
반응형
1. 대용량 데이터를 처리할 때의 주요 고려사항은 무엇인가요?
- 대용량 데이터 처리에서는 확장성, 성능, 데이터 일관성 등을 고려해야 합니다.
- 데이터를 효율적으로 저장하고 처리하기 위해 분산 시스템을 활용하고(확장성)
- 캐싱 전략을 사용하여 읽기 성능을 높입니다.
- 데이터 중복 방지와 실패 시 복구 전략이 필요합니다.
- 중복방지: 멱등성 API(PUT); 디비에 UNIQUE KEY잡아서 중복 데이터 삽입 안되게
- Redis 또는 Memcached를 사용해 데이터 처리 전 고유 키를 캐싱하여 중복 여부를 빠르게 확인할 수 있습니다. 예를 들어, 특정 ID가 Redis에 존재하면 중복으로 간주하고 처리하지 않는 방식입니다.
- 복구 전략
- 트랜잭션과 롤백 (Transaction & Rollback)
- RDBMS의 트랜잭션 기능을 사용해 작업 단위로 처리하고, 실패 시 모든 작업을 롤백하여 데이터 일관성을 유지합니다. 트랜잭션 단위가 클 경우에는 단계별로 커밋을 처리하는 Savepoint를 활용할 수도 있습니다.
- NoSQL 데이터베이스에서도 MongoDB와 같은 시스템은 단일 문서 수준에서 트랜잭션을 지원하고, Cassandra는 클라이언트 라이브러리에서의 조정을 통해 일부 트랜잭션 효과를 제공할 수 있습니다.
- 분산 트랜잭션 및 분산 락
- 여러 시스템 간 트랜잭션을 위해 2PC (Two-Phase Commit) 또는 SAGA 패턴을 사용합니다. SAGA 패턴은 트랜잭션 단위로 실행되는 작업을 분리하고, 오류 발생 시 보상 작업을 수행해 데이터 일관성을 유지합니다.
- 데이터 충돌을 방지하기 위해 분산 락을 적용할 수 있습니다. 예를 들어, Redis의 SETNX 명령을 사용해 분산 잠금을 구현하여, 하나의 리소스에 동시에 접근하는 것을 방지할 수 있습니다.
- 재시도 및 지연 재시도 (Retry & Backoff)
- 네트워크 문제나 일시적인 오류에 대해 재시도 정책을 설정하여 실패한 요청을 다시 시도할 수 있습니다. 무조건 재시도하기보다 지수적 백오프(Exponential Backoff) 전략을 사용해 지연 시간을 점진적으로 늘리면 서버에 부담을 줄일 수 있습니다.
- 과도한 요청 방지: 동일한 요청을 반복적으로 보내는 것을 막아 서버가 과부하에 걸리지 않도록 하여, 서버가 일정한 시간 동안 안정적으로 요청을 처리할 수 있습니다.
- 서버 복구 시간 확보: 지연 시간이 늘어날수록 서버가 안정화되거나 부하를 해소할 시간이 생기므로, 문제 해결 후 요청을 성공적으로 처리할 가능성이 커집니다.
- 네트워크 효율성 향상: 클라이언트와 서버 간의 불필요한 트래픽을 줄이고, 네트워크 자원을 효율적으로 사용하게 합니다.
- 트랜잭션 유지 시간이 너무 길어지면 잠금 자원이나 연결 자원이 오래 점유되어 다른 요청이나 트랜잭션에 영향을 줄 수
- 최대 재시도 횟수와 백오프 한계 설정(무한히 기다리지 않도록)
- 장기 트랜잭션을 여러개의 작은 단위로 분리하거나 비동기 처리하여 트랜젝션이 길어지지 않도록
- 트랜젝션 타임아웃 설정
- 회복 가능한 트랜잭션 설계
- 장애나 재시도가 필요한 경우에도, 중간까지 완료된 트랜잭션 부분이 유지되고 나머지 작업을 이어갈 수 있도록 분산 트랜잭션 관리나 SAGA 패턴을 활용해 트랜잭션을 보다 유연하게 설계합니다.
- Circuit Breaker 패턴을 함께 사용해 오류가 지속될 경우 특정 시간 동안 요청을 차단해 전체 시스템의 안정성을 높일 수 있습니다.
- 네트워크 문제나 일시적인 오류에 대해 재시도 정책을 설정하여 실패한 요청을 다시 시도할 수 있습니다. 무조건 재시도하기보다 지수적 백오프(Exponential Backoff) 전략을 사용해 지연 시간을 점진적으로 늘리면 서버에 부담을 줄일 수 있습니다.
- 데이터 복제 및 백업
- 데이터 손실을 방지하기 위해 백업 및 복제 전략을 설정합니다. 예를 들어, RDBMS에서는 정기적인 백업과 함께 로그 기반 복구(Log-based Recovery)를 사용해 장애 발생 시 특정 시점으로 데이터를 복원할 수 있습니다.
- 분산 시스템의 경우 데이터 복제를 통해 여러 노드에 데이터를 분산 저장하여 데이터 유실 가능성을 줄입니다. Cassandra나 MongoDB와 같은 분산 DB에서는 노드 간 자동 복제를 지원해 복구성을 높입니다.
- 이벤트 소싱과 로그 기반 복구
- 이벤트 소싱을 통해 상태 변화가 발생할 때마다 이벤트를 저장해, 장애 발생 시 해당 이벤트를 재생하여 이전 상태로 복구할 수 있습니다.
- 로그 기반 복구 시스템은 Kafka와 같은 메시지 큐에 이벤트를 기록해 실시간으로 복구할 수 있으며, 장애가 발생해도 로그를 재생하여 데이터 상태를 원래대로 복원할 수 있습니다.
- 트랜잭션과 롤백 (Transaction & Rollback)
- 중복방지: 멱등성 API(PUT); 디비에 UNIQUE KEY잡아서 중복 데이터 삽입 안되게
- 마지막으로 비용 절감 측면에서 클라우드 서비스를 활용하거나 데이터 파이프라인의 최적화가 필요할 수 있습니다.
2. 대용량 데이터를 실시간으로 처리해야 한다면 어떤 아키텍처를 선택할 것인가요?
- 실시간 데이터 처리가 필요한 경우 이벤트 기반 아키텍처(EDA)와 스트리밍 처리 시스템을 선호합니다. Apache Kafka와 같은 메시지 브로커를 통해 데이터를 스트리밍으로 전송하고, Apache Flink 또는 Spark Streaming을 사용해 데이터를 실시간으로 처리합니다. 이렇게 하면 지연을 최소화하면서도 높은 처리량을 유지할 수 있습니다.
- CQRS: 조회와 데이터변경을 시스템적으로 분리하여 각각 최고의 성능을 낼 수 있도록 개선, 독립적으로 확장 가능하도록 개발
- 변경: RDBMS, 조회: MONGO, ELASTIC..
3. 대용량 데이터 처리 중 병목현상을 해결한 경험이 있나요?
- 디비
- 이전 프로젝트에서 MySQL 데이터베이스에서 많은 데이터를 읽어와야 하는 작업이 있었는데, 특정 쿼리에서 병목 현상이 발생했습니다. 이를 해결하기 위해 인덱스를 최적화하고, 비동기 처리를 도입해 읽기 작업을 분산했습니다. 또한, 캐싱 레이어를 추가해 반복되는 읽기 작업을 줄였고, 결과적으로 처리 속도를 크게 향상시켰습니다.
- 서비스
- 긴 트랜젝션을 여러 개의 작은 트랜젝션으로 나눔
- 트랜젝션 안에 외부 api 호출이 있어
- api호출 성공 시 db작업하도록 개선
- transaction outbox pattern + polling publish pattern으로 바꾼 적 있음
4. MapReduce와 같은 분산 처리 기법을 설명해 주시고, 이를 언제 사용하면 좋을까요?
MapReduce는 대규모 데이터를 분산하여 처리할 수 있게 해주는 프레임워크입니다. 데이터를 맵(Map) 단계에서 분산하여 처리하고, 리듀스(Reduce) 단계에서 그 결과를 통합합니다. 주로 배치 작업에 적합하며, 대규모 로그 분석, 대량의 텍스트 데이터 처리, ETL 작업 등에 사용됩니다.
5. 대용량 데이터의 효율적 관리를 위해 어떤 데이터베이스를 사용할 것인가요?
데이터 특성과 처리 요구 사항에 따라 데이터베이스를 선택
- 실시간 읽기 및 쓰기가 빈번한 경우 : Redis와 같은 인메모리 데이터베이스를 고려
- 로그나 이벤트 데이터를 저장 : 쓰기 성능과 확장성이 중요한데, 이러한 요구에 맞는 데이터베이스로는 Cassandra와 MongoDB, Elasticsearch 등
- Cassandra
- 분산형 NoSQL 데이터베이스로, 특히 칼럼 패밀리(Column Family) 기반의 데이터 모델을 사용하는 시스템. 높은 쓰기 성능과 수평 확장성 덕분에 대량의 로그 데이터를 빠르게 저장 가능. 분산 구조로 데이터가 여러 노드에 분산되어 저장되고 복제되어 고가용성과 안정성이 높습니다.
- 적합한 경우: 대규모의 로그 데이터를 수집하고 분석하는 경우, 트래픽이 많이 발생하는 IoT 데이터 또는 웹 트래픽 로그 등에서 효율적입니다.
- 장점: 특히 쓰기 성능이 뛰어나며 노드 간의 데이터 복제와 장애 허용성이 우수해, 고가용성 환경에서도 데이터를 안정적으로 처리할 수 있습니다. 노드 추가 시 용량이 수평으로 확장되며 성능 저하 없이 대규모 데이터를 처리할 수 있습니다.
- MongoDB
- 문서 기반 NoSQL 데이터베이스로, JSON 형식의 유연한 데이터 구조를 지원합니다. 복잡한 스키마를 요구하지 않기 때문에 로그 데이터의 다양한 필드와 동적 스키마를 저장하는 데 적합합니다.
- 적합한 경우: 애플리케이션 로그, 이벤트 데이터를 JSON 형태로 저장해 실시간으로 조회하고 분석해야 하는 경우. 대화형 애플리케이션에서 발생하는 로그 데이터와 이벤트 처리에 적합합니다.
- 장점: 샤딩(데이터 분산 저장)을 통해 수평 확장이 가능하며, 다양한 인덱싱을 통해 실시간 쿼리에 적합한 구조를 제공합니다.
- Elasticsearch
- 분산형 검색 엔진으로 로그와 이벤트 데이터를 저장하고, 실시간 검색과 분석을 수행하는 데 특화된 시스템입니다. Kibana와 함께 사용하면 데이터를 시각화할 수 있어 로그 모니터링과 분석에 특히 유용합니다.
- 적합한 경우: 로그 모니터링, 애플리케이션 성능 관리(APM), 보안 로그 분석, 실시간 검색 등이 필요한 경우. ELK(Elasticsearch, Logstash, Kibana) 스택으로 많이 사용됩니다.
- 장점: 실시간 검색과 시각화 기능이 강력하며, 텍스트 기반의 로그 데이터에서 유용한 인사이트를 빠르게 얻을 수 있습니다.
- Cassandra
- 데이터 일관성이 중요한 트랜잭션성 데이터 : MySQL, PostgreSQL과 같은 RDBMS가 적합
RDBMS는
- 데이터 일관성이 중요할 때.
- 읽기와 쓰기 작업이 동시에 중요하며, 균형이 필요할 때.
- 데이터가 정형화되어 있고 관계형 모델에 적합할 때.
ACID(Atomicity, Consistency, Isolation, Durability)를 엄격히 준수하기 때문에:
- 쓰기 성능이 뛰어난 NoSQL 시스템(Kafka, Cassandra 등)에 비해 상대적으로 느릴 수 있음.
- 대규모 읽기 작업은 JOIN, GROUP BY와 같은 복잡한 쿼리 때문에 느려질 수 있음.
A 계좌에서 100원을 출금하고 B 계좌에 입금.
- Atomicity: 출금과 입금이 모두 성공하거나 둘 다 실패.
- Consistency: 트랜잭션 전후에 전체 잔액(예: 1,000원)은 변하지 않음.
- Isolation: 다른 트랜잭션은 이 작업이 완료되기 전까지 중간 상태를 볼 수 없음.
- Durability: 트랜잭션이 완료된 후에는 시스템 오류가 발생해도 데이터가 보존됨.
6. 대용량 데이터 처리에서 성능을 최적화하기 위해 사용할 수 있는 기법에는 어떤 것들이 있나요?
아키텍쳐적인 방법:
- 캐싱 레이어를 추가해 빈번히 조회되는 데이터를 미리 저장
- 비동기 처리를 통해 응답시간을 줄여 타임아웃 방지
- 네트워크 요청, 파일 IO등의 시간이 오래걸리는 작업을 비동기로 처리하면 메인 스레드가 다른 작업을 수행할 수 있어 리소스를 효율적으로 사용할 수
- 배치 처리로 시스템 자원을 효율적으로 사용
- 데이터를 한꺼번에 처리해 트랜잭션 관리나 데이터 일관성 유지에 유리
- 주로 비업무 시간이나 서버 부하가 적은 시간대에 작업을 수행해 시스템 자원을 효율적으로 사용
디비적인 방법:
- 인덱스를 적절히 사용하여 데이터 검색 속도를 높임
- 데이터 파티셔닝과 샤딩을 통해 데이터베이스 부하를 분산
7. 대용량 데이터를 다룰 때 발생할 수 있는 장애 및 복구 전략에 대해 설명해 주세요.
대용량 데이터 시스템에서 장애가 발생할 경우, 데이터 유실을 방지하고 빠르게 복구하는 것이 중요
서비스적:
- 디비 등 데이터 복제(master replica)를 통해 고가용성을 확보
- Kafka와 같은 시스템에서는 메시지 리플레이를 통해 복구
- Dead Letter Queue (DLQ)와 Retry 메커니즘을 통해 이벤트 처리 실패에 대비.
인프라적:
- 장애가 발생했을 때 특정 노드로 트래픽을 우회하거나, 백업 데이터에서 복원
- 클라우드 서비스를 사용할 경우 데이터 센터의 지역 분산(재해복구 관련 DR)을 통해 데이터 유실 위험을 줄여
MSA:
- (IF 분산) 소스 내부적으로는 circuit braker pattern 적용하여 장애가 전파되지 않도록
대용량 시스템의 장애와 분산 시스템의 장애는 약간 관점이 다르다.
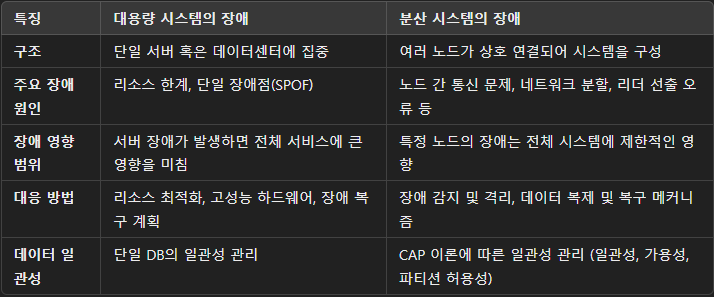
하지만 대용량 시스템의 단점인 SPOF를 막기 위해서는 분산 시스템으로 구성해야하고 그렇게되면 결국 대용량 + 분산 시스템의 특징을 모두 지닐 수 밖에 없게 된다.
728x90
반응형
'architecture > micro service' 카테고리의 다른 글
| [Dead Letter] PDL, CDL (0) | 2024.11.14 |
|---|---|
| E2E(end to end) 테스트 (0) | 2024.11.13 |
| transaction outbox pattern + polling publisher pattern (0) | 2024.11.07 |
| 2PC vs 2PL (2) | 2024.11.06 |
| [arch] EDA, event sourcing, saga, 2pc (0) | 2024.02.29 |