실시간으로 들어오는 데이터와 배치 처리가 필요한 대용량 데이터를 동시에 처리하는 구조를 제공하여, 빠른 응답성과 정확성을 모두 확보하는 데 중점을 둡니다. 데이터의 수집, 처리, 분석을 효과적으로 수행하기 위해 다음과 같은 3가지 계층으로 나뉩니다.
1. 배치 레이어 (Batch Layer)
역할: 대량의 데이터에서 정확한 집계와 분석을 위해 주기적인 배치 처리를 수행합니다.
특징: 배치 레이어에서는 데이터가 정해진 주기에 따라 한 번에 대량으로 처리됩니다. 이때 데이터의 불변성을 유지하여 전체 데이터를 매번 다시 계산해 정확도를 보장합니다.
사용 예: Hadoop, Apache Spark 등 분산 배치 처리 시스템.
장점: 모든 데이터를 기반으로 계산하기 때문에 데이터 손실이 없고 최종적으로 신뢰할 수 있는 결과를 제공합니다.
2. 실시간 레이어 (Speed Layer)
역할: 실시간으로 들어오는 데이터를 빠르게 처리하여 최신의 데이터에 대한 결과를 제공합니다.
특징: 배치 레이어가 대규모 데이터에 대해 전체적으로 정확한 처리를 수행하는 반면, 실시간 레이어는 최신 데이터에 대한 빠른 처리와 분석을 제공합니다. 이 레이어에서는 배치 레이어에서 처리된 데이터와 별도로 결과를 제공하여 빠르게 대응할 수 있도록 합니다.
사용 예: Apache Storm, Apache Kafka, Apache Flink.
단점: 실시간 처리는 모든 데이터를 종합하지 않기 때문에 정확도에 제한이 있을 수 있습니다.
3. 서빙 레이어 (Serving Layer)
역할: 배치 레이어와 실시간 레이어의 결과를 결합하여 사용자에게 최종적인 분석 결과를 제공합니다.
특징: 서빙 레이어는 배치 및 실시간 레이어에서 계산된 결과를 사용자에게 빠르게 응답할 수 있도록 구성됩니다. 두 레이어의 결과를 결합하여 정확하고 최신화된 정보를 제공하는 역할을 합니다.
사용 예: Apache HBase, Cassandra와 같은 NoSQL 데이터베이스.
람다 아키텍처의 장단점
장점
확장성: 대규모 데이터와 실시간 데이터를 모두 효율적으로 처리할 수 있어 시스템 확장이 용이합니다.
내결함성: 실시간 처리가 실패해도 배치 처리가 보완할 수 있는 구조입니다.
정확성: 실시간 데이터는 빠르게 처리하고, 배치 처리는 전체 데이터를 기준으로 정확도를 보장합니다.
단점
복잡성: 배치 레이어와 실시간 레이어를 동시에 관리하고 결합해야 하므로 시스템이 복잡해질 수 있습니다.
유지보수 부담: 실시간과 배치 두 가지 흐름을 동시에 관리해야 하므로 유지보수가 어려울 수 있습니다.
고민
배치로 중간 데이터를 만들었는데.. 지나고 이전 데이터가 들어온다면 지난 데이터를 버릴 건지 다시 배치를 돌릴 건지??
-> 카파 아키텍처(kappa)
카파 아키텍처(Kappa Architecture)는 대용량의 실시간 데이터 처리를 위해 설계된 아키텍처로, 람다 아키텍처의 복잡성을 줄이기 위해 제안되었습니다. 카파 아키텍처는 실시간 스트리밍 데이터의 분석과 처리를 중점으로 하며, 배치 레이어 없이 단일 데이터 처리 경로만을 사용하는 점이 특징입니다. 이는 시스템의 단순성과 유지보수를 고려한 접근 방식으로, 변화가 빠른 환경에서도 효율적으로 동작합니다.
카파 아키텍처의 주요 특징
단일 데이터 경로 (Single Pathway)
카파 아키텍처에서는 데이터를 오직 하나의 경로로 처리합니다. 이 데이터 경로는 실시간 스트리밍 처리를 위한 스트림 처리 엔진을 사용하며, 람다 아키텍처의 배치 레이어가 없는 구조입니다.
데이터가 들어오면 스트림 처리 시스템을 통해 처리되며, 필요한 경우 결과를 실시간으로 업데이트합니다.
실시간 데이터 처리
카파 아키텍처는 실시간 처리를 핵심으로 하여, 들어오는 데이터를 신속하게 처리하고 분석하는 데 집중합니다.
지속적인 스트림 데이터와 그 결과를 실시간으로 쌓아 두기 때문에 새로운 데이터에 빠르게 대응할 수 있습니다.
데이터의 불변성 유지
카파 아키텍처에서도 데이터는 원본 형태로 저장되고, 필요에 따라 재처리할 수 있도록 불변성을 유지합니다.
스트림 처리 엔진을 통해 재처리가 필요할 경우 저장된 원본 데이터를 다시 처리할 수 있습니다.
간단한 구조
배치 처리를 제거하고 스트림 처리를 중심으로 설계해 단순한 아키텍처를 유지합니다.
이는 개발 및 유지보수의 복잡성을 크게 줄여 주며, 특히 운영과 관리 측면에서 효율적입니다.
카파 아키텍처의 구현 방식
스트림 처리 엔진: 카파 아키텍처에서 중요한 역할을 하는 요소로, Apache Kafka, Apache Flink, Apache Samza 등이 자주 사용됩니다. 이들 엔진은 대용량의 스트리밍 데이터를 고성능으로 처리하는 데 적합합니다.
카프카에서 데이터를 재정렬, 필터링 등 여러 액션을 할 수 있음
데이터 저장소: 원본 데이터를 저장하는 시스템으로, Apache HBase, Cassandra, Elasticsearch와 같은 NoSQL 데이터베이스나 Kafka 같은 메시징 시스템이 사용됩니다.
Apache Iceberg 사용하는 추세
Apache Iceberg는 대규모 분석 데이터 테이블을 위한 고성능 오픈 소스 테이블 포맷입니다. Iceberg는 데이터를 대규모로 효율적으로 관리하고 처리할 수 있도록 설계되었으며, 특히 빅데이터 환경에서 기존 테이블 포맷의 문제를 해결하는 데 중점을 두고 있습니다. Iceberg는 데이터 레이크에서 다양한 저장소 및 파일 포맷을 지원하면서도 ACID 트랜잭션을 제공하고, 강력한 스키마 관리와 높은 쿼리 성능을 제공합니다.
과거와 현재 데이터를 중간에 스냅샷을 찍어서 관리하는 구조
카파 아키텍처의 장단점
장점
단순성: 배치 레이어를 제거하고 스트림 처리만 사용하여 시스템 구조가 단순합니다.
빠른 대응: 실시간 데이터를 실시간으로 처리할 수 있어 최신 데이터를 활용한 분석이 용이합니다.
유지보수 용이: 단일 데이터 경로만 관리하므로 복잡한 유지보수 작업을 줄여줍니다.
읽기 속도가 좋고 람다보다 유연
단점
재처리 문제: 배치 처리가 없기 때문에 모든 데이터를 실시간으로 처리하며, 재처리가 필요한 경우 스트림 처리 엔진에 추가적인 부담이 될 수 있습니다.
적용 한계: 대용량 데이터의 정확한 분석이 필요하거나 일괄처리가 필요한 환경에서는 적합하지 않을 수 있습니다.
카파 아키텍처 vs 람다 아키텍처
카파 아키텍처는 람다 아키텍처와는 달리 실시간 스트리밍 처리만을 사용하여 시스템을 단순화합니다. 이를 통해 람다 아키텍처에서 필요했던 두 경로의 중복 코드나 복잡한 데이터 일관성 유지 문제를 해결할 수 있습니다. 그러나 재처리나 정밀한 배치 처리가 필요한 환경에서는 여전히 람다 아키텍처가 유리할 수 있습니다.
public interface OrderRepository extends JpaRepository<Order, Long> {
//get, read, query, find -> select문
//All -> 의미 없음; 뭘 가져올지는 return type으로
//by -> 조건
@EntityGraph("orderWithCustomer")
//select * from order left join customer -> 커스토머 가져오고
//select * from orderItem left join item -> 추가로 발생
List<Order> getAllBy();
@EntityGraph("orderWithOrderItems")
//select * from order left join orderItem -> 한방에
List<Order> readAllBy();
@EntityGraph("orderWithCustomerAndOrderItems")
//select * from order left join customer left join orderItem -> 한방에
List<Order> queryAllBy();
@EntityGraph("orderWithCustomerAndOrderItemsAndItem")
//select * from order left join customer left join orderItem left join item -> 한방에
List<Order> findAllBy();
}
Pagination 쿼리에 Fetch Join
Pagination 쿼리에 Fetch Join을 적용하면 실제로는 모든 레코드를 가져오는 쿼리가 실행된다
: 다 가져와서 필요한 부분만 발라서 줌
: DB 서버는 전체를 부르게 되니 부하 오짐
실제로는 에러가 아닌 warning에 아래와 같은 메세지가 나고 있었다..
디비에서는 다가져와서 메모리에서 할게 ㅎㅎ
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
cf.) pagination query 에서 offset, limit 에 bind 된 parameter 값은 왜 log에 안 나오죠?
limit 뒤의 값을 알고싶어요..
select
order0_.order_id as order_id1_3_,
order0_.customer_id as customer3_3_,
order0_.order_dt as order_dt2_3_
from orders order0_
where
order0_.order_id=?
limit ?
o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [1]
Hibernate는 collection type으로 list, set, bag, map 등 다양한 타입을 지원
Java의 java.util.List 타입은 기본적으로 Hibernate의Bag타입으로 맵핑됨
Bag은 Hibernate에서 중복 요소를 허용하는 비순차(unordered) 컬렉션
둘 이상의 컬렉션(Bag)을 Fetch Join하는 경우, 그 결과로 만들어지는 카테시안 곱(Cartesian Product)에서 어느 행이 유효한 중복을 포함하고 있고 어느 행이 그렇지 않은 지 판단할 수 없어 Bag컬렉션으로 변환될 수 없기 때문에 MultipleBagFetchException 예외 발생
조인 할 때 row에 옆으로 쫙 늘어나면서 데이터가 n*n으로 나올거잖슴,, 반복되는 내용 때문인지 중복이 왜 나는지 구분이 안되니
Hibernate:
create table order_attributes (
order_attribute_id bigint generated by default as identity,
attribute varchar(255),
order_id bigint,
attributes_order integer, ///순서를 저장하기 위한 콜롬이 추가로 생성된
primary key (order_attribute_id)
)
Hibernate:
create table order_items (
order_line_id bigint generated by default as identity,
quantity bigint,
item_id bigint,
order_id bigint,
order_items_order integer, ///순서를 저장하기 위한 콜롬이 추가로 생성된
primary key (order_line_id)
)
1, 2번으로 해결이 안되면 Jpa를 쓰지말자! ㅋㅋ
Repository: spring이 제공하는 데이터에 접근하는 layer
Spring Data Repository
Repository는 JPA의 개념이 아니고, Spring Framework가 제공해주는 것임.
data access layer 구현을 위해 반복해서 작성했던, 유사한 코드를 줄일 수 있는 추상화 제공
이름 규칙으로 join 쿼리 가져오기(N+1 날 수 있음)
public interface MemberRepository extends JpaRepository<Member, Long> {
// select m from Member m inner join MemberDetail md where md.type = ?
// 연관관계가 있을때만 가능
// _ 로 안으로 들어갈 수 있음
List<Member> findByDetails_Pk_Type(String type);
}
DTO Projection
DTO Projection 이란: entity 바를 때
Repository 메서드가 Entity를 반환하는 것이 아니라 원하는 필드만 뽑아서 DTO(Data Transfer Object)로 반환하는 것
메모리나 디비 성능에 도움
Dto Projection 방법
Interface 기반 Projection: 아래에 계속!
Class 기반 (DTO) Projection: 생성자
Dynamic Projection: runtime에 결정
트러블 슈팅 - Spring Data Repository 로는 Dto Projection을 할 수 없다?
Spring Data Repository를 이용한 Dto Projection
Repository 메서드의 반환 값으로 Entity가 아닌 Dto를 사용할 수 있다
interface / class
@Value+ SpEL (target)
public interface OrderRepository extends OrderRepositoryCustom, JpaRepository<Order, Long> {
List<OrderDto> findAllBy();
}
public interface OrderDto {
Long getOrderId();
CustomerDto getCustomer();
List<OrderItemDto> getOrderItems();
interface CustomerDto {
String getCustomerName();
}
interface OrderItemDto {
ItemDto getItem();
Long getQuantity();
}
interface ItemDto {
String getItemName();
Long getItemPrice();
}
}
Hibernate:
select
order0_.order_id as order_id1_3_,
order0_.customer_id as customer3_3_,
order0_.order_dt as order_dt2_3_
from
orders order0_
Hibernate:
select
customer0_.customer_id as customer1_0_0_,
customer0_.customer_name as customer2_0_0_
from
customers customer0_
where
customer0_.customer_id=?
Hibernate:
select
customer0_.customer_id as customer1_0_0_,
customer0_.customer_name as customer2_0_0_
from
customers customer0_
where
customer0_.customer_id=?
Hibernate:
select
orderitems0_.order_id as order_id4_2_0_,
orderitems0_.order_line_id as order_li1_2_0_,
orderitems0_.order_line_id as order_li1_2_1_,
orderitems0_.item_id as item_id3_2_1_,
orderitems0_.quantity as quantity2_2_1_,
item1_.item_id as item_id1_1_2_,
item1_.item_name as item_nam2_1_2_,
item1_.item_price as item_pri3_1_2_
from
order_items orderitems0_
left outer join
items item1_
on orderitems0_.item_id=item1_.item_id
where
orderitems0_.order_id=?
Hibernate:
select
orderitems0_.order_id as order_id4_2_0_,
orderitems0_.order_line_id as order_li1_2_0_,
orderitems0_.order_line_id as order_li1_2_1_,
orderitems0_.item_id as item_id3_2_1_,
orderitems0_.quantity as quantity2_2_1_,
item1_.item_id as item_id1_1_2_,
item1_.item_name as item_nam2_1_2_,
item1_.item_price as item_pri3_1_2_
from
order_items orderitems0_
left outer join
items item1_
on orderitems0_.item_id=item1_.item_id
where
orderitems0_.order_id=?
Hibernate:
select
orderitems0_.order_id as order_id4_2_0_,
orderitems0_.order_line_id as order_li1_2_0_,
orderitems0_.order_line_id as order_li1_2_1_,
orderitems0_.item_id as item_id3_2_1_,
orderitems0_.quantity as quantity2_2_1_,
item1_.item_id as item_id1_1_2_,
item1_.item_name as item_nam2_1_2_,
item1_.item_price as item_pri3_1_2_
from
order_items orderitems0_
left outer join
items item1_
on orderitems0_.item_id=item1_.item_id
where
orderitems0_.order_id=?
JPA 연관관계도 내부적으로 FK 참조를 기반으로 구현하므로 본질적으로 참조의 방향은 단방향
단방향에 비해 양방향은 복잡하고 양방향 연관관계를 맵핑하려면 객체에서 양쪽 방향을 모두 관리해야 함
물리적으로 존재하지 않는 연관관계를 처리하기 위해 mappedBy 속성을 통해 관계의 주인을 정해야 함
단방향을 양방향으로 만들면 반대 방향으로의 객체 그래프 탐색 가능
우선적으로는 단방향 맵핑을 사용하고 반대 방향으로의 객체 그래프 탐색 기능이 필요할 때 양방향을 사용
일반적으로 단방향으로도 충분하지만 그게 아닌 경우가 있다.
일대다 연관관계 시 '다'에 해당하는 양만큼 update문이 나갈 수 있음 -> 양방향 연관관계 필요
복합키까지 쓰는 경우라면, 그리고 그 값이 FK에도 쓰는 경우라면 @MapsId로 지정해야 한다.
예시: 단방향으로 설정 시 원치 않은 update문이 나갈 수 있음
class Member{
...
@OneToMany(cascade = CascadeType.ALL) //member 바뀌면 아래도 알아서 바뀌라
@JoinColumn(name = "member_id")
private List<MemberDetail> details = new ArrayList<>();
}
//CASCADE 넣으면 이거 하나로 끝
memberRepository.save(member);
Hibernate: insert into members (create_dt, name, member_id) values (?, ?, ?)
Hibernate: insert into member_details (description, type, member_detail_id) values (?, ?, ?)
Hibernate: insert into member_details (description, type, member_detail_id) values (?, ?, ?)
Hibernate: update member_details set member_id=? where member_detail_id=?
Hibernate: update member_details set member_id=? where member_detail_id=?
insert 할 때 한 번에 하면 되지 않나 왜 update를?
해결: 양방향 일대다(1:N)로 변경
class Member{
...
@OneToMany(cascade = CascadeType.ALL, mappedBy = "member")
private List<MemberDetail> details = new ArrayList<>();
}
//
class MemberDetail{
...
@ManyToOne
@JoinColumn(name = "member_id")//column이름; 양방향일 때 관계 주인은 fk를 가지고 있는 여기!
private Member member;
}
///
//양방향이기 때문에 양쪽으로 다 세팅해야 함
memberDetail1.setMember(member);
member.getDetails().add(memberDetail1);
Repeated column in mapping for entity: com.jpa.entity.MemberDetail column: member_id (should be mapped with insert="false" update="false")
근데 에러가 남 두둥
@Entity
@Table(name = "MemberDetails")
public class MemberDetail {
@EmbeddedId
private Pk pk;
private String description;
@ManyToOne
@JoinColumn(name = "member_id")///
private Member member;
@Getter
@Setter
@NoArgsConstructor
@EqualsAndHashCode
@Embeddable
public static class Pk implements Serializable {
@Column(name = "member_id") ////
private Long memberId;
private String type;
}
}
그러면 이렇게 하면 될까? nope! 왜냐면 cascade 때문에. 그걸로 업데이트/인서트 하겠다고 한 건데 안 하겠다고 하면(updatable false) 안되지
그렇다면?
@ManyToOne
@MapsId("memberId")
private Member member;
pk에도 쓰이는 칼럼이 @JoinColumn에서도 써야 한다면, 같은 거를 쓴다고 알려줘야 함
MapsId 만 써도 되는데 PK가 복합키라서 그중에 뭐? 를 알려줘야 할 때
PK에서 사용되는 콜롬이 FK에도 쓰인다! @MapsId(변수명)
그러면 insert 세 개만 나간다!
정리: 양방향을 맺자
@Entity
@Table(name = "Orders")
public class Order {
...
@OneToMany(mappedBy = "order", cascade = CascadeType.Merge, CasecadeType.PERSIST)//order 저장 시 detail도 저장하게 하려면 여기다가 cascade option 필요
private List<OrderDetail> details = new ArrayList<>();
}
////
@Entity
@Table(name = "OrderDetails")
public class OrderDetail {
...
@EmbeddedId
private Pk pk = new Pk();
@ManyToOne
// @JoinColumn(name = "order_id") //원래대로라면 이렇게 하지만 PK에도 사용되니..
@MapsId("orderId")
private Order order;
@Getter
@Setter
@NoArgsConstructor
@EqualsAndHashCode
@Embeddable
public static class Pk implements Serializable {
@Column(name = "order_id")
private Long orderId;
private String type;
}
}
////
@Transactional
public void doSomething() {
Order order = new Order();
order.setOrderDate(LocalDateTime.now());
OrderDetail orderDetail1 = new OrderDetail("type1");
orderDetail1.setDescription("order1-type1");
orderDetail1.setOrder(order);
OrderDetail orderDetail2 = new OrderDetail("type2");
orderDetail2.setDescription("order1-type2");
orderDetail2.setOrder(order);
order.getDetails().add(orderDetail1);
order.getDetails().add(orderDetail2);
orderRepository.save(order); ///여기서 한번만 해도 detail이 들어가려면 Cascade가 필요한 것이다!
}
N + 1 문제
JPA에서 N+1 문제는 자식 엔티티가 얼마나 있는지에 관계없이 부모 엔티티 개수에 따라 추가적인 쿼리가 발생하기 때문에, 자식 엔티티의 개수와는 상관이 없습니다. 이 문제는 정확히 부모 엔티티의 개수와 관련이 있습니다. 좀 더 명확히 설명하자면 다음과 같습니다:
1. N+1 문제의 본질
N+1 문제란, 부모 엔티티를 조회하는 1번의 쿼리와, 각 부모 엔티티에 대해 자식 엔티티를 조회하기 위한 N번의 추가 쿼리가 발생하는 문제를 의미합니다. 여기서 N은 부모 엔티티의 개수를 의미합니다.
1번의 쿼리: 부모 엔티티를 조회하는 쿼리입니다.
N번의 쿼리: 각 부모 엔티티마다 자식 엔티티를 조회하는 쿼리가 발생하는 것입니다.
이 문제는 자식 엔티티의 수가 아니라, 부모 엔티티의 수만큼 추가적인 쿼리가 발생하는 것이 문제의 핵심입니다.
2. 부모 1건, 자식 여러 건의 경우
부모 엔티티가 1건이라면 자식 엔티티가 아무리 많더라도, 부모 엔티티를 조회한 후 자식 엔티티를 조회하기 위한 쿼리가 단 1번 발생합니다.
@Entity
public class Parent {
@Id
private Long id;
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY)
private List<Child> children;
}
@Entity
public class Child {
@Id
private Long id;
@ManyToOne
@JoinColumn(name = "parent_id")
private Parent parent;
}
쿼리 한 번으로 N 건의 레코드를 가져왔을 때, 연관관계 Entity를 가져오기 위해 쿼리를 N번 추가 수행하는 문제
@Entity
@Table(name = "Orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "order_id")
private Long orderId;
@ManyToOne(optional = false) //eager -> join
@JoinColumn(name = "customer_id")
private Customer customer;
@Column(name = "order_dt")
private LocalDateTime orderDate;
@OneToMany(cascade = CascadeType.ALL) //lazy 아직..
@JoinColumn(name = "order_id")
private List<OrderItem> orderItems;
}
//
@Entity
@Table(name = "OrderItems")
public class OrderItem {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "order_line_id")
private Long orderLineId;
@ManyToOne
@JoinColumn(name = "item_id")
private Item item;
private Long quantity;
}
public void getOne() {
//단건은 연관관계 매핑을 고려해서 join사용
orderRepository.findById(1L);
}
public void getMulti() {
//findall은 명확하게 모르는 쿼리를 날리면 우선 실행하고 연관관계매핑을 적용
orderRepository.findAll();
}
단 건을 실행하면 join으로 한 번에 가져오는데
findAll실행하면 우선 order 실행하고 eager인 customer 실행
Hibernate:
select
order0_.order_id as order_id1_3_,
order0_.customer_id as customer3_3_,
order0_.order_dt as order_dt2_3_
from
orders order0_
//
select
customer0_.customer_id as customer1_0_0_,
customer0_.customer_name as customer2_0_0_
from
customers customer0_
where
customer0_.customer_id=?
//
select
customer0_.customer_id as customer1_0_0_,
customer0_.customer_name as customer2_0_0_
from
customers customer0_
where
customer0_.customer_id=?
feachType의 문제가 아니야!
해결 방법
Fetch Join
join을 사용하여 쿼리 하나로 실행하겠다.
JPQLjoin fetch
fetch 없으면, from절에 있는 메인 엔티티만 반환. 우선 진행시켜! 그 후에 from절 전에 있는 메인 엔티티를 하나씩 따져보면서 다시 N+1 실행
fetch를 써야 select절에 다른 것들도 받음
QuerydslfetchJoin()
그룹화하여 쿼리 실행 횟수를 줄이겠다.
Entity Graph //선언적으로 어디까지 탐색할 수 있는지 지정가능
그 외
Hibernate @BatchSize //나눠서
Hibernate @Fetch(FetchMode.SUBSELECT) //in절에 넣어서 실행
주의. 그지 같은 join문으로 인해.. 성능이 더 나빠질 수 있음.
@Query("select o from Order o "
+ " inner join fetch o.customer as c "
+ " left join fetch o.orderItems as oi "
+ " inner join fetch oi.item as i")
List<Order> getOrdersWithAssociations();
Querydsl
복잡한 쿼리 작성 시 컴파일러의 도움을 받을 수 있음
JPA에서 제공하는 객체 지향 쿼리
JPQL: Entity 객체를 조회하는 객체 지향 쿼리 // text 기반이라 compiler의 도움을 못 받음
Criteria API: JPQL을 생성하는 빌더 클래스 //복잡함
third party library를 이용하는 방법
Querydsl
jOOQ //native query 기반
…
JPQL vs Criteria API
JPQL
SQL을 추상화해서 특정 DBMS에 의존적이지 않은 객체지향 쿼리
문제 : 결국은 SQL이라는 점
문자 기반 쿼리이다 보니 컴파일 타임에 오류를 발견할 수 없다
Criteria API
프로그래밍 코드로 JPQL을 작성할 수 있고 동적 쿼리 작성이 쉽다
컴파일 타임에 오류를 발견할 수 있고 IDE의 도움을 받을 수 있다
문제 : 너무 복잡
Querydsl
Criteria API처럼 정적 타입을 이용해서 JPQL을 코드로 작성할 수 있도록 해 주는 오픈소스 프레임워크
Spring Data Repository 추상화 덕분에 interface 선언만으로도 쿼리 생성 가능
interface에 선언된 메서드의 실제 구현체는 아래 순서로 탐색하게 된다
기본 구현체(JpaRepository의 구현체인 SimpleJpaRepository::saveAll etc.)
메서드 이름 규칙 적용 (cf. 메서드 이름으로 쿼리 생성 findByNameLikeAndPhone etc.)
Custom Repository Implementation
MemberRepositoryImpl -> MemberRepositoryCustomImpl 로 바꾸면? O
OrderRepositoryImpl -> OrderRepositoryCustomImpl 로 바꾸면? O
Repository Fragment 를 이용한 Custom Repository 구현
: 최근에 바뀜; 하나의 커스텀 레파지토리에 다 넣을 필요 없이 여러개로 구현체를 나눠서 구현 가능(repository fragment)
: 나눠서 구현하고 주 repository에 상속하듯 사용해도 된다
Repository Fragment 를 이용한 Custom Repository
// no `@NoRepositoryBean`
public interface CustomizedMemberRepository {
List<Member> getMembersWithAssociation();
}
// NOT MemberRepository + `Impl`
// BUT **CustomizedMemberRepository** + `Impl`
public class CustomizedMemberRepositoryImpl implements CustomizedMemberRepository {
// ...
}
여러 개의 Custom Repository 구현 가능
앞서 본CustomizedMemberRepositoryinterface와CustomizedMemberRepositoryImplclass 와 같이
예를 들면GuestRepositoryinterface,GuestRepositoryImplclass 같이 여러 개의 Custom Repository 구현 가능
Custom Repository 들로 구성된 Repository
public interface MemberRepository
extends CustomizedMemberRepository, GuestRepository {
}
참고) @Repository 어노테이션이란(not jpa 과거에..)
방식: streotype bean -> 해당 이름으로 된 빈들을 찾아서 자동으로 등록
그러나 jpa는.. 그 방식이 아니고
interface extends JpaRepository -> 다 뒤져서 jpa 후보군으로 등록
@NoRepositoryBean -> 그 후보군에서 빼줘
Qtype이 안 생겨서 -> no complie... -> 못 찾으면.. 세상 망함.. 온 세상이 빨개요..
cf.) 트러블 슈팅 - Querydsl Q-type class variable로 "member"나 "order"를 쓸 수 없다?!
Querydsl에서 Q-type class 인스턴스 생성 시 variable을 "member"로 주면 에러 발생
예제
QMember member = new QMember("member");
QOrder order = new QOrder("order");
unexpected token: member
unexpected token: order
이유
JPQL에MEMBER OF연산자가 있기 때문에MEMBER가 예약어라 variable에 쓸 수 없음
@Query("SELECT m FROM Member m WHERE :detail MEMBER OF m.details")
Member getMemberContainingDetail(MemberDetail detail);
마찬가지로 JPQL에ORDER BY연산자가 있기 때문에ORDER가 예약어라 variable에 쓸 수 없음
해결방법
아래 코드에서 각각의 Q-type class의 static 변수는 variable 값이 뭐라고 되어 있을까?
QMember member = QMember.member;
QOrder order = QOrder.order;
member, order :: 예약어; 다른걸로 쓰면 된다.
소스를 까보면 지들도 member를 회피하기 위해 member1로 쓰고있음
@Generated("com.querydsl.codegen.DefaultEntitySerializer")
public class QMember extends EntityPathBase<Member> {
private static final long serialVersionUID = 1029385075L;
public static final QMember member = new QMember("member1"); /// member를 회피하기 위한
22년 초에 restTemplate을 사용하는 프로젝트를 작업하다가 위 문구를 보게 되었다.
음..? 잘 쓰고 있던 rest template이 deprecated 된다고?
그래서 그 이후에 신규로 진행하는 프로젝트는 webClient를 사용하였다.
왜 webClient를 사용하였냐고 물으신다면, 위에서처럼 굳이 spring java doc에 대체하여 쓰라고 할 정도니, 스프링 진영에서 정식으로 밀고 있는 것이라 생각했기 때문이다(곧 대세가 될 것이라 생각했다).
참고로 webClient는 springframework 5에 추가된 것으로 기본적으로 reactive, non-blocking 요청을 지원한다(그래서 응답이 Mono, Flux 등으로 온다).
무튼 그렇게 webClient를 신규 프로젝트들에서 사용하게 되는데, 설정과 사용 시 상당한 라인의 코드가 필요한 것을 깨닫게 되었다.
공통 설정을 빈에 등록하는 코드, 그걸 가져와서 서비스마다 주입을 하고, 주입된 webClient로 get/post 등의 요청을 하는데도 상당한 코드가 필요하다.
get 사용 예시
물론 공통화하여 사용하고 있기는 하지만 외부 api가 새로 추가할 때마다 비슷한 양을 추가해야 한다.
사실 처음에는 webClient를 사용함으로써 webFlux에 친숙해지고, 궁극적으로는 non-blocking 요청에 대한 친근감(..)이 생기지 않을까 하는 마음이 컸다. 하지만 업무에서는 실질적으로 동기 요청이 훨씬 많았고, 이를 위해 억지로 mono.block()을 하고 있어 코드 양만 늘어난 샘이 되었다.. 결국 제대로 활용하지 못하고 있다는 생각이 들었다.
그렇게 시간이 지나고 22년 11월 springframework6이 정식(GA) 출시하면서 진짜 restTemplate에 @Deprecated가 달렸는지 궁금해졌다.
그런데 새로운 프래임워크를 열어보기도 전, 현재 사용하는 프로젝트(springboot2.7.3; springframework 5.3)에서 먼저 확인하니 안내 문구가 바뀌어져 있었다?
(확인해 보니 springframework3, 4에는 안내하는 javadoc 조차 없음)
NOTE: As of 5.0 this class is in maintenance mode, with only minor requests for changes and bugs to be accepted going forward. Please, consider using the org.springframework.web.reactive.client.WebClient which has a more modern API and supports sync, async, and streaming scenarios.
webClient를 추천하는 문구는 그대로인데.. deprecated 된다는 말은 쏙 빠지고, 유지보수모드(간단한 버그수정만 지원)로 전환한다는 말로 바뀌어져 있었다.요 녀석들.. 고도의 밑장 빼기인가..
위에서 webClient를 사용하면서도 굳이 이걸 써야하는가? 다음 프로젝트에서도 또 webClient를 쓸 것인가? 대해 의문을 가지고 있었는데.. 마침 springframework6 문서에서 Http interface에 대한 글을 보게 된다.
2. 이 interface의 구현체는 스프링으로 부터 자동으로 생성되는데, 아래와 같이 빈을 등록해야 한다.
@Configuration
public class GiaHttpConfig {
@Bean
GiaArenaRingService getGiaArenaRingService(@Value("${gia-aapoker-dev}") String url) {
WebClient client = WebClient.builder().baseUrl(url).build();
HttpServiceProxyFactory factory = HttpServiceProxyFactory.builder(WebClientAdapter.forClient(client)).build();
GiaArenaRingService service = factory.createClient(GiaArenaRingService.class);
return service;
}
}
3. 사용하고자 하는 곳에서 이 빈을 주입한 후 해당 함수를 호출하면 된다.
@Service
@RequiredArgsConstructor
public class ExternalService {
private final GiaArenaRingService giaArenaRingService;
public Map<String, Object> getArenaRingGameHttpInterface(BigInteger id) {
return giaArenaRingService.getArenaRingGame(id);
}
}
끝.
예시는 바로 객체를 꺼내 오도록 했으나 기존의 webClient처럼 Mono나 Flux로 반환하게끔 할 수도 있다(support both blocking and reactivereturn values).
사용법이 간단하고 api 스펙을 interface로 선언하기만 하면 되어 한눈에 볼 수 있다는 장점이 있는 것 같다.
webClient 기반이라 기존 webClient에서 지원하던 기능들은 설정방식만 조금 다를 뿐 다 지원할 듯하다.
가독성이 떨어지고 코드의 양이 많았던 webClient의 단점을 어느 정도 보완해 줄 수 있을 것 같아 기회가 되면 사용해 볼 생각.
@ModelAttribute는 폼 데이터나 쿼리 파라미터에서 값을 받아서 Java 객체로 바인딩합니다.
일반적으로 필요한 요소:
기본 생성자 (No-args Constructor): 필수 @ModelAttribute는 데이터 바인딩을 위해 기본 생성자를 사용합니다. 기본 생성자가 없으면 바인딩이 불가능합니다.
Getter/Setter 메서드: 필수 @ModelAttribute는 요청 데이터(폼 데이터나 쿼리 파라미터)를 필드에 바인딩할 때, 객체 필드에 직접 접근하지 않고 setter 메서드를 사용합니다. 따라서 필드마다 setter가 필요합니다. 또한, 검증 후 데이터를 읽어올 때는 getter가 필요합니다.
1. NoArgsConstructor로 객체 생성 후 Setter로 주입
setter가 없다면 값을 넘겨도 null로 세팅된다.
setter로 변수 이름 변경 가능하다.(받는 변수명은 idSeq -> 바인딩하는 변수는 seq 로 가능)
@Setter
public class ReceivedUserRequest {
@NotBlank
private String mailIdx;
}
2. public AllArgsConstructor 로 주입
public class ReceivedUserRequest {
@NotBlank
private String mailIdx;
public ReceivedUserRequest(String mailIdx) {
this.mailIdx = mailIdx;
}
}
Spring은 때때로 생성자 기반 바인딩을 사용할 수 있으며, 이는 주로 다음과 같은 상황에서 발생합니다:
폼 데이터나 URL 파라미터에서 넘어오는 값이 모든 필드에 전달될 때.
객체 생성 시 한 번에 모든 필드를 초기화할 수 있는 AllArgsConstructor가 있는 경우.
> deserialize 자체에는 getter가 없어도 됨(그렇지만 결국 serialization 하다가 필요해서 에러가 남 ㅋㅋ)
Java implicitly adds a no-arg constructor to all classes when there is no constructors defined. If you define any parameterized constructor then the no-arg constructor will not be added.
You need a default constructor (constructor without any argument) in entities. This is needed because JPA/Hibernate uses the default constructor method to create a bean class using reflections. If you don't specify any constructor (nor Lombok annotation), Java will generate a default constructor (automatically generated by the compiler if no constructors have been defined for the class). But if you add a constructor with parameters (or @AllArgsConstructor), then you'll need to add a no args constructor (or @NoArgsConstructor) as well, for JPA/Hibernate to work.
POST mapping
request body -> object
참고로 아래 지식이 필요하다.
When using JSON format, Spring Boot will use an ObjectMapper instance to serialize responses and deserialize requests.
<getter/setter/constructor 없이 매핑을 시도하면 에러가 난다>
2. @RequestBody의 DTO 요구 사항
@RequestBody는 JSON 또는 XML과 같은 요청 본문을 Java 객체로 **역직렬화(deserialize)**합니다. @RequestBody는 JSON 데이터를 객체 필드에 직접 바인딩하는 방식이므로 필드 접근 방식이 조금 다릅니다.
필요한 요소:
기본 생성자 (No-args Constructor): 필수 아님 @RequestBody는 JSON 데이터를 역직렬화할 때 Jackson 라이브러리를 사용합니다. Jackson은 기본 생성자를 사용하거나, @JsonCreator 어노테이션을 사용하여 특정 생성자를 통해 객체를 생성할 수 있습니다. 하지만, 기본적으로 기본 생성자가 있는 것이 편리합니다.
Getter/Setter 또는 필드 접근: 필수는 아님 Jackson은 JSON 데이터를 객체로 변환할 때 필드 또는 Getter/Setter를 통해 값을 설정합니다. 필드가 public이라면 직접 필드에 접근할 수도 있지만, 일반적으로 getter/setter를 통해 데이터를 주고받는 것이 더 안전합니다.
1. setter가 없을 경우, (역직렬화에 setter가 사용되기 때문에)
값을 보내도 null로 인식하여 @NotNull validation이 실패한다.
Field error in object 'cancelRequest' on field 'mailIdx': rejected value [null]; codes [NotBlank.cancelRequest.mailIdx,NotBlank.mailIdx,NotBlank]
2. 또한 역직렬화 시 기본 생성자 생성 후 setter를 사용하기 때문에
@NoArgsConstructor나 @AllArgsConstructor가 아닌 일부 생성자만 있는 경우는 아래 에러가 난다.(둘 중 하나만 있어도 매핑이 잘 된다)
cannot deserialize from Object value (no delegate- or property-based Creator)
3. @Getter가 없을 경우, 역직렬화는 문제가 없지만 후에 직렬화 과정에서 null로 내려간다.
역직렬화 / 직렬화에 대해 정리하자면 아래와 같다.
역직렬화는 기본적으로 다음과 같은 과정을 거쳐서 처리된다. - object mapper 사용 - 기본 생성자로 객체를 생성함 -> 기본 생성자가 없으면 에러 -필드값을 찾아서 값을 바인딩해줌 -> public 필드 또는 public 형태의 setter로 바인딩
직렬화는 다음과 같다. - Spring에서는 기본적으로 jackson 모듈의 ObjectMapper라는 클래스가 직렬화를 처리하며 ObjectMapper의 writeValueAsString이라는 메서드가 사용됨 - ObjectMapper는 public 필드 또는 public 형태의 getter로 값을 가져옴
> 직렬화에 대해 조금 더 깊숙이 들어가면..
application/json타입의 데이터는 스프링부트의 MessageConverter -> MappingJackson2HttpMessageConverter -> Jackson 라이브러리의 Object mapper클래스를 이용해 Reflection으로 객체를 생성하게 된다. 이때 기본 생성자가 없을 경우 Jackson 라이브러리가 deserialize 할 수 없어 예외가 발생한다.
@TestConfiguration
public class TestDataSourceConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}
@Sql({"classpath:maalog/item-log.sql", "classpath:maalog/item-withdraw-log.sql"})
@Import(TestDataSourceConfig.class)
@DataJpaTest
class ItemLogRepositoryTest {
@Autowired
private ItemLogRepository itemLogRepository;
@Test
void givenValidateData_whenFindBySeq_thenSuccess() {
var result = itemLogRepository.findBySeq(BigInteger.valueOf(22L)).get();
assertThat(result, notNullValue());
assertThat(result.getInvenSeq(), is(BigInteger.valueOf(0)));
}
4. 통합검증
외부 api는 나에게 제어권이 없기 때문에 mocking으로 테스트가 충분하다고 생각했고
디비는 내가 제어할 수 있기 때문에 통합테스트가 필요할 수 있다고 느꼈다.
근데 운영은 다중 디비지만 테스트는 로컬 하나의 디비라서 설정이 까다로웠고.. 아래와 같이 다중 디비 연결 관련 설정을 오버라이드하기 위해 해당 위치에 빈 설정을 넣어줘야 했다.
아 쿼리 dsl 관련 빈도.. 빈 설정으로 오버라이드 했다.
@TestConfiguration
class LogDbConfig {
}
공통으로 사용하려고 설정으로 빼두었는데 3번 설정과 겹쳐서 extend한다.
그리고 추가적으로 3개의 transactionManager도 h2용으로 연결했다.
여기서 계속 헤맸던 게 소스 상에서는 3개의 transactionManager만 사용하는데 자꾸 default transactionManager가 없다고 나오는 게 아닌가.. 이게 왜 필요한가 봤더니.. @Sql 때문인 것 같았다..
@TestConfiguration
public class IntegrationTestConfigurations extends TestDataSourceConfig {
//NOTE: 통합테스트의 목적은 서비스의 비즈니스 로직 + 디비 로직 검증이므로 아래와 같은 외부 api 연동은 Mockito를 이용하도록 한다.
//외부 api 쏘는 서비스
@MockBean
TanServerConfigService tanServerConfigService;
...
//TODO: 아래 서비스들은 서비스 내부에 비즈니스 로직 + 외부 api 연동이 섞여 있으므로 통합테스트를 위해서는 external은 분리하는 작업이 필요하다.
@MockBean
GoodsService goodsService;
...
@Bean({"aTransactionManager", "bTransactionManager", "cTransactionManager", "transactionManager"})
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
@Import(IntegrationTestConfigurations.class)
@SpringBootTest
class EventLoginRewardIntegrationTest {
//필요한 서비스, 레파지토리 주입
@Autowired
private EventLoginRewardService eventLoginRewardService;
...
@AfterEach
void tearDown() {
//관련 디비 내용물 삭제
//테스트용 @Transactional은 사용하지 않았음(의도적)
staticMessageRepository.deleteAll();
...
}
@Test
@DisplayName("전체 리스트 조최; 데이터 들어있다는 전제")
@Sql({"classpath:dynamic-login-reward.sql", "classpath:service-login-reward.sql",
"classpath:message-login-reward.sql",})
void getRewardEvents__success() {
//when
Page<LoginRewardResponse> responsePage = eventLoginRewardService.getRewardEvents(PageRequest.of(0, 10, Sort.by("seq").descending()));
//then
assertEquals(4, responsePage.getContent().size());
assertEquals("일정 기간 동안 접속 시 보상 획득 (한번)", responsePage.getContent().get(3).getDescription());
}
...
테스트용 데이터를 삽입하려고 @Sql을 달았는데, 이것 때문에 별도 트랜젝션이 필요한 듯하다. 그래서 기본 transactionManager를 달아주었다..
물론 이 설정이 다 맞고 옳은 방법인지 확신은 없는데, 어쨌건 우선 잘 되니까 지켜보려고 한다.ㅠㅠ
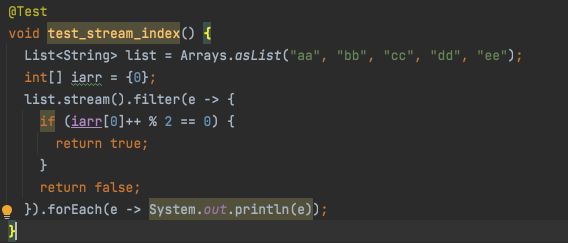
stream을 사용하여 리스트의 홀수번째(index 기준 0, 2, 4)에 있는 원소를 콘솔에 찍어본다고 가정하자.
아래와 같이 짜야지라고 쉽게 생각할 수 있다.
variable used in lambda expression should be final or effectively final
근데 위와 같은 에러가 난다.
그 이유는 아래와 같다. 자세한 내용을 알려면 람다 캡쳐링과 그 원리에 대해 이해해야한다.
The restriction to effectively final variables prohibits access to dynamically-changing local variables, whose capture would likely introduce concurrency problems.
람다식 내부에서는 람다식 안에서 정의된 변수가 아닌 외부 변수에 접근할 수 있는데 이를 람다 캡쳐링이라고 한다.
스트림은 여러 thread의 병렬처리를 염두하고 만들어졌다. 즉 별도의 스레드에서 실행할 수 있다. 그렇다면 어떻게 기존 스레드의 값을 참조하여 쓸 수 있을까? 기존 스레드의 작업이 종료되었을 수도 있는데 말이다.
람다 캡쳐링이 일어날 때 데이터의 참조값(call by reference)이 아닌 데이터 값 그 자체(call by value)를 복사하여 자신의 스택에 두고 작업을 한다. 그렇기 때문에 값이 변경될 여지가 있는 변수는 사용할 수 없고 final에 준하는(effectively final) 변수만 람다 안에서 사용할 수 있다.
반면 heap에 저장된 값은 thread끼리 공유하고 있기 때문에 언제든지 구할 수 있으므로 변경하더라도 에러가 나지 않는다.
Java의 스트림 API에서 외부 변수를 사용할 때 해당 변수가 effectively final해야 하는 이유는 다음과 같습니다:
1. 스레드 안전성
스트림의 연산은 종종 병렬로 실행되며, 외부 변수가 여러 스레드에서 동시에 접근될 수 있습니다. 이를 방지하기 위해 외부 변수가 변경되지 않도록 보장해야 합니다.
2. 불변성
외부 변수가 effectively final이면, 그 값이 변경되지 않는 것을 보장합니다. 이로 인해, 람다 표현식이나 메서드 참조가 이 변수를 안전하게 사용할 수 있습니다. 불변성을 유지함으로써 예측 가능한 동작을 보장합니다.
3. 람다 캡처
Java의 람다 표현식은 외부 변수를 캡처할 수 있지만, 캡처된 변수는 내부적으로 복사되어 사용됩니다. 만약 이 변수가 변경 가능하다면, 예상치 못한 결과를 초래할 수 있습니다. 이를 방지하기 위해 effectively final 조건이 필요합니다.`
위 함수의 에러는 여러 방법으로 수정할 수 있다.
1. AtomicInteger를 사용하여 수정
2. list/array를 이용해 수정
2번 방식으로 수정하다 보니 신기했던 것은 단순 값이 변경된다는 것에 초점을 둘게 아니라 final이면 된다는 점에 초점을 뒀어야 한다는 것이다. 일반적으로 final이라고 하면 불변, 즉 string이나 int인 경우 값이 바뀌면 안 된다고 인식하기 때문에 '값의 변경'에 나도 모르게 초점이 갔는데, collection 같은 경우에는 final이어도 값이 변동(추가 혹은 수정)될 수 있다!
전체 변경; 재할당일부 변경
즉 참조값이 바뀌면 안 되고 같은 참조값 안에서의 변경은 된다(final but mutable)
final --> You cannot change the reference to the collection (Object). You can modify the collection / Object the reference points to. You can still add elements to the collection
immutable --> You cannot modify the contents of the Collection / Object the reference points to. You cannot add elements to the collection.