1. transaction commit 순서
spring jpa에서 기본으로 제공하는 repository.delete() / repository.save()를 사용할 때에
AbstractFlushingEventListener (Hibernate JavaDocs)
protected void performExecutions(EventSource session) Execute all SQL (and second-level cache updates) in a special order so that foreign-key constraints cannot be violated: Inserts, in the order they were performed Updates Deletion
docs.jboss.org
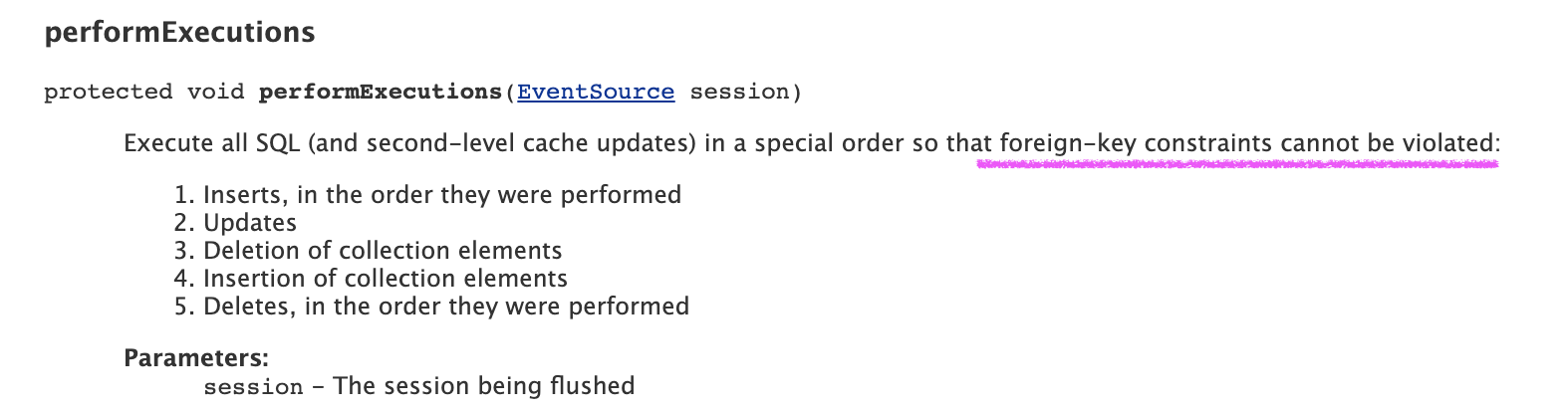
한 트랜젝션 안에서 delete -> insert 순으로 작업이 있어도 fk제약조건 때문에 insert -> delete 순으로 진행된다.
외래 키 제약 조건이란?
외래 키 값은 다른 테이블의 기본키 값들 중에 하나여야 함.
즉, 없는 데이터를 참조해서 외래 키로 쓰면 안 됨.
이 문제는 특히 엔티티 간의 연관 관계가 설정되어 있고, 외래 키(Foreign Key) 제약 조건이 걸려 있는 경우 발생할 수 있습니다.
단이는 spring jpa에서 기본으로 제공하는 repository.delete() / repository.save()를 사용할 때에 그렇고 @Query 어노테이션을 이용하여 커스텀 쿼리를 줄 경우는 또 안 그렇다..
해결법
1. 수동 플러시 사용
Hibernate가 SQL을 자동으로 처리하지 않도록 수동으로 플러시(flush())와 클리어(clear())를 사용하여 정확한 순서로 쿼리를 강제할 수 있습니다.
@Transactional
public void deleteAndInsert() {
// 기존 엔티티 삭제
myEntityRepository.deleteAll();
// 엔티티 매니저 수동 플러시
entityManager.flush();
entityManager.clear();
// 새로운 엔티티 삽입
List<MyEntity> newEntities = new ArrayList<>();
// newEntities에 데이터 추가
myEntityRepository.saveAll(newEntities);
}- deleteAll() 후에 entityManager.flush()를 호출하면, DELETE SQL이 즉시 실행되어 데이터베이스에서 삭제됩니다.
- entityManager.clear()는 Persistence Context를 비워 엔티티 상태를 초기화합니다.
2. Cascade 설정 확인
엔티티 간 연관 관계에서 cascade 설정이 문제를 일으킬 수 있습니다. 예를 들어, CascadeType.ALL 또는 CascadeType.REMOVE가 설정되어 있는 경우 Hibernate가 엔티티의 라이프사이클을 관리하기 위해 예상치 못한 순서로 INSERT 또는 DELETE를 수행할 수 있습니다.
연관된 엔티티의 cascade 옵션을 다음과 같이 필요한 옵션만 사용하여 설정합니다.
@OneToMany(mappedBy = "parent", cascade = {CascadeType.PERSIST, CascadeType.MERGE})
private List<Child> children;3. JPQL 또는 Native Query 사용
JPA가 아닌 순수 SQL 쿼리를 사용하여 필요한 순서로 작업을 수행할 수도 있습니다.
@Modifying
@Query("DELETE FROM MyEntity e WHERE e.parent.id = :parentId")
void deleteByParentId(@Param("parentId") Long parentId);
@Modifying
@Query(value = "INSERT INTO my_entity (id, name, parent_id) VALUES (:id, :name, :parentId)", nativeQuery = true)
void insertEntity(@Param("id") Long id, @Param("name") String name, @Param("parentId") Long parentId);이 방법을 사용하면, 외래 키 제약 조건을 위반하지 않도록 원하는 순서로 DELETE와 INSERT를 수행할 수 있습니다.
4. 트랜잭션 분리
DELETE와 INSERT를 별도의 트랜잭션으로 처리하는 방법도 있습니다. 이렇게 하면 한 트랜잭션에서 삭제된 후, 다른 트랜잭션에서 삽입이 되므로 외래 키 문제를 피할 수 있습니다.
2. Transactional AOP
같은 클래스 내에서 두 메서드에 각각 @Transactional이 있고, 한 메서드가 다른 메서드를 호출할 때(transactional 중첩), REQUIRES_NEW를 propagation을 사용해서 호출하더라도 해당 트랜젝션은 첫 번째 트랜젝션에 다 물린다.
다른 트랜젝션으로 처리해야 한다면 다른 클래스에 @Transactional이 있는 메서드를 호출해야 한다.
이유는 spring AOP는 프락시는 객체 단위로 감싸 지기 때문에 같은 클래스 안의 다른 함수도 결국 같은 프락시에 있어서 그렇다.
참고) 지금 로직이 transaction안에 들어있는지 확인
transactionstatus를 조회해서 같은 id 인지, active 인지 확인 가능하다.
You can check if transaction is active using
TransactionSynchronizationManager.isActualTransactionActive().
But you should call it before a service method executing.
Also you can get status of current transaction using
TransactionStatus status = TransactionAspectSupport.currentTransactionStatus();
Besides, maybe a good point for you is to enable logging of transactions.
log4j.logger.org.hibernate.transaction=DEBUG
log4j.logger.org.springframework.transaction=DEBUG
2024.05.23 - [개발/spring] - [jpa] transaction propagation
[jpa] transaction propagation
2024.05.23 - [개발/spring] - [transaction] isolation level [jpa] transaction isolation level2024.05.22 - [개발/sql] - DB isolation level DB isolation levelisolation level 이란 무엇인가?디비 동시성을 관리하고 데이터 정합성을 유
bangpurin.tistory.com
3. save vs saveAll
100개의 entity를 저장하고자 할 때, save를 이용할 때와 saveAll을 이용할 때 어떤 것이 성능이 더 좋을까? 답은 saveAll이다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
/*
* (non-Javadoc)
* @see org.springframework.data.jpa.repository.JpaRepository#save(java.lang.Iterable)
*/
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<S>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}내부 로직을 살펴보면 saveAll도 결국 for loop을 돌면서 save를 호출하는 것이니 같은 로직이라고 생각할 수 있다.
하지만 transaction중심으로 보자면 달라진다. saveAll과 save 모두 @Transactional 어노테이션이 있는 것을 볼 수 있는데, 이 경우 밖에 있는 트랜젝션으로 유지된다(추가적인 트랜젝션이 생성되지 않는다). 위에서 설명한 spring AOP 원리에 의거한다.
REQUIRED is the default propagation. Spring checks if there is an active transaction, and if nothing exists, it creates a new one. Otherwise, the business logic appends to the currently active transaction
즉 save 100번은 100번의 트랜젝션이 생겼다 없어졌다 하는 것이고, saveAll은 하나의 트랜젝션에서 100번 저장하는 것이다. 여기서 속도 차이가 나오게 된다.
그렇다면, 서비스단에서 @Transactional을 걸고 save 100번과, @Transactional 없이 saveAll 100번 한 성능은 비슷할까?
이론상으로는 비슷해야 하는데 테스트해봐야겠다.
++ 여기서 mysql 디비를 사용하면 사실 saveAll이 진짜 배치 인서트가 아닐 수 있다. 특히 id를 자동생성하면 더더욱!
GenerationType.IDENTITY Forces Synchronous Insert
id를 생성해서 다시 어플리케이션으로 내려주고 스프링은 그걸 받아서 세팅한 후 save all을 하는 것이라.. 디비 호출이 딱히 줄지 않아 성능상 이점이 없다. 이를 해결하기 위해서는 Sequence 방식으로 id 생성 전략을 바꿔야한다..
관련 글:
2022.03.30 - [개발/spring] - [transaction] rollback works only for unchecked exception
[transaction] rollback works only for unchecked exception
2022.03.16 - [개발/spring] - [spring] ChainedTransactionManager deprecated from boot 2.5 [spring] ChainedTransactionManager deprecated from boot 2.5 한 트랜젝션에서 서로 다른 DB에 update/insert 작업..
bangpurin.tistory.com
2022.05.27 - [개발/spring] - [spring-jpa] 부모-자식 트랜젝션 관계(propagation)
[spring-jpa] 부모-자식 트랜젝션 관계(propagation)
@Transactional 하위에 또 다른 @Transactional을 준다면? REQUIRED is the default propagation. Spring checks if there is an active transaction, and if nothing exists, it creates a new one. Otherwise,..
bangpurin.tistory.com
2022.01.27 - [개발/spring] - [jpa] 영속성 컨텍스트 in spring
[jpa] 영속성 컨텍스트 in spring
영속성 컨텍스트? 엔티티를 영구 저장하는 환경으로 애플리케이션과 DB 사이에서 객체를 보관하는 가상의 데이터베이스 같은 역할을 한다. 엔티티 매니저를 통해 엔티티를 저장하거나 조회하
bangpurin.tistory.com
2022.01.27 - [개발/spring] - [jpa] OSIV란; spring.jpa.open-in-view
[jpa] OSIV란; spring.jpa.open-in-view
OSIV에 대한 이해를 하려면 영속성 컨텍스트가 뭔지 알아야한다. 이전 글을 참고하자. 2022.01.27 - [개발/spring] - [jpa] 영속성 컨텍스트 in spring [jpa] 영속성 컨텍스트 in spring 영속성 컨텍스트? 엔티티.
bangpurin.tistory.com
https://eocoding.tistory.com/94
@Transactional 분리가 안되는 이유 / 실험을 통해 트랜잭션 전파 유형과 Spring AOP 이해
이번 포스팅은 올해 5월에 올렸던 포스팅에 대한 후속 포스팅이다. https://eocoding.tistory.com/74 @Transactional에서 JPA로 delete한 뒤 insert가 안될 때, duplicate entry 에러가 날 때 해결하기 일단 원인..
eocoding.tistory.com
https://2dongdong.tistory.com/29
Spring Data JPA Save(insert) 속도 최적화
대량의 데이터를 삽입하는 상황이 생겼습니다. 초창기에는 JPA Save함수를 반복문을 통해 호출해서 저장하게 구현을 했는데요. 처음에는 괜찮았으나, 삽입 할 데이터가 점점 많아지면서 삽입 시
2dongdong.tistory.com
'개발 > spring' 카테고리의 다른 글
| [spring-jpa] mysql, use json(db) function in @Query (0) | 2022.10.25 |
|---|---|
| [transaction] why do we need read-only transaction? (0) | 2022.09.21 |
| [spring-jpa] stream vs list (0) | 2022.08.01 |
| [spring-jpa] composite key obtains null after save (0) | 2022.07.25 |
| [webjars] dependency for static libs (0) | 2022.07.12 |