고려사항
ASIS 고려
- 각 서버에서 요청 시 수집 서버를 호출하는 방식 말고 쌓인 로그 파일을 수집하여 수집 서버에서 로그를 분석하는 방식을 우선적으로 고려
- 기존에 그라파나, 프로메테우스 설정이 되어 있으니 필요 시 이를 활용할 수 있는 방안을 고려
- 기존 PIS 알림 방식이 가능한지 고민(특정 에러가 1분 안에 5번 이상 호출 시 알람 발생 등)
요청의 흐름에 대한 모니터링이 쉽게 되었으면 좋겠다고 생각함
- trace id는 프론트에서 생성해서 헤더에 심어 백엔드로 전파하는게 제일 좋을 것 같음
- 백엔드는 헤더에 trace id가 있으면 이걸 다음 컴포넌트에게 전파, 없으면 생성하여 헤더에 심어서 전파
- 추가적인 의미있는 정보: global trace id, span id, user key...
- 이걸 모듈화(기존 log module을 활용하여)하면 좋겠다는 생각..
- was, ws 간 로그 포맷 정형화 필요
- springboot 로그에서도 심지만 nginx 등 웹서버, 디비 호출, 인프라(loadbalancer) 등 에서도 trace id, 유저 구분자 등 활용 필요
Observability
로그나 실시간으로 수집되고 있는 모니터링 지표와 같은 출력을 통해 시스템의 상태를 이해할 수 있는 능력
-
시스템/어플리케이션의 내부 상태를 이해 -> 원인/문제를 진단(디버깅) -> 성능을 최적화하는 능력
측정 데이터
- 메트릭 (Metrics)
- 설명: 성능 지표. 시간에 따른 수치 데이터를 측정하여 시스템의 성능을 모니터링하기 위한 데이터
- CPU 사용량, 메모리 소비, 요청 수 등의 지표를 포함
- 도구 예시: Prometheus, Grafana
- 설명: 성능 지표. 시간에 따른 수치 데이터를 측정하여 시스템의 성능을 모니터링하기 위한 데이터
- 로그 (Logs)
- 설명: 시간 기반 텍스트, 애플리케이션과 시스템의 이벤트에 대한 기록. 구조화된 로그 필요
- 도구 예시: Elasticsearch, Loki
- 트레이스 (Traces)
- 설명: 데이터가 흘러가는 전체적인 경로(큰그림)
- 많은 시스템을 거쳐가는 분산 시스템에서 요청의 흐름을 추적하여 성능 병목 현상을 식별할 수 있음
- Trace ID 기반으로 로그-트레이스 연결 가능
- 도구 예시: Jaeger, Zipkin, Tempo
- 설명: 데이터가 흘러가는 전체적인 경로(큰그림)

OpenTelemetry(OTel)

OpenTelemetry은 Traces, Metrics, Logs 같은 데이터를 instrumenting, generating, collecting, exporting 할 수 있는 Observability Framework
- 오픈소스, 클라우드 네이티브 컴퓨팅 재단(CNCF, Cloud Native Computing Foundation) 프로젝트
- 분산 추적(Distributed Tracing) 및 모니터링을 위한 표준을 제공
- 벤더 종속적이지 않음, 큰 틀을 제공
- OpenTelemetry는 Spring Boot와 잘 호환되는 APM(Application Performance Monitoring) 솔루션, 자동 계측 가능
위 프래임워크와 함께 선택한 기술 스택
- LGT(M)
제안하는 아키텍쳐

OpenTelemetry Collector
설치 방식: 바이너리 다운로드 / Docker / Kubernetes(Helm Chart) 중 선택
Collector는 꼭 필요한가?
- 애플리케이션이 많을 때 → 모든 서비스가 개별적으로 Tempo랑 연결하는 것보다 효율적
- 샘플링, 필터링이 필요할 때 → Collector에서 간편하게 설정 가능. 오류 발생한 Trace만 Tempo로 보낼 수 있음
- 다른 백엔드로도 보내야 할 때 → Tempo뿐만 아니라 Zipkin, Jaeger, Loki 등에도 동시에 전송 가능
Collector는 필수가 아님, 하지만 확장성을 고려하면 강력한 도구!
대규모 MSA 환경에서는 Collector가 필수!
직접 구현해도 되나?
Java로 OpenTelemetry Collector 구현 가능
- OpenTelemetry가 공식적으로 제공하는 proto 정의 파일을 기반으로 Java 코드를 생성해야 함
하지만… 일반적인 방식은 아니며 비효율적일 수도 있음
- 기존 Go 기반 OpenTelemetry Collector보다 성능 저하 가능성 있음.
- 기능 추가 및 유지보수가 어려움 (기본 OpenTelemetry Collector는 이미 다양한 Exporter 제공).
- 프로토버프 버전 관리 및 업데이트 부담.
그래도 직접 Java로 Collector를 만들고 싶다면?
- ProtoBuf를 이용해 OTLP 데이터 처리
- gRPC 서버로 수신 후 필요한 백엔드로 Export
- 필요한 Receiver, Processor 및 Exporter를 추가 개발
결론: 가능하지만 OpenTelemetry 공식 Collector를 사용하는 것이 더 현실적!
내부 데이터 흐름 (Receiver → Processor → Exporter)
- Receiver(수집기): 외부 시스템(애플리케이션, 에이전트, 다른 Collector 등)에서 데이터를 수신예시: OTLP, Jaeger, Zipkin, Prometheus, Loki 등 다양한 수집기 지원
- Processor(처리기): 데이터를 필터링, 배치 처리, 속성 추가 등의 변환 작업 수행예시: batch, filter, transform 등 다양한 프로세서 사용 가능
- Exporter(전송기): 데이터를 최종 모니터링 시스템(Grafana Tempo, Prometheus, Loki 등)으로 전송
- 예시: Tempo, Zipkin, Jaeger, Loki, Prometheus 등 다양한 Exporter 지원
collector 설정은 yaml로
log, trace, metric 각각은 파이프라인으로 연결
설정 예시
receivers:
otlp:
protocols:
grpc: "0.0.0.0:4317" # gRPC 기본 포트
http: "0.0.0.0:55681" # HTTP 기본 포트
loki:
endpoint: "http://loki:3100"
prometheus:
config:
scrape_configs:
- job_name: 'otel-metrics'
static_configs:
- targets: ['localhost:9090']
processors:
batch: # 배치로 전송
timeout: 10s
attributes:
actions:
- key: "http.status_code"
value: "404"
action: "drop" # 404 응답 코드가 포함된 트레이스나 로그를 드롭
filterlogs:
match:
log:
severity: ERROR # ERROR 로그만 필터링
exporters:
otlp:
endpoint: "http://tempo:4317"
loki:
endpoint: "http://loki:3100"
prometheus:
endpoint: "http://prometheus:9090"
logging:
verbosity: detailed
service:
pipelines:
traces:
receivers: [otlp]
processors: [attributes, batch]
exporters: [logging, otlp]
logs:
receivers: [loki]
processors: [filterlogs, batch]
exporters: [loki, logging]
metrics:
receivers: [prometheus]
processors: [batch]
exporters: [prometheus]로그 전송기 - Promtail
중간에 Promtail 안 쓰고 바로 collector로 연결한다면?
Promtail을 사용하지 않으면, 애플리케이션이 직접 로그를 OpenTelemetry Collector로 전송해야 함.
- Collector가 로그 파일을 직접 읽어 Loki로 전송하는 방식
- 로그 포맷(구조화 로그 등)을 사전에 맞춰야 함
- 애플리케이션에서 직접 Collector로 Push (OTLP 사용)
- 파일 기반이 아니라 애플리케이션 내부에서 생성된 로그를 바로 전송 가능
기존 로그 파일을 그대로 활용하고 싶다면 Promtail → Collector → Loki
- Promtail에서도 로그 포매팅 가능
- Collector에서도 로그 변환 가능
- Loki에서도 포맷 조정 가능
Log 저장소 - Loki
Loki는 로그 수집, 저장, 쿼리를 위한 오픈 소스 로그 집계 시스템으로 별도의 데이터베이스 없이 파일 시스템이나 클라우드 스토리지, 객체 저장소 등을 사용하여 로그를 저장
참고: 왜 Loki?

Metric 저장소 - Prometheus
Prometheus는 수집된 메트릭 데이터를 저장하고 이를 쿼리할 수 있는 중앙 데이터베이스 역할을 하기 위한 것
꼭 있어야 하나?
springboot actuator prometheus 사용 시..
콜랙터에서 바로 그라파나와 연결하여 실시간 metric 확인 가능
다만 사용 시 아래의 혜택을 얻을 수 있음
- 메트릭 저장을 통한 장기적인 메트릭 분석 가능
- 고급 쿼리 기능 활용
- 알림 시스템 지원
Trace 저장소 - Tempo
Tempo 없이 Loki만으로 분산 추적이 가능할까?
- Tempo 없이 완전한 분산 추적은 어려움
- Trace ID를 로그에 남기면 Trace ID가 포함된 로그를 검색할 수는 있지만, 서비스 간 호출 관계(Span, Parent-Child 관계)는 분석 불가
- Tempo는 Trace 간 시간 흐름을 시각화하여, 어느 서비스가 느린지, 어디에서 지연이 발생하는지 확인 가능. Loki는 단순한 텍스트 로그 검색이라 이런 분석 불가
Tempo는 기본적으로 Push 방식(Polling 지원 X) 관련하여 아래 설정 가능
- Head-based sampling: 모든 요청을 추적하지 않고 일부만 추적(확률 설정) - 기본값
- Tail-based sampling: 모든 요청을 수집하지만 collector에서 특정 조건을 만족하는 요청만 저장하도록 설정(필터링 사용) / 어플리케이션 성능에 영향 없음
- 정상 요청은 버리고, 오류만 저장하도록 설정할 수도 있음
- 배치 설정: 일정량 쌓이면 한번에 Push하도록 설정
- Always on sampling: 모든 요청을 100% 저장, 데이터 저장 비용 증가 가능
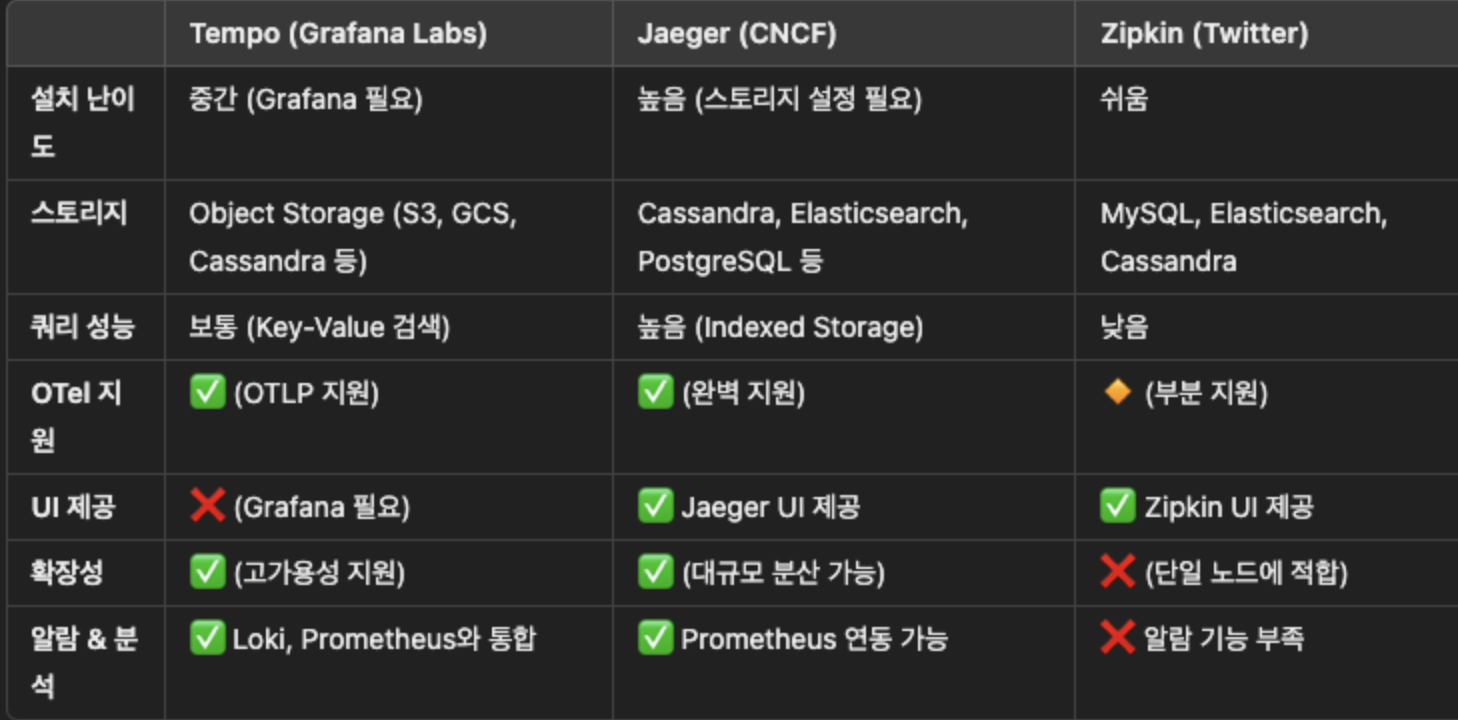
참고: 다른 trace 저장소와 비교
알람 관련
Grafana 방식
- Grafana는 Prometheus/Loki에서 데이터를 가져와 알람(Alert)을 설정 가능(템포 x)
장점
- UI로 알람을 설정할 수 있어 편리
- Alertmanager 없이 바로 메일/Slack/Webhook 전송 가능
단점
- 중앙 집중형 관리 어려움
- 코드 기반 관리 불가능
- 확장성 없음
Prometheus Ruler + Alertmanager 방식이 가장 표준적인 방식
(Loki, Premetheus, Tempo) → Prometheus Ruler → Alertmanager → Email/Slack/Webhook
Prometheus Ruler?
- Prometheus Ruler는 Prometheus 서버와 함께 동작(내장됨)하며, 알림 규칙(Alerting Rules)을 관리하는 기능을 제공
- Prometheus Ruler는 알람 규칙(Alerting Rules)을 처리하고, 이 규칙이 Trigger되면 Alertmanager에 알림을 보냄
- yaml 설정으로 관리
Alertmanager?
- Prometheus 및 Loki, Tempo 등에서 발생한 알람을 관리하고, 이메일, Slack, PagerDuty 등의 채널로 알림을 전송하는 역할을 하는 도구
- 알람 수신 및 라우팅, 집계, mute, 알람 중복 방지 등 기능이 있음
- 프로메테우스 설정에서 ruler를 사용하도록 설정 후 별도 파일(yaml)로 설정 관리
Loki에서 직접 알람 가능?
- Loki 자체적으로는 알람을 트리거할 기능이 제한적
- logql 쿼리를 사용하여 Prometheus Ruler에서 감지 후 Alertmanager로 전송하는 방식이 일반적
Prometheus에서 직접 알람 가능?
- Prometheus는 자체적으로 Prometheus Ruler를 통해 알람을 감지 가능
- 하지만 Alertmanager 없이 직접 알람을 보낼 수 없음
Tempo에서 직접 알람 가능?
- Tempo는 직접적인 알람 기능이 없음
- Trace 기반으로 메트릭을 생성한 후 Prometheus Ruler를 통해 감지하는 방식 사용
Prometheus Ruler + Alertmanager를 사용 시 장단점
장점
1. 유연한 알림 라우팅
- Alertmanager는 알림을 '라벨' 기반으로 라우팅할 수 있어서, 다양한 알림 조건에 대해 수신자를 유연하게 지정할 수 있음.
- 예를 들어, severity, project, team과 같은 라벨을 기반으로 알림을 각기 다른 수신자 그룹(메일, 슬랙, 웹훅 등)으로 전달할 수 있음.
- 라벨을 이용하여 프로젝트별로 혹은 환경 별로 다양한 알림 조건을 설정할 수 있음
2. 알림 집계 및 수집
- Alertmanager는 동일한 경고에 대해 여러 번 알림을 보내지 않도록 알림을 집계하고 알림 그룹화 기능을 제공
- 예를 들어, 여러 번 발생하는 동일한 경고를 하나의 알림으로 묶어서 처리할 수 있음
3. 알림 수신 채널 다채로움
- 알림을 다양한 채널(이메일, 슬랙, 페이지듀티, SMS 등)로 전송할 수 있음.
- Alertmanager는 알림을 설정한 대로 다양한 형식으로 전송할 수 있는 기능을 제공함
4. 정밀한 알림 조건 설정
- Prometheus Ruler에서 제공하는 고급 알림 규칙 설정을 통해, 알림 조건을 세밀하게 정의할 수 있음.
- 예를 들어, 특정 메트릭이 1분 동안 특정 값을 초과하거나, 특정 상황이 반복되는 경우에만 알림을 보내는 식으로 알림의 발생 조건을 세밀하게 조정할 수 있음.
단점
1. 설정이 복잡함
- 설정하는 화면이 없고 yaml 파일을 작성하는 방식
- 여러 팀이나 프로젝트별로 맞춤형 알림을 설정하는 경우, 설정 파일이 방대해질 수 있으며, 이를 관리하기 어려울 수 있다.
2. 리소스 요구사항
- Prometheus Ruler와 Alertmanager는 각각 다른 시스템과 연동되어야 하므로, 시스템 자원의 관리가 필요함. Prometheus의 수집 데이터 양이 많아지면 알림 평가에 드는 시간과 리소스가 커질 수 있다.
- 알림을 너무 많이 생성하거나 복잡한 계산을 수행하면 시스템에 부하를 줄 수 있음
도입 시 각 어플리케이션 수정 양은?
1. 아래 의존성 추가
// 애플리케이션에서 메트릭, 트레이스, 로그와 같은 관측 데이터를 수집하는 데 필요한 인터페이스를 제공; trace id 생성
implementation 'io.opentelemetry:opentelemetry-api:${version}'
// OpenTelemetry API의 구현체로, 실제 데이터를 수집하고 처리하는 기능을 제공; 데이터 수집
implementation 'io.opentelemetry:opentelemetry-sdk:${version}'
// Traces, Metrics, Logs 데이터를 OTLP(HTTP/gRPC) 프로토콜을 통해 Collector로 전송; 외부로 전송
implementation 'io.opentelemetry:opentelemetry-exporter-otlp:${version}'2. tracer 빈 등록 - 콜렉터 정보 등록
3. 로그백 설정
- logback.xml 파일에서 MDC(Mapped Diagnostic Context)를 사용하여 트래스 아이디와 스팬 아이디를 자동으로 포함시킬 수 있음
- 받은 요청에 트래스(Trace) 아이디가 있으면, 이미 존재하는 트래스 아이디를 그대로 사용하고, 새로운 스팬(Span)을 생성한다. 만약 요청에 트래스 아이디가 없다면, 새로운 트래스 아이디를 생성하고 이를 기반으로 스팬을 생성한다.
- 소스에서 수동으로도 트래이싱 정보 추가 가능(마킹 가능)
참고
오텔 설명
https://medium.com/@dudwls96/opentelemetry-%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80-18b6e4fe6e36
https://www.anyflow.net/sw-engineer/opensource-observability
위에서 제안한 아키텍쳐와 비슷한 구조로 세팅하는 과정 설명
https://blog.nashtechglobal.com/setup-observability-with-open-telemetry-prometheus-loki-tempo-grafana-on-kubernetes/
[토스] observability 시스템 구축 시 고려해야하는 사항들
https://youtu.be/Ifz0LsfAG94?si=cYAPtvm8eRy0Srk-
[nhn forward] nhn cloud가 구축한 사용 예시
https://youtu.be/EZmUxMtx5Fc?si=_YtHU2mDayS2uxKr
'architecture > sw architecture' 카테고리의 다른 글
| 람다 아키텍처 vs 카파 아키텍처 (0) | 2023.03.22 |
|---|---|
| [design] proxy pattern 프록시 패턴 (0) | 2022.04.25 |
