List<Student> studentList = new ArrayList<>();
studentList.add(a);
studentList.add(b);
studentList.add(c);
for (int i = 0; i < studentList.size(); i++) {
System.out.println("Roll number: " + studentList.get(i).getRollNumber());
}
advanced for loop
for (Student st : studentList) {
System.out.println("Roll number: " + st.getRollNumber());
}
while, hasNext
Iterator<Object> it = list.iterator();
while (it.hasNext()) {
Object o = it.next();
// do stuff
}
old for
advanced for
since
jdk1
jdk5
index increasing
custom가능(2씩 증가 등); 역순 가능
무조건 1씩 증가만 가능; 역순 불가
index approach
index 접근 가능
index 접근 불가
usage
어떠한 셀 수 있는 container object에 사용 가능
iterable interface를 구현한 구현체만 사용가능
위 세 방법 모두 성능상에 큰 차이는 없고, 굳이 따지자면 old for loop이 index의 객체를 탐사해야 하니(Object.get(i)) 조금 더 느릴 수 있다는 글이 있다. advance for loop으로 짜면 컴파일러가 while hasNext 문으로 변환할 거라 두 방법은 사실 거의 같은 거라고 볼 수 있다.
단순 1씩 증가한 loop이라면 advanced for loop을 사용하는 게 보기에도 더 좋을 듯하다.
구관이 명관인가. (의외로) old for loop이 제일 성능이 좋았다.. 다른 것보다 거의 두배 정도?(정확히 두배라고 말할 순 없지만..) 그다음이 while문이라니.. 나머지는 비슷비슷한 것 같은데 어쨌건 꼴찌는 Collection.foreach였다..ㅋㅋㅋ 어느 글을 믿어야 하나,, 신기방기 하다.
단순한 자바 성능 테스트를 하기 위한 툴로 benchmark가 있다. 간단하게 세팅하고 실행해본다.
환경: java 11 / gradle 7.4
1. intellij에서 gradle로 프로젝트 생성
2. 파일 구조 아래와 같이 만들기
main/test 폴더 삭제
3. build.gradle에 plugin 추가
plugins {
id 'java'
id "me.champeau.jmh" version "0.6.6"
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.7.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.7.0'
}
test {
useJUnitPlatform()
}
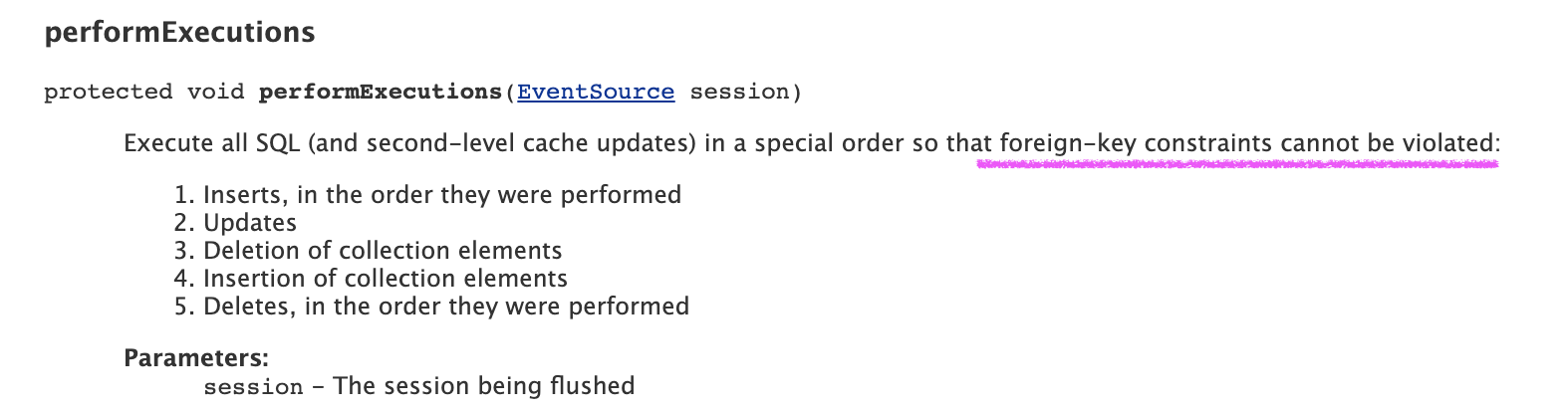
한 트랜젝션 안에서 delete -> insert 순으로 작업이 있어도 fk제약조건 때문에 insert -> delete 순으로 진행된다.
외래 키 제약 조건이란? 외래 키 값은 다른 테이블의 기본키 값들 중에 하나여야 함. 즉, 없는 데이터를 참조해서 외래 키로 쓰면 안 됨.
이 문제는 특히 엔티티 간의 연관 관계가 설정되어 있고, 외래 키(Foreign Key) 제약 조건이 걸려 있는 경우 발생할 수 있습니다.
단이는 spring jpa에서 기본으로 제공하는 repository.delete() / repository.save()를 사용할 때에 그렇고 @Query 어노테이션을 이용하여 커스텀 쿼리를 줄 경우는 또 안 그렇다..
해결법
1.수동 플러시 사용
Hibernate가 SQL을 자동으로 처리하지 않도록 수동으로 플러시(flush())와 클리어(clear())를 사용하여 정확한 순서로 쿼리를 강제할 수 있습니다.
@Transactional
public void deleteAndInsert() {
// 기존 엔티티 삭제
myEntityRepository.deleteAll();
// 엔티티 매니저 수동 플러시
entityManager.flush();
entityManager.clear();
// 새로운 엔티티 삽입
List<MyEntity> newEntities = new ArrayList<>();
// newEntities에 데이터 추가
myEntityRepository.saveAll(newEntities);
}
deleteAll() 후에 entityManager.flush()를 호출하면, DELETE SQL이 즉시 실행되어 데이터베이스에서 삭제됩니다.
entityManager.clear()는 Persistence Context를 비워 엔티티 상태를 초기화합니다.
2. Cascade 설정 확인
엔티티 간 연관 관계에서 cascade 설정이 문제를 일으킬 수 있습니다. 예를 들어, CascadeType.ALL 또는 CascadeType.REMOVE가 설정되어 있는 경우 Hibernate가 엔티티의 라이프사이클을 관리하기 위해 예상치 못한 순서로 INSERT 또는 DELETE를 수행할 수 있습니다.
@Modifying
@Query("DELETE FROM MyEntity e WHERE e.parent.id = :parentId")
void deleteByParentId(@Param("parentId") Long parentId);
@Modifying
@Query(value = "INSERT INTO my_entity (id, name, parent_id) VALUES (:id, :name, :parentId)", nativeQuery = true)
void insertEntity(@Param("id") Long id, @Param("name") String name, @Param("parentId") Long parentId);
이 방법을 사용하면, 외래 키 제약 조건을 위반하지 않도록 원하는 순서로 DELETE와 INSERT를 수행할 수 있습니다.
4. 트랜잭션 분리
DELETE와 INSERT를 별도의 트랜잭션으로 처리하는 방법도 있습니다. 이렇게 하면 한 트랜잭션에서 삭제된 후, 다른 트랜잭션에서 삽입이 되므로 외래 키 문제를 피할 수 있습니다.
2. Transactional AOP
같은 클래스 내에서 두 메서드에 각각 @Transactional이 있고, 한 메서드가 다른 메서드를 호출할 때(transactional 중첩), REQUIRES_NEW를 propagation을 사용해서 호출하더라도 해당 트랜젝션은 첫 번째 트랜젝션에 다 물린다.
다른 트랜젝션으로 처리해야 한다면 다른 클래스에 @Transactional이 있는 메서드를 호출해야 한다.
이유는 spring AOP는 프락시는 객체 단위로 감싸 지기 때문에 같은 클래스 안의 다른 함수도 결국 같은 프락시에 있어서 그렇다.
참고) 지금 로직이 transaction안에 들어있는지 확인
transactionstatus를 조회해서 같은 id 인지, active 인지 확인 가능하다.
You can check if transaction is active using TransactionSynchronizationManager.isActualTransactionActive(). But you should call it before a service method executing.
Also you can get status of current transaction using TransactionStatus status = TransactionAspectSupport.currentTransactionStatus();
Besides, maybe a good point for you is to enable logging of transactions. log4j.logger.org.hibernate.transaction=DEBUG log4j.logger.org.springframework.transaction=DEBUG
100개의 entity를 저장하고자 할 때, save를 이용할 때와 saveAll을 이용할 때 어떤 것이 성능이 더 좋을까? 답은 saveAll이다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
/*
* (non-Javadoc)
* @see org.springframework.data.jpa.repository.JpaRepository#save(java.lang.Iterable)
*/
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<S>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
내부 로직을 살펴보면 saveAll도 결국 for loop을 돌면서 save를 호출하는 것이니 같은 로직이라고 생각할 수 있다.
하지만 transaction중심으로 보자면 달라진다. saveAll과 save 모두 @Transactional 어노테이션이 있는 것을 볼 수 있는데, 이 경우 밖에 있는 트랜젝션으로 유지된다(추가적인 트랜젝션이 생성되지 않는다). 위에서 설명한 spring AOP 원리에 의거한다.
REQUIRED is the default propagation. Spring checks if there is an active transaction, and if nothing exists, it creates a new one. Otherwise, the business logic appends to the currently active transaction
즉 save 100번은 100번의 트랜젝션이 생겼다 없어졌다 하는 것이고, saveAll은 하나의 트랜젝션에서 100번 저장하는 것이다. 여기서 속도 차이가 나오게 된다.
그렇다면, 서비스단에서 @Transactional을 걸고 save 100번과, @Transactional 없이 saveAll 100번 한 성능은 비슷할까?
이론상으로는 비슷해야 하는데 테스트해봐야겠다.
++ 여기서 mysql 디비를 사용하면 사실 saveAll이 진짜 배치 인서트가 아닐 수 있다. 특히 id를 자동생성하면 더더욱!
GenerationType.IDENTITY Forces Synchronous Insert
id를 생성해서 다시 어플리케이션으로 내려주고 스프링은 그걸 받아서 세팅한 후 save all을 하는 것이라.. 디비 호출이 딱히 줄지 않아 성능상 이점이 없다. 이를 해결하기 위해서는 Sequence 방식으로 id 생성 전략을 바꿔야한다..
Java의 Stream은 AutoCloseable을 구현하고 있습니다. 따라서 try-with-resources 문을 사용할 수 있다.
구체적으로 말하면, Java 8에서 도입된 Stream 인터페이스는 BaseStream 인터페이스를 상속하고 있는데, 이 BaseStream이 AutoCloseable 인터페이스를 구현하고 있다. 그래서 Stream을 try-with-resources 문에서 사용하면 자동으로 close() 메서드가 호출되어 리소스를 해제한다.
try (Stream<User> userStream = userRepository.streamAll()) { ///stream close
userStream.forEach(user -> {
// 사용자 처리
});
}
///
@Query("SELECT u FROM User u")
Stream<User> streamAll();
Stream과 트랜잭션의 관계
Stream은 지연 로딩을 기반으로 동작: 커서방식
JPA에서 **Stream<T>**는 지연 로딩(lazy loading) 방식으로 데이터를 가져온다. 즉, 데이터를 한 번에 모두 로드하는 대신, 필요할 때마다 데이터를 순차적으로 가져오는 방식이다.
이 과정에서 데이터베이스 연결이 열려 있어야 스트리밍을 통해 데이터베이스에서 데이터를 지속적으로 읽어올 수 있다.
@Transactional은 트랜잭션을 유지:
트랜잭션이 활성화되면, JPA는 **데이터베이스 연결(session)**을 트랜잭션이 끝날 때까지 유지한다.
**Stream**은 트랜잭션이 끝날 때까지 데이터를 계속해서 가져와야 하므로, 트랜잭션이 열려 있는 상태에서 스트리밍 작업을 수행해야 한다.
만약 트랜잭션이 열려 있지 않으면, 데이터베이스 연결이 닫히고, LazyInitializationException 같은 오류가 발생할 수 있다. 이는 트랜잭션 외부에서 지연 로딩을 시도했을 때 발생하는 오류이다.
트랜잭션 타임아웃: 트랜잭션이 설정된 시간 내에 완료되지 않으면 타임아웃이 발생해 트랜잭션이 롤백됩니다.
데이터베이스 커넥션 유지 문제: 커서 방식으로 데이터베이스 커넥션을 오랜 시간 열어둬야 하기 때문에, 데이터베이스 연결 자원이 부족해질 수 있습니다.
락 경합: 트랜잭션이 너무 오래 유지되면, 다른 트랜잭션들이 동일한 데이터를 수정하려고 할 때 **락 경합(lock contention)**이 발생할 수 있습니다.
@Transactional 없이 사용할 경우:
트랜잭션이 열리지 않으면, 데이터베이스 세션이 닫히기 때문에 스트리밍이 중간에 끊기고 예외가 발생할 가능성이 높다.
따라서 Stream을 사용해 데이터를 처리할 때는 트랜잭션이 유지되어야만 안전하게 데이터베이스와의 연결을 유지하면서 지연 로딩을 통한 스트리밍이 가능다.
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional(readonly=true, timeout = 300) // 트랜잭션 타임아웃을 300초로 설정
public void processUsers() {
try (Stream<User> userStream = userRepository.findAllUsersByStream()) {
userStream.forEach(user -> {
// 유저 처리 로직
System.out.println(user.getName());
});
}
}
}
powermock이란? junit4로 테스트코드를 작성 시 static method를 mock할 수 있게 하는 방법
Mockito Mock Static Method using PowerMock PowerMock provides different modules to extend Mockito framework and run JUnit and TestNG test cases.
Note that PowerMock doesn’t support JUnit 5 yet, so we will create JUnit 4 test cases. We will also learn how to integrate TestNG with Mockito and PowerMock.
public static DataHandler getDataHandler() throws IllegalStateException {
...
}
We need to do the following to integrate PowerMock with Mockito and JUnit 4.
1. Annotate test class with @RunWith(PowerMockRunner.class) annotation. 2. Annotate test class with @PrepareForTest and provide classed to be mocked using PowerMock. 3. Use PowerMockito.mockStatic() for mocking class with static methods. 4. Use PowerMockito.verifyStatic() for verifying mocked methods using Mockito.
powermockito가 기존의 junit4와 혼용이 가능한지 궁금했는데, junit4코드를 아래와 같이 수정하니 잘 되는 것을 확인할 수 있었다.
@RunWith(PowerMockRunner.class) //1.
@PrepareForTest(DataHandlerFactory.class) //2.
//@RunWith(MockitoJUnitRunner.class)
public class HuntBOTest {
//기존 junit4 스타일로 선언
@InjectMocks
private HuntBO huntBO;
@Mock
private HuntDAO huntDAO;
public String ALPHA_FILE = "data-alpha.xml";
public void includeForAlpha(){
//mockStatic 이후에 하면 null이 나오기 때문에 mock하기 전에 stub을 만들어야 한다.
DataHandler sample = DataHandlerFactory.create(ALPHA_FILE);
PowerMockito.mockStatic(DataHandlerFactory.class); //3.
when(DataHandlerFactory.getDataHandler()).thenReturn(sample);
}
@Test
public void getTop1000__subList__alpha(){
includeForAlpha();
when(huntDAO.selectHuntTop1000AfterAug()).thenReturn(getList());
List<HuntRank> hrList = huntBO.getTop1000();
List<HuntRank> hrListSub = hrList.subList(0, 1);
assertThat(hrListSub.get(0).getRank(), is(1));
}
}
webjar?
클라이언트에서 사용하는 웹라이브러리(jquery, bootstrap, React.js, Vue.js, Angular 등) 를 JAR 파일 안에 패키징한 것이다.
jquery, bootstrap 등과 같은 static library를 사용하는 경우 보통 개별적으로 버전을 알아봐서 resources 폴더 안에 다운로드하여 넣거나 cdn 주소를 명시하거나 하는 방법으로 사용한다. 이 경우 필요한 라이브러리를 일일이 찾아서 추가해줘야 하고 버전 관리를 따로 해줘야 하는 번거로움이 있는데, webjar을 이용하면 버전관리가 좀 더 수월하고 springboot의 여러 지원도 받을 수 있다.
maven central repo에는 org.webjar.*로 javascript library가 등록되어 있다. 하지만 실제로 찾아보니 maven repo에서 찾는 것 보다 webjars 공식 사이트에서 하는 게 편하다. www.webjars.org/
특히 webjars-locator-core는 html include 시 아래와 같이 버전을 명시하지 않아도 자동으로 가져오기 때문에 사용을 추천한다.
///before; version 정보 있음
<script src="/webjars/jquery/3.5.1/dist/jquery.min.js"></script>
///after; version 정보 없음
<script src="/webjars/jquery/jquery.slim.js"></script>
<script src="/webjars/sockjs-client/sockjs.min.js"></script>
<script src="/webjars/stomp-websocket/stomp.min.js"></script>
이를 사용하지 않으면 만약 버전을 하나 올릴 경우 모든 include 안의 버전을 수정해줘야 하는 번거로움이 있는데, webjars-locator-core를 사용하면 pom.xml의 명시된 버전으로 자동 사용한다.
Liquibase is a database schema change management solution that enables you to revise and release database changes faster and safer from development to production.
DB변경 정보를 관리하는 툴이다. 다양한 DB를 지원하며 cli로도 적용 가능하며, springboot project 와도 연동이 가능하다.
주의할 사항은 liquibase를 이용하여 DB정보를 관리하기로 했다면 수동 혹은 기타 방법으로 DB 작업을 해서는 안된다. 히스토리 관리가 안될 테니 어디서 꼬일지 모른다.
위 소스에서 T1은 string, number, 인자 없는 함수, 인자 있고 return 있는 함수 중 함수의 형태만 타입으로 가질 수 있다.
test6은 return 이 없는 함수고 test7은 string이라 에러가 난다.
NonNullable<Type>
: Type에 들어오는 타입 중 null, undefined를 제한 타입만 가능하다
type T0 = NonNullable<string | number | undefined>;
// T0는 string, number만 가능
type T1 = NonNullable<string[] | null | undefined>;
// T1은 string[]만 가능
Parameters<Type>
: 함수의 파라미터를 타입으로 리턴한다.
declare function f1(arg: { a: number; b: string }): void;
type T0 = Parameters<() => string>;
// T0 = []
type T1 = Parameters<(s: string) => void>;
// T1 = [s:string]
type T2 = Parameters<<T>(arg: T) => T>;
// T2 = [arg: unknown]
type T3 = Parameters<typeof f1>;
// T3 = [arg: { a: number; b: string }]
type T4 = Parameters<any>;
// T4 = unknown[]
// never는 any를 제외한 모든 타입의 원시타입이기때문에
// 함수타입 T에 never로 주어도 에러가 발생하지 않음
type T5 = Parameters<never>;
// T5 = never
type T6 = Parameters<string>;
// 에러
type T7 = Parameters<Function>;
// 에러
위 소스에서 T6, T7은 '(...args: any) => any'의 형식이 아니라서 에러가 난다. 즉 Parameters가 인자로 받을 수 있는 것은 모든 파라미터를 인자로 받고 결괏값으로 모든 값을 리턴하는, 사실상 모든 함수가 된다.
ConstructorParameters<Type>
: 생성자를 갖는 함수 타입의 생성자 파라미터를 리턴한다. 함수가 아니라면 never를 리턴한다. 위 Parameters와 비슷하지만 생성자 파라미터로 한정한다.
type T0 = ConstructorParameters<ErrorConstructor>;
// T0 = [message?: string | undefined]
type T1 = ConstructorParameters<FunctionConstructor>;
// T1 = string[]
type T2 = ConstructorParameters<RegExpConstructor>;
// T2 = [pattern: string | RegExp, flags?: string | undefined]
type T3 = ConstructorParameters<any>;
// T3 = unknown[]
//에러발생
type T4 = ConstructorParameters<Function>;
// T4 = never
============
class Person {
private _firstname: string
private _lastname: string
constructor(firstname: string, lastname: string) {
this._firstname = firstname
this._lastname = lastname
}
}
type typeIs = ConstructorParameters<typeof Person>;
let personConstructionArgs: typeIs = ['first', 'last']
ReturnType<Type>
: 함수의 리턴타입을 가져온다.
declare function f1(): { a: number; b: string };
type T0 = ReturnType<() => string>;
// T0 = string
type T1 = ReturnType<(s: string) => void>;
// T1 = void
type T2 = ReturnType<<T>() => T>;
// T2 = unknown
type T3 = ReturnType<<T extends U, U extends number[]>() => T>;
// T3 = number[]
type T4 = ReturnType<typeof f1>;
// T4 = { a: number; b: string }
type T5 = ReturnType<any>;
// T5 = any
type T6 = ReturnType<never>;
// T6 = never;
//에러
type T7 = ReturnType<string>;
// T7 = any
type T8 = ReturnType<Function>;
// T8 = any
InstanceType<Type>
: 생성자로 초기화된 인스턴스 타입을 리턴한다.
class C {
x = 0;
y = 0;
}
type T0 = InstanceType<typeof C>;
// T0 = C
const test :T0 = {x: 1, y: 3, z: 2} // 에러
type T1 = InstanceType<any>;
// T1 = any
type T2 = InstanceType<never>;
// T2 = never
// 에러
type T3 = InstanceType<string>;
// T3 = any
type T4 = InstanceType<Function>;
// T4 = any
ThisParameterType<Type>
: 함수 타입의 this 파라미터의 type을 가져온다. this를 가지지 않는 함수 타입이면 unknown을 반환한다.
function toHex(this: Number) {
return this.toString(16);
}
type T = ThisParameterType<typeof toHex>;
// T = Number
function numberToString(n: ThisParameterType<typeof toHex>) {
return toHex.apply(n);
}
OmitThisParameter<Type>
: 타입의 this 파라미터를 무시한다. 타입에 this가 없으면 그냥 Type이다. 있으면 this가 없는 Type 이 만들어진다.
function toHex(this: Number) {
return this.toString(16);
}
console.log(toHex.call(2)); //2
type T = OmitThisParameter<typeof toHex>;
// T = () => string
const fiveToHex: T = toHex.bind(16);
console.log(fiveToHex()); //10