내가 맡고 있는 프로젝트 중 지금은 보기 힘든 프래임워크를 사용하는 것이 있는데, 구조가 낯설기에 매번 어려움을 느낀다.
(20년은 된 소스인데 지금까지 잘 돌아가는거 보면 잘 짜져있음은 분명하다ㅋㅋ)
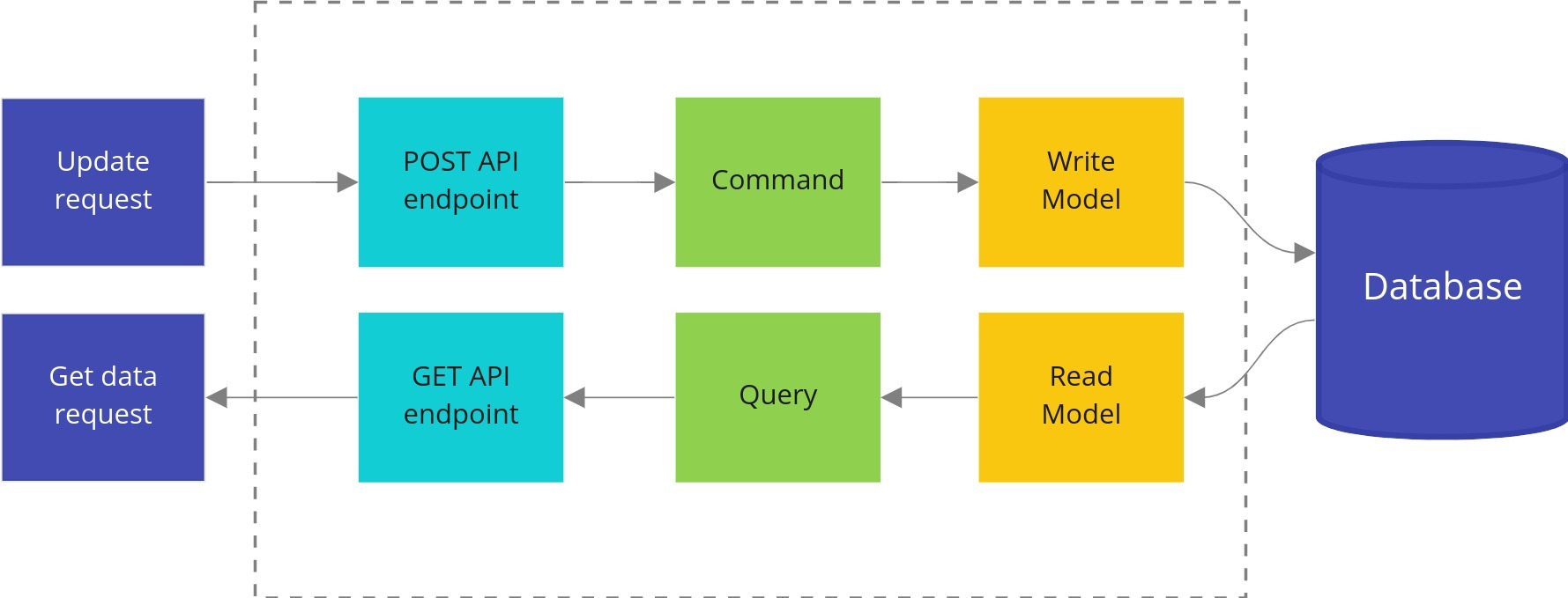
오늘은 해당 프로젝트를 오랜만에 보면서 MVC framework 중 webwork에 대해 기술한다.
- 환경: webwork-2.2.7 / xwork-1.1.1(or 1.2.3? 1.2.4? 관련 jar의 버전이 다 달라 혼동스럽다)
struts / webwork / xwork 이것들의 차이는 무엇인가..
팀장님이 처음에 나에게 설명해주실 때 이 소스를 두고 struts를 사용했다고 하셨는데, 직접적인 struts*.jar이 임포트 되어 있진 않다. webwork를 기반으로 하고 있으며 그냥 구조가 struts와 유사하여 그렇게 부른 것 같다..
그래서 더 혼동스러웠다.
요즘에는 잘 사용하지 않는 framework여서인지 정확한 정보는 현재로서 찾기는 힘드나 여러 글들을 종합한 바 아래와 같다.
- 우선 webwork와 xwork는 만든 회사가 같다(opensymphony; 지금 찾아보니 인수되었거나 망한 듯.. 홈피가 안나온다).
- webwork은 커맨드 패턴에 기반하여 설계되었고, xwork의 wrapper다. 그래서인지 webwork으로 통합되었다는 말도 많고 webwork와 xwork 를 같게 보는 글이 많다. 하지만 계속 헷갈리는 건 소스안의 파일에 두 이름이 혼용되어 사용되고 있기 때문이다.
And webwork is just a wrapper for xwork into servlet environment.
WebWork is designed around the principle of the command pattern. In fact, it is really a wrapper XWork - a generic command-pattern framework.
- struts는 webwork을 기반을 만들어진 프래임워크다. 초기의 struts framework 는 webwork framework 와 같다고 여겨진다.
관련파일
web.xml : 필터 매핑, 서블랫 매핑
xwork.xml : 각 화면별 인터셉터 정의, url에 맞는 액션 클래스 매핑, execute()함수 결과값에 따른 화면 정의
webwork.properties : 확장자 정의, method지정 변수 설정, 인코딩, i18n 등 프래임워크 안의 세팅 값

보통 디버그할 때 xwork.xml을 열어서 url 매핑을 확인하고 액션.java 나 연관된 화면(.jsp)을 열어서 분석한다.
보던 소스가 인터셉터 덩어리라(한 화면에 기본30개) 액션에 대한 로그를 확인하기가 어려운 문제가 있다. 근데 로그를 잘 보니 인터셉터가 여러번 불리는 것 같은데(정확히는 인터셉터 -> 액션 -> 인터셉터) 이해가 잘 안간다.
자세히 설명하자면...
모니터링 - before interceptor > 점검 interceptor > 유저 interceptor > action > 유저 - PreResultListener interceptor > 모니터링 - after interceptor > 모니터링 - before interceptor > 점검 interceptor > 유저 interceptor > 유저 - PreResultListener interceptor > 모니터링 - after interceptor
위처럼 인터셉터만 두번 돌았다.. 소스만 봤을 때에는 위 회색 부분은 안 돌았어야 하는데 말이다.
혹시 다른 요청이 또 들어오나 싶어 네트워크 창을 같이 봤는데, 딱히 다른 액션 요청은 없고, 액션 요청 후 리소스를 불러오는 부분 뿐이었다.
디버그 걸린상태에서 관찰한 결과 첫번째 루프(정상이라고 생각한)에서 액션이 바로 200 응답을 받고(qna.nhn; 사진의 보라색 동그라미시점) 두번째 루프(회색)가 시작할 때 보니 .css, .js 등 모든 리소스파일이 pending 이었다. 두번째 루프의 디버그를 풀어갈 때 쯤 점차적으로 불러져왔다.
지금 추측은 리소스 파일을 불러오려는 시점에 내부 콜?이 더 있지 않을까 싶은데, 딱히 잡히는건 없다.. ㅠㅠ
참고: 커맨드 패턴
https://huisam.tistory.com/entry/CommandPattern
Command Pattern - 커맨드 패턴
Command Pattern? - 커맨드 패턴(Command Pattern)은 Client가 보낸 요청을 객체로 캡슐화하여 이를 나중에 이용할 수 있도록 필요한 정보를 저장, 로깅, 취소할 수 있게 하는 패턴입니다. * 한마디로, 요청을
huisam.tistory.com
webwork
https://blog.naver.com/tyboss/70047272213
WebWork
간단한 소개 XWork라고 불리는 커맨드 패턴 프레임웤 API의 위에 있는 강력한 웹기반의 MVC 프레임...
blog.naver.com
webwork properties 항목
https://babtingdev.tistory.com/66
webwork.properties 전체 내용
### Webwork default properties ###(can be overridden by a webwork.properties file in the root of the classpath) ### ### Specifies the Configuration used to configure webwork ### one could extend com..
babtingdev.tistory.com
'architecture > knowledge' 카테고리의 다른 글
| [개발문화] 유지보수하기 좋은 코드를 구현하는 개발 문화 어떻게 만들 것인가? (0) | 2023.04.24 |
|---|---|
| [http] http 기본 지식 (0) | 2022.05.19 |
| 웹브라우저 요청 흐름 (0) | 2022.05.19 |