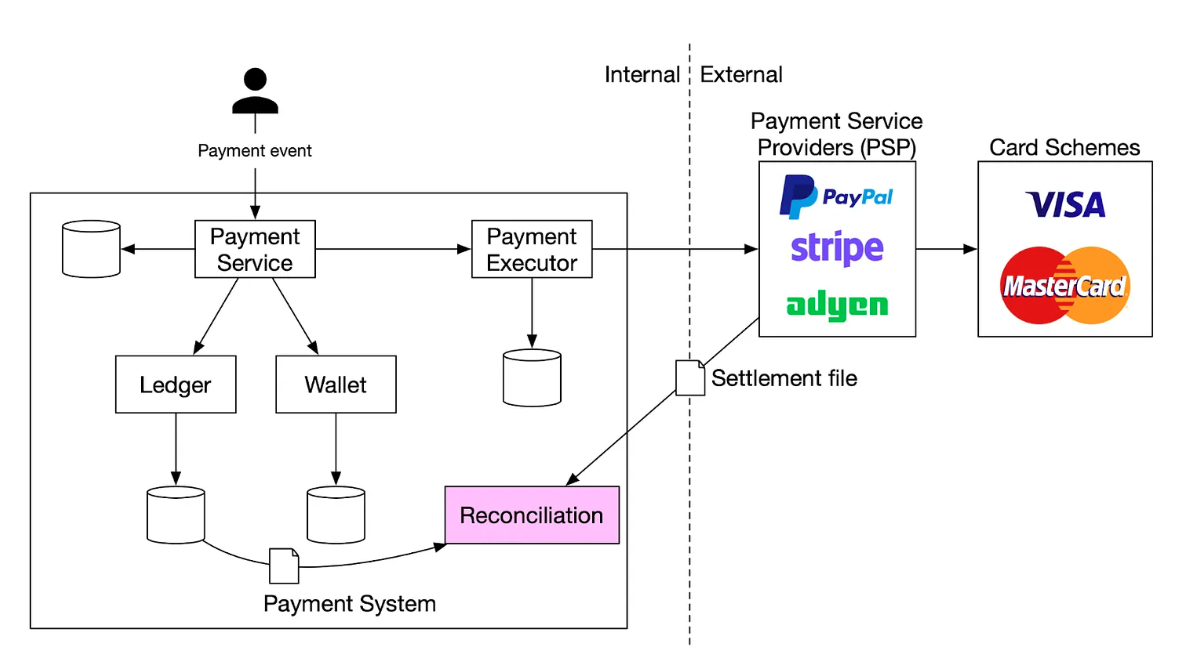
포인트
- 1,000,000 TPS
- 높은 안정성
- 트랜젝션
- A -> B로 이체한다고 가정
인메모리 샤딩
계정-잔액(map) 저장
레디스 노드 한대로 100만 TPS는 무리
클러스터를 구성하고 계정을 모든 노드에 균등하게 분산시켜야(파티셔닝, 샤딩)
- 분배하기 위해 키의 해시 값 mod 개수를 계산하여 분산
모든 레디스 노드의 파티션 수 및 주소는 주키퍼를 사용(높은 가용성 보장)
- 이체 요청 시 각 클라이언트의 샤딩 정보를 물어봐서 클라이언트 정보를 담은 레디스 노드를 파악
데이터 내구성이 없다는 단점 존재..

분산 트랜젝션
레디스 사용 시 원자적 트랜젝션은 어떻게? RDB로 교체?
두 번째 이체(B로 입금) 시 서비스가 죽는다면?
1. 저수준: 데이터베이스 자체에 의존; 2PC
- 실행 주체는 디비며 어플리케이션이 중간 결과를 알 수 없음
- 모든 데이터베이스가 X/Open XA만족해야(JtaTransaction; mysql 지원)
- 단점:
- 두 단계가 한 트랜젝션
- 락이 오랫동안 유지, 성능이 안 좋음
- 조정자가 단일 장애 지점(SPOF)

2. try-confirm/cancel
- -1 -> +1 해야
- 실행 주체는 어플리케이션이며 독립적 로컬 트랜젝션의 중간 결과를 알 수 있음
- 보상 트랜젝션이 별도로 구현되어 있고
- 1단계 2단계가 각각 다른 트랜젝션으로 구성됨; 여러 개의 독립적인 로컬 트랜젝션으로 구성
- 특정 데이터 베이스에 구애받지 않고 어플리케이션 단계에서 관리하고 처리
- 실행 도중 coordinator 다운되는 것을 대비하여 각 단계 상태정보를 테이블에 저장(분산 트랜젝션 ID의 각 단계별 상태)
- 취소를 대비해 실행 순서가 중요한데(+1을 하고 취소 시 -1을 해야 하는데 네트워크 이슈로 -1이 먼저 요청되는 경우)
- 취소가 먼저 도착하면 디비에 마킹하고 다음에 실행 명령이 오면 이전에 취소 명령이 있는지 확인(그림 12.12)
- 병렬가능


3. saga
- 모든 연산은 순서대로 정렬된다. 각 연산은 자기 디비에 독립적인 트랜젝션으로 실행된다.
- 연산은 첫 번째부터 마지막까지 순서대로 실행된다. 한 연산이 완료되면 다음 연산이 실행된다.
- 연산이 실패하면 전체 프로세스는 실패한 연산부터 맨 처음 연산까지 역순으로 보상 트랜젝션을 통해 롤백된다. 따라서 n개 연산을 실행하는 분산 트랜젝션은 보상트랜잭션 n개까지 총 2n개의 연산을 준비해야 한다.
- choreography: 이벤트를 구독하여 작업 수행; 비동기
- orchestration: 하나의 조정자가 모든 서비스가 올바른 순서로 작업하도록 조율
분산 트랜젝션의 경우 문제의 원인을 역추적하고 모든 계정에서 발생하는 연산을 감사(audit)할 수 없음
이벤트 소싱
- command: 의도가 명확한 요청; 순서가 중요 FIFO 큐(카프카)에 들어감
- A - $1 - C ->
- event: 검증된 사실로 실행이 끝난 상태; 과거에 실제로 있었던 일
- A -$1; C+$1 두 이벤트로 분리
- state: 이벤트가 적용될 때 변경되는 내용(여기서는 잔액)
- state machine: 이벤트 소싱 프로세스를 구동; 명령의 유효성을 검사하고 이벤트를 생성, 이벤트를 적용하여 상태를 갱신

시간 단축? (카프카 대신에)
1. 로컬 디스크
이벤트 소싱에 사용한 카프카(원격 저장소) 대신 로컬 디스크에 파일로 저장하여 네트워크 전송시간 줄일 수
순차적 읽기 쓰기가 이미 최적화되어 있어 빠름
잔액 정보를 RDB 말고 로컬 디스크에 저장: SQLite, RocksDB
- RocksDB: LSM(log structured merge tree) 사용하여 쓰기 작업 최적화
2. mmap
최근 명령과 이벤트를 메모리에 캐시 할 수도.. 메모리에 캐시 하면 로컬 디스크에서 다시 로드하지 않아도
mmap는 디스크 파일을 메모리 배열에 대응하여 메모리처럼 접근할 수 있게 하여 실행 속도를 높일 수 있음
재현성 reproducibility
이벤트를 처음부터 재생하면 과거 잔액 상태 재구성 가능
이벤트 리스트는 불변이고 상태 기계 로직은 결정론적이므로 이벤트 이력을 재생하여 만든 상태는 언제나 동일
계정 잔액 정확성 재검하거나, 코드 수정 후에도 시스템 로직이 올바른지 replay로 확인 가능
명령 질의 책임 분리 CQRS
계정 잔액을 공개하는 대신 모든 이벤트를 외부에 보내서 외부 주체가 직접 상태를 재구축 가능(읽기에 유리하게)
읽기 전용 상태 기계는 여러 개 있을 수 있는데, 이벤트 큐에서 다양한 상태 표현을 도출할 수 있다(단순 뷰, 정산 등).
eventual consistency
스냅샷: 과거 특정 시점의 상태
모든 것이 파일 기반일 때 재현 프로세스의 속도를 높이는 방법?
이벤트 소싱은 항상 처음부터 다시 읽어서 상태를 파악하는데, 그 대신 주기적으로 상태 파일을 저장하여 시간을 절약 가능
그 시점부터 이벤트 처리 시작, 보통 0시
보통 하둡에 저장
모든 것을 로컬 디스크로(데이터를 한 곳에 두기엔).. SPOF 위험..
높은 신뢰성을 보장할 유일한 데이터는 이벤트
높은 안정성을 제공하려면 이벤트 목록을 여러 노드에 복제해야 하는데 데이터 손실 없고 순서를 유지해야 한다.
합의 기반 복제(consensus based replication)
래프트 알고리즘 사용
- 래프트 알고리즘(Raft Algorithm)은 분산 시스템에서 합의를 이루기 위한 분산 합의 알고리즘으로, 특히 리더 선출과 로그 복제를 단순하고 이해하기 쉽게 설계한 것이 특징
- 일관성: Raft는 각 노드가 로그를 일관되게 유지하도록 보장하며, 리더 노드가 로그를 추가하거나 업데이트할 때, 이를 팔로워 노드들에게 전달한다. 모든 노드가 동일한 상태를 유지하도록 보장함으로써 데이터의 일관성을 유지
- 고가용성: Raft는 단일 노드 실패 또는 리더 실패와 같은 장애를 처리할 수 있도록 설계. 클러스터의 과반수 이상이 살아 있으면, 시스템은 안정적이고 일관성 있게 동작함
- Follower: 리더의 지시를 따르고, 리더의 Heartbeat를 수신하여 상태를 유지
- Candidate: 리더가 되기 위해 투표를 요청하고, 과반수의 투표를 얻으면 리더가 됨
- Leader: 클러스터를 관리하고, 클라이언트 요청을 처리하며, 로그 항목을 복제
- 리더 선출:
- Follower는 Leader로부터 Heartbeat 메시지를 정기적으로 수신
- 일정 시간 동안 Heartbeat가 없으면, Follower는 Candidate가 되어 새 리더 선출을 시도
- 다수의 노드로부터 투표를 받아야 리더로 선출
- 로그 복제:
- Leader는 클라이언트의 요청을 로그에 추가하고 이를 Follower에 복제
- 과반수의 Follower가 로그를 수락하고 이를 확인하면 Leader는 해당 로그 항목을 커밋
- 일관성 유지:
- Leader는 모든 노드가 동일한 로그 상태를 유지하도록 보장
- 새로운 리더가 선출되면, 로그 일관성을 확보하기 위해 추가 작업을 수행
리더 장애 처리:
- 리더 장애 발생:
- 리더가 장애를 겪어 더 이상 Heartbeat를 보내지 못하면, Follower는 일정 시간 동안 Heartbeat를 받지 못한 상태가 됨
- Follower는 Election Timeout이 지나면 Candidate 상태로 전환
- 리더 선출 과정:
- Candidate가 되면, 다른 노드에 투표를 요청하고 선거를 시작
- 과반수의 투표를 얻으면 Candidate는 새로운 Leader가 됨
- 새로운 Leader는 기존 로그의 일관성을 확인하고 필요한 경우 Follower에게 누락된 로그를 전송하여 동기화
- 장애 복구:
- 장애가 발생한 리더가 복구되면, Follower 상태로 전환
- 리더 선출 과정에서 새로운 리더가 선출되었기 때문에 복구된 노드는 더 이상 리더가 아님
팔로워 장애 처리:
- 팔로워 장애 발생:
- Follower가 장애를 겪으면, 로그 복제 및 Heartbeat 수신이 중단
- Leader는 계속해서 다른 Follower들과 로그를 복제하고 클러스터를 관리
- 팔로워 복구:
- 장애에서 복구된 Follower는 Leader로부터 현재 로그 상태를 동기화
- Leader는 AppendEntries 메시지를 통해 복구된 Follower에 누락된 로그를 보냄
- 복구된 Follower는 로그를 복제하고, 현재 상태를 동기화한 후 정상 운영을 재개
장애 상황에 따른 동작:
- 다수 노드 장애: 클러스터는 과반수의 노드가 살아있으면 정상 동작을 유지합니다. 과반수 이상이 실패하면 클러스터는 동작을 멈추고 장애 복구가 실시
- 네트워크 파티션: 네트워크가 분할되면, 두 개 이상의 그룹으로 나뉨. 각 그룹은 독립적으로 리더를 선출할 수 있지만, 과반수를 차지하는 그룹만이 유효한 리더를 가질 수 있음. 네트워크가 복구되면, 하나의 리더만 유지되도록 통합
장애 허용을 위한 메커니즘:
- Election Timeout: 리더의 장애를 감지하기 위한 타이머. 일정 시간 동안 Heartbeat가 없으면 선거가 시작
- Majority Agreement: 리더가 되려면 과반수의 노드로부터 투표를 받아야. 이는 장애가 발생하더라도 시스템이 계속 운영될 수 있도록 보장
- Log Consistency: 리더는 모든 팔로워가 일관된 로그 상태를 유지하도록 보장하며, 새로운 리더가 선출될 때 로그 일관성을 유지
CQRS에서 읽을 때(폴 vs 푸시)
풀 방식: 클라가 서버에게 request를 보낼 때 읽기 디비에서 가져옴
역방향 프록시: 캐시같이 디비에서 직접 가져가지 않고 만들어진 데이터를 가져가게 둔 중간 저장소
- 클라이언트와 서버 간의 중간 계층으로, 클라이언트 요청을 백엔드로 전달하고, 백엔드의 응답을 클라이언트로 반환;
- 이벤트 수신 후 역방향 프락시에 푸시하도록
프로세스 흐름:
- 이벤트 수신:
- 읽기 전용 상태 기계는 외부 시스템으로부터 이벤트를 수신. 이 이벤트는 상태 업데이트를 요구하는 데이터일 수 있음.
- 상태 업데이트 및 푸시:
- 상태 기계는 이벤트를 처리하고 내부 상태를 업데이트
- 업데이트된 상태는 즉시 역방향 프록시로 푸시. 푸시된 데이터는 클라이언트가 요청하기 전에 프록시에 전달되어 준비.
- 클라이언트 요청 처리:
- 클라이언트가 상태 데이터를 요청하면, 역방향 프록시는 백엔드 서버에 요청을 전달하는 대신, 이미 준비된 최신 상태를 클라이언트에 반환
비동기 이벤트 소싱 프레임워크를 동기식 프레임워크로 제공하기 위해 역방향 프록시(Reverse Proxy)를 추가하는 것은 클라이언트와 서버 간의 통신 방식의 차이를 조율하고, 비동기 시스템의 응답성을 개선하기 위한 전략
1. 비동기 이벤트 소싱 프레임워크의 특성:
- 이벤트 소싱(Event Sourcing): 시스템 상태를 이벤트의 시퀀스로 기록하고, 현재 상태를 이벤트를 재생하여 복구하는 방식
- 비동기 처리: 이벤트는 비동기적으로 생성되고 처리되며, 상태는 eventual consistency(최종 일관성)를 가짐. 이는 즉각적인 응답이 보장되지 않고, 처리 완료까지 시간이 소요될 수 있음
2. 동기식 프레임워크 제공의 필요성:
- 즉각적인 응답 필요: 동기식 시스템은 클라이언트가 요청을 보내면, 즉시 결과를 반환받기를 기대. 비동기 시스템의 특성상 바로 응답을 제공하기 어려운 상황에서, 동기적 동작을 요구하는 클라이언트와의 간극을 줄일 필요가 있음
- 클라이언트 요구: 많은 클라이언트는 동기적으로 동작하는 전통적인 API 사용에 익숙
3. 역방향 프록시의 역할: 역방향 프록시를 추가함으로써 비동기 시스템을 동기적으로 제공 가능
3.1. 응답 캐싱 및 버퍼링:
- 이벤트 결과 캐싱: 프록시는 비동기 이벤트가 처리된 결과를 캐싱하여 클라이언트의 요청에 대해 즉시 응답. 이벤트가 아직 처리되지 않았으면, 프록시가 응답을 보류하거나 기본 응답을 반환
3.2. 동기화된 응답 시뮬레이션:
- 상태 확인 및 응답 대기: 클라이언트의 요청이 들어오면 프록시는 이벤트 소싱 시스템에 상태를 확인하고, 동기적 방식으로 응답을 보류하다가 결과가 준비되면 반환. 이는 동기 호출로 클라이언트에 투명하게 처리되며, 실제로는 백엔드에서 비동기적으로 처리.
3.3. 비동기 이벤트의 프리로드 및 상태 추적:
- 사전 이벤트 처리: 프록시는 예상되는 이벤트나 데이터를 미리 가져와(이벤트를 받아서) 클라이언트 요청이 들어왔을 때 빠르게 제공. 이를 통해 동기적 행동처럼 느껴지게 함.
4. 의미와 장점:
- 사용자 경험 개선: 클라이언트는 비동기적 시스템의 지연 시간이나 일관성 문제를 느끼지 않고, 동기적으로 즉각적인 응답을 받음
- 시스템 간 통합: 비동기 시스템을 사용하면서도 동기적 API가 필요한 클라이언트와 통합할 수 있어, 다양한 환경에서의 호환성이 증가
- 복잡성 분리: 비동기 처리의 복잡성을 역방향 프록시에서 관리하고, 클라이언트와의 인터페이스를 단순하게 유지가능
5. 고려 사항:
- 응답 시간 증가: 프록시에서 동기적 응답을 시뮬레이션하는 과정에서 처리 지연이 발생할 수
- 상태 일관성 관리: 프록시가 비동기 이벤트 결과를 반환할 때, 상태 일관성을 관리하는 로직이 필요
- 추가 인프라 비용: 역방향 프록시를 운영하는 데 추가적인 인프라와 관리 비용이 발생할 수
6. 근데 이 역할을 할 때 꼭 프록시를 써야하는가? 그냥 다른 중간 서버를 두면 되는거 아냐?

역방향 프록시를 사용함으로써 보안을 강화하거나 로드 밸런싱을 강화할 수 있음. 중간 서버는 유연성은 높지만 속도나 유지보수 등 필요..
분산 이벤트 소싱
TC/C 또는 사가 조정자가 단계별 상태 테이블에 각각의 작업 상태를 다 저장하여 트랜젝션 상태를 추적하는 게 포인트

- 사가 또는 tc/c 적용
- 유저가 서로 다른 위치의 디비에 있다고 가정
- raft 알고리즘 적용
- 역방향 프록시 적용
'개발 > 도서 스터디' 카테고리의 다른 글
| [대규모 시스템 설계 기초2] 5장 지표 모니터링 및 경보 시스템 (0) | 2025.01.25 |
|---|---|
| [대규모 시스템 설계 기초2] 4장 분산 메세지 큐 (0) | 2025.01.24 |
| [대규모 시스템 설계 기초2] 13장 증권 거래소 (0) | 2025.01.18 |
| [대규모 시스템 설계 기초2] 11장 결제시스템(exactly once) (1) | 2025.01.17 |
| 자바와 Junit을 활용한 실용주의 단위 테스트 7장 (0) | 2023.08.08 |