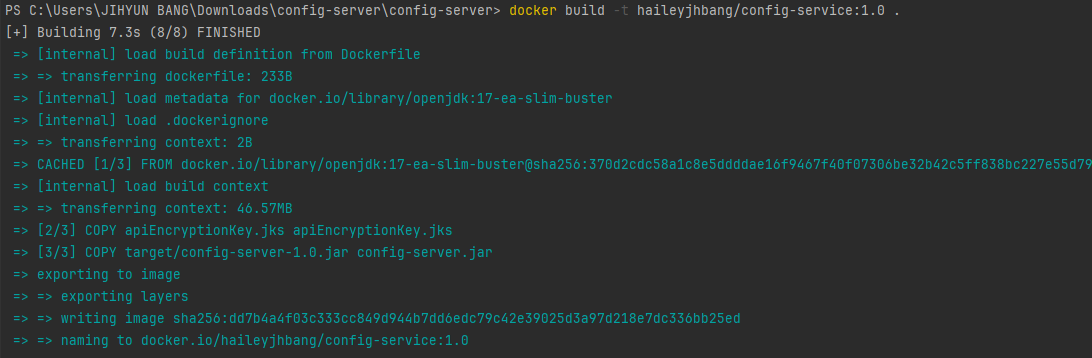
도커 빌드; 현재 디렉터리 안에서 실행한다는 의미의 점 꼭..!
docker build -t haileyjhbang/config-service:1.0 .
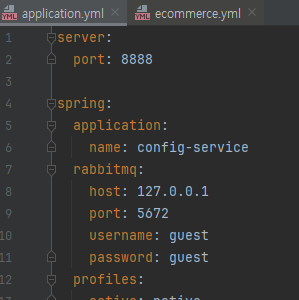
기존 application.yml 설정을 확인해 보면 rabbitmq 설정이 로컬 테스트용으로 되어있음. 이를 도커에 그대로 올리면 당연히 안될 거고 도커의 rabbitmq로 바꿔줘야 함.
물론 설정 자체를 수정(docker ip를 넣고 저장)해서 그대로 jar을 말아줄 수도 있지만, docker ip는 바뀔 수 있음. 따라 jar는 그대로 말고 실행 시 도커의 이름으로 주입해 주는 게 편함.
docker run -d -p 8888:8888 --network ecommerce-network \
-e "spring.rabbitmq.host=rabbitmq" \
-e "spring.profiles.active=default" \
--name config-service haileyjhbang/config-service:1.0
// 포트 포워딩, 기존의 네트워크 안에 포함
// 설정 변경사항 추가
// 이름 주고 이미지 주고
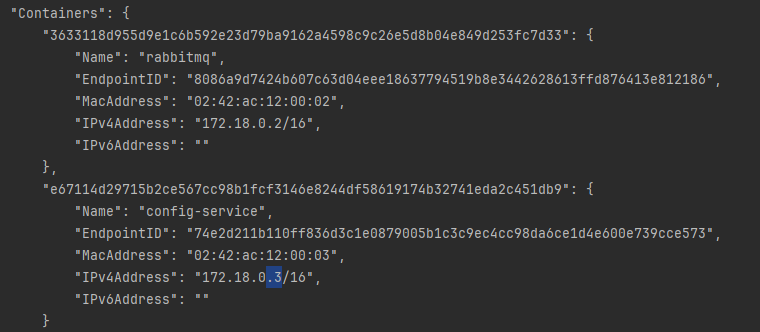
실행 후 네트워크 검사하면 3번으로 실행됨
docker network inspect ecommerce-network
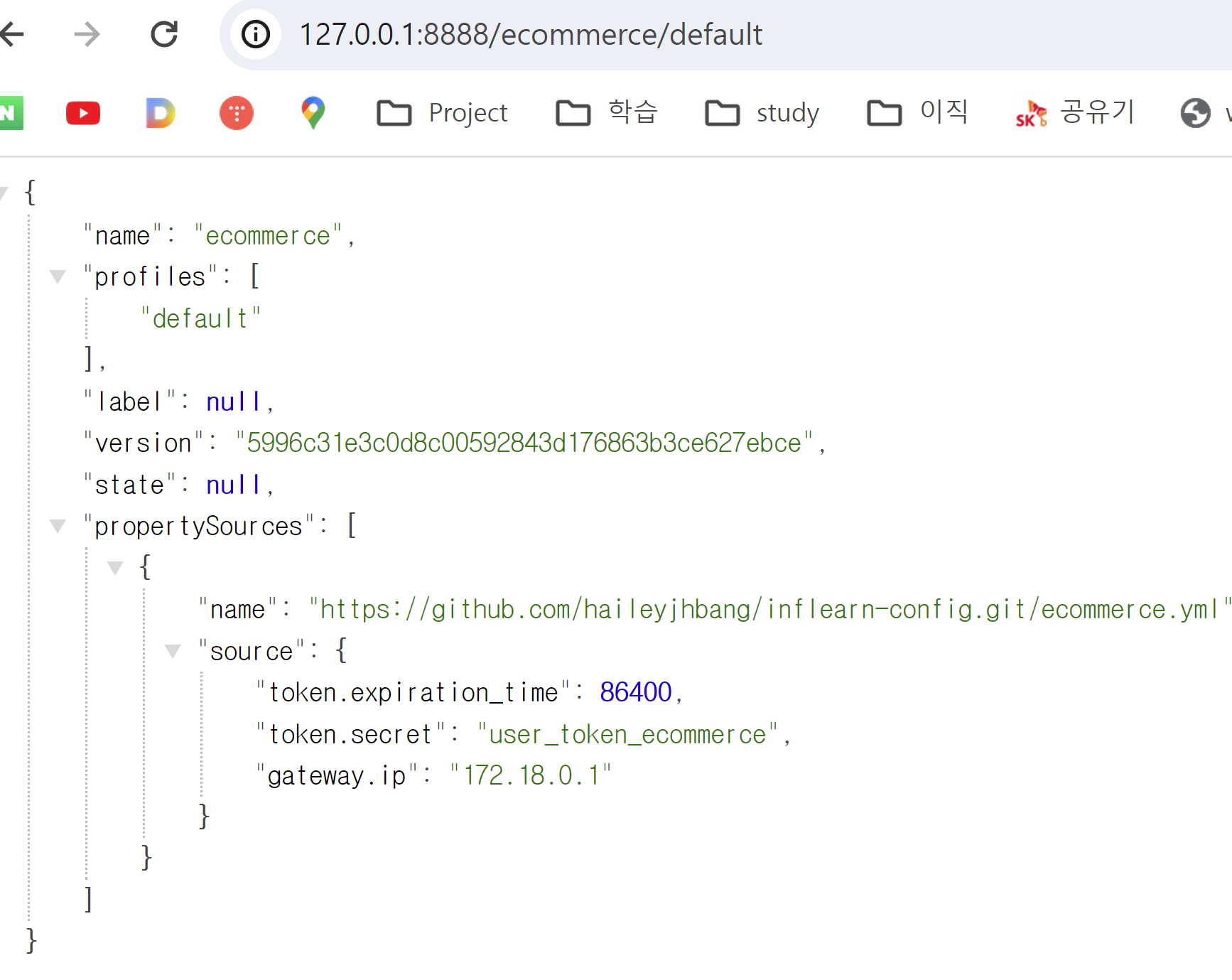
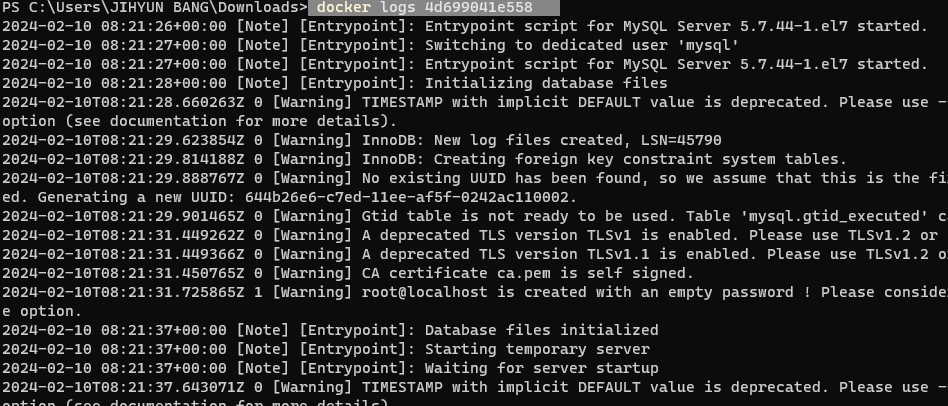
잘 떠있는지 로그 확인
docker logs config-service
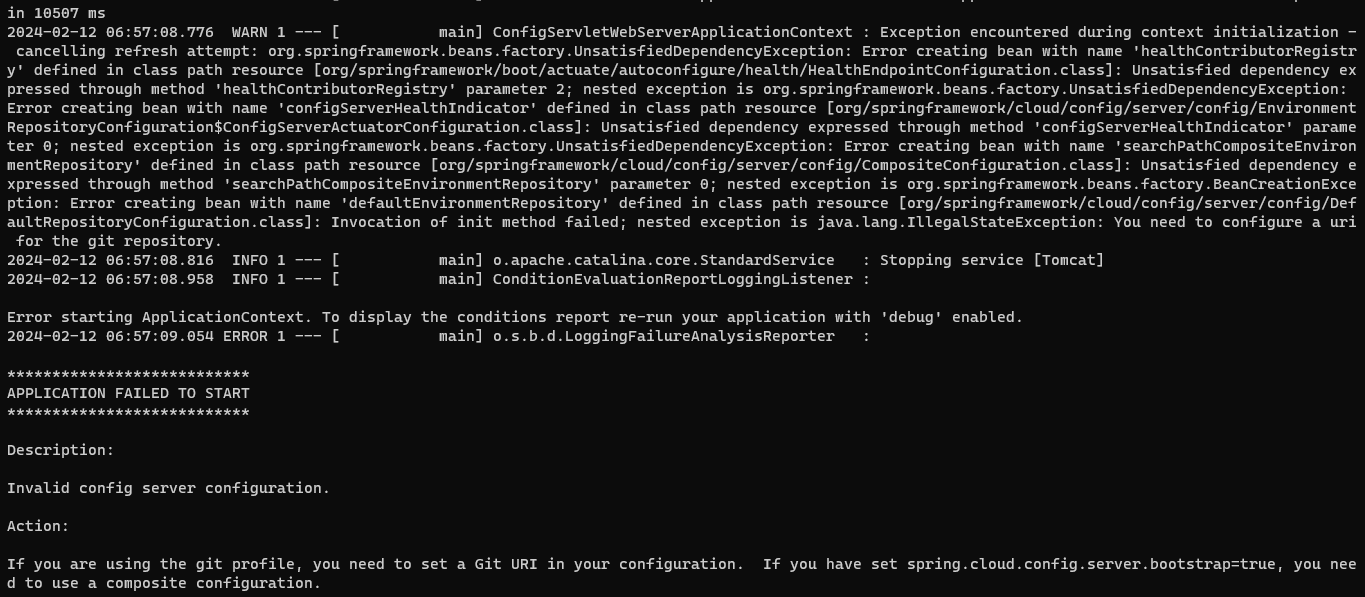
에러가 있음
Unsatisfied dependency expressed through method 'searchPathCompositeEnvironmentRepository' parameter 0; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'defaultEnvironmentRepository' defined in class path resource [org/springframework/cloud/config/server/config/DefaultRepositoryConfiguration.class]: Invocation of init method failed; nested exception is java.lang.IllegalStateException: You need to configure a uri for the git repository.
??
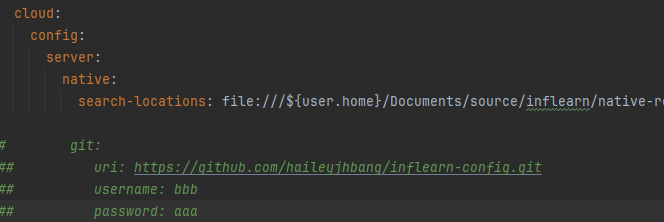
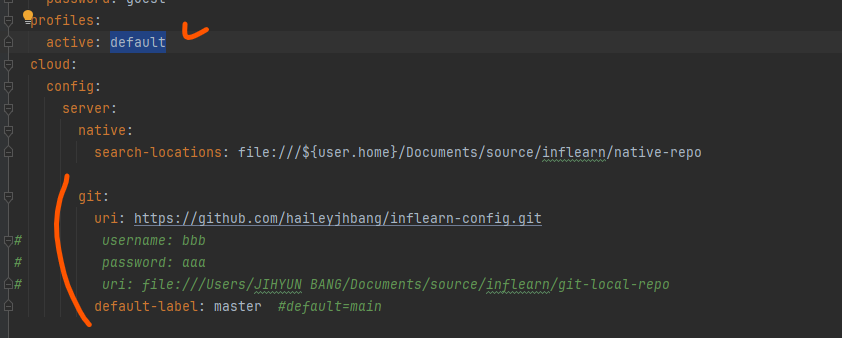
git repository 설정하라는 이상한 에러.
구글링 해보니 property 옵션을 native로 주라고.. 하여 native로 시작해 봄.
docker run -d -p 3306:3306 -e MYSQL_ALLOW_EMPTY_PASSWORD=true --name mysql mysql:5.7
//도커로 mysql:5.7을 백그라운드로 실행하는데
//포트 포워딩으로 호스트의 3306이랑 도커의 3306이랑 연결
//mysql5.7실행 시 필요한 설정을 -e옵션으로 주고
//이름을 mysql로 설정(아니면 랜덤)
docker pull ubuntu:16.04 //down
docker images | grep 16.04 //검색
docker run ubuntu:16.04 //실행 but 바로 종료
docker ps // 도커 컨테이너 실행중인것 확인
docker container ls -a //전체 히스토리 확인
docker container rm 컨테이너ID //컨테이너 삭제
2024-02-08 15:54:27.567 INFO [order-service,89bf1666da761e42,730648c3fe5dad8a] 4968 --- [o-auto-1-exec-4] c.e.o.controller.OrderController : before get orders
Hibernate: select order0_.id as id1_0_, order0_.created_at as created_2_0_, order0_.order_id as order_id3_0_, order0_.product_id as product_4_0_, order0_.qty as qty5_0_, order0_.total_price as total_pr6_0_, order0_.unit_price as unit_pri7_0_, order0_.user_id as user_id8_0_ from orders order0_ where order0_.user_id=?
2024-02-08 15:54:28.069 INFO [order-service,89bf1666da761e42,730648c3fe5dad8a] 4968 --- [o-auto-1-exec-4] c.e.o.controller.OrderController : after call orders msa