개발/도서 스터디
[대규모 시스템 설계 기초2] 6장 광고 클릭 이벤트 집계
방푸린
2025. 1. 26. 22:28
반응형
포인트
- 광고 클릭시 로그 쌓음
- 광고 아이디 시간 유저 국가 등
- 집계 필요
- 특정 광고에 대한 지난 n분간의 클릭 이벤트 수
- 지난 x분간 가장 많이 클릭된 광고 y개
- 광고 클릭 QPS = 10,000
- 최대 광고 클릭은 50,000로 가정
- 클락 하나당 0.1kb 저장 용량 필요하다고 가정; 하루 100기가; 월간 3테라
방식
- 로그에 정형화되게 남기면 1분마다 집계하여 저장해두고 요청이 오면 집계데이터를 filter하거나 sum하거나 등 가공하여 내림
- 원시 데이터도 저장하고 집계 데이터도 저장하고
- 원시 데이터를 통한 재집계 지원
- 질의는 집계된 데이터에만
- 시간이 지나면 원시 데이터는 아애 옮겨버려
- 원시 데이터는 쓰기양이 많으므로 시계열 데이터에 유리한 influxDB나 카산드라 추천
집계 서비스
로그가 들어오면 메세지 큐에 쌓이고 큐에서 원시 데이터 저장소에 저장하고 집계 서비스로 흘러간다
mapReduce 프레임워크 사용; mapReduce 프레임워크에 좋은 모델은 DAG(directed acyclic graph)모델
1. MapReduce Framework
- 개요: MapReduce는 대규모 데이터를 분산 환경에서 처리하기 위한 프로그래밍 모델.
- Map 단계: 데이터를 키-값 쌍으로 매핑.
- Reduce 단계: 동일한 키를 가진 값을 집계 및 계산.
- 작업 처리 흐름:
- 데이터는 Map 단계에서 병렬 처리되고, Shuffle/Sort 과정을 통해 Reduce 단계로 전달.
- Reduce 단계에서 최종 결과를 생성.
- 제약:
- 단순한 작업 흐름으로 인해 복잡한 작업 간 의존성을 표현하거나 최적화하기 어렵다.
- 한 번에 단일 Map → Reduce 작업만 가능하므로 다중 스테이지 워크플로우는 비효율적.
2. DAG 모델
- 개요: DAG는 작업 간 의존성을 표현하기 위해 사용되는 방향성 비순환 그래프.
- 각 노드: 개별 작업(예: Map, Reduce, 기타 연산).
- 각 간선: 작업 간의 데이터 의존성을 나타냄.
- "비순환(Acyclic)": 작업이 완료되면 되돌아가지 않음(순환 없음).
- 특징:
- 복잡한 작업 워크플로우를 시각적으로 표현 가능.
- 병렬로 실행 가능한 작업을 식별하여 최적화 가능.
- 작업 실행 순서를 명확히 정의.
3. 카프카 스트림즈 사용
- 카프카 토픽으로 들어오는 데이터를 소비하며 시간 기반의 집계 처리
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> input = builder.stream("input-topic");
input
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofMinutes(1)))
.count()
.toStream()
.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();1분 단위 데이터 처리 흐름
1. 데이터 수집
- 예를 들어, Kafka의 프로듀서가 데이터를 지속적으로 전송하고, Spark/Flink/Kafka Streams가 이를 소비합니다.
2. 윈도우에 데이터 저장
- 데이터는 버퍼 또는 임시 저장소에 저장됩니다.
- Spark Streaming: RDD 내부에 데이터가 임시 저장됨.
- Flink: State Backend(예: RocksDB)에서 상태 관리.
- Kafka Streams: 내부 상태 저장소를 통해 관리.
3. 1분 타이머 완료 시 처리
- 타이머가 1분에 도달하면:
- 데이터를 sum, count, average 등으로 집계.
- 집계 결과를 특정 주체로 전달.
4. 데이터 삭제
- 1분 타이머가 종료되면 해당 윈도우의 데이터는 메모리에서 삭제되거나 다음 처리 단계로 넘깁니다.
- Spark: 새로운 마이크로 배치를 시작하며 이전 데이터는 삭제.
- Flink/Kafka Streams: 윈도우 종료와 함께 상태를 정리.

스트리밍 vs 일괄 처리
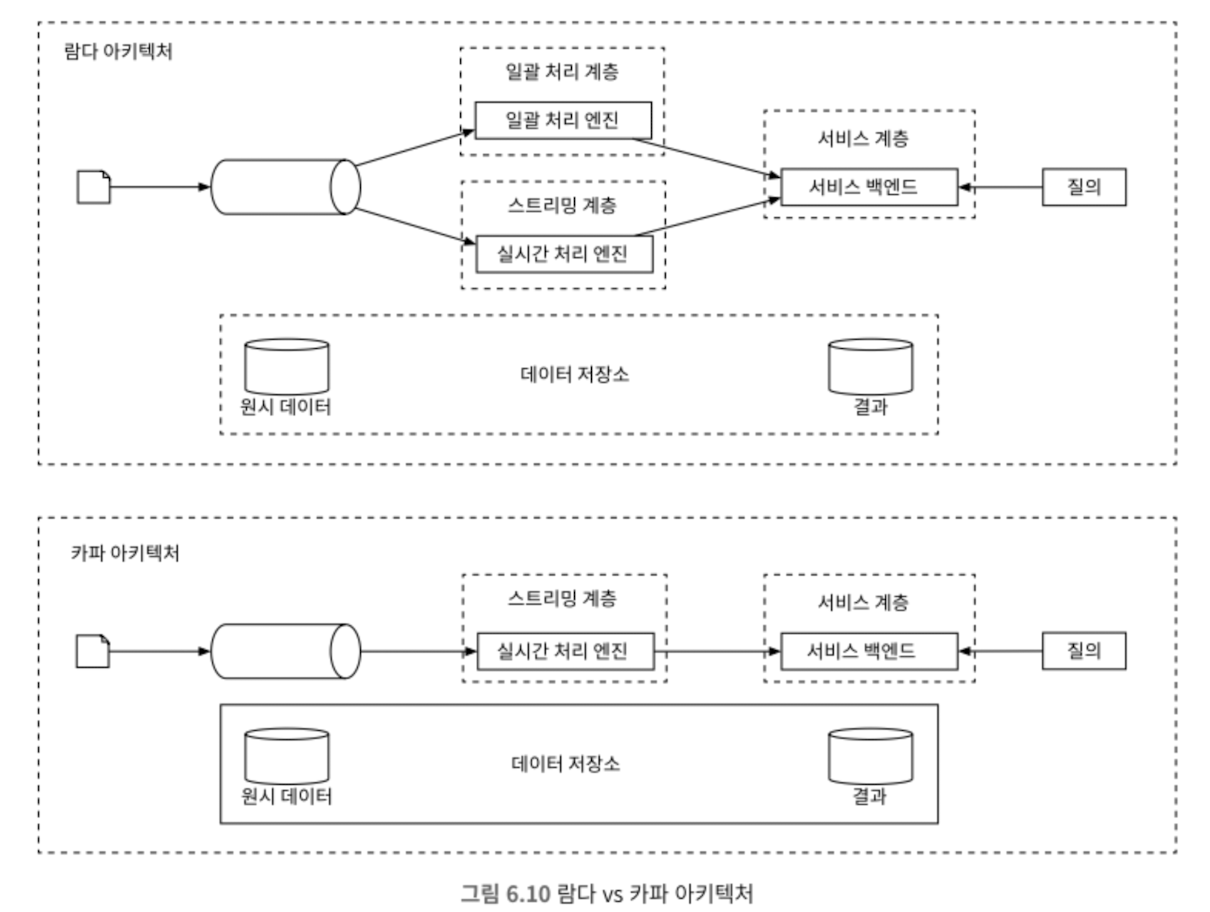
람다 아키텍처의 주요 구성
배치와 스트리밍을 동시에 지원하는 시스템 아키텍쳐
- Batch Layer (배치 레이어):
- 역할: 대규모의 정적 데이터(이력 데이터)를 처리하고 정확한 분석 결과를 제공합니다.
- 1분 동안 수집된 데이터를 주기적으로 처리해 정확한 집계 결과 생성.
- 특징:
- 주기적으로 데이터를 처리.
- 데이터의 **불변성(Immutable)**을 보장하여 과거 데이터를 다시 분석하거나 복구가 가능.
- 주요 기술:
- Hadoop, Spark, Hive 등.
- 산출물:
- 주기적으로 계산된 배치 뷰(Batch View).
- Speed Layer (스피드 레이어):
- 역할: 실시간으로 들어오는 데이터를 빠르게 처리하여 최신 정보를 제공합니다.
- 실시간 데이터 스트림을 활용해 1분 이내의 최신 데이터를 반영.
- 특징:
- 지연(latency)을 최소화.
- 데이터를 임시 저장하거나 간단한 처리를 수행.
- 주요 기술:
- Apache Kafka, Storm, Flink, Spark Streaming 등.
- 산출물:
- 최신 상태를 반영한 실시간 뷰(Realtime View).
- Serving Layer (서빙 레이어):
- 역할: 배치 뷰와 실시간 뷰를 결합해 최종 데이터를 사용자에게 제공.
- 배치 결과와 실시간 데이터를 통합해 최종 집계 데이터를 제공.
- 특징:
- 두 레이어의 결과를 통합하여 질의(Query)에 응답.
- 읽기 요청에 최적화된 시스템.
- 주요 기술:
- Elasticsearch, Cassandra, HBase 등.
람다 아키텍처의 데이터 처리 흐름
- 데이터 수집:
- 데이터를 Batch Layer와 Speed Layer에 동시에 전달.
- Batch Layer:
- 데이터 전체를 처리해 정확한 배치 뷰를 생성.
- 처리 속도가 느릴 수 있지만, **정확성(Accuracy)**이 핵심.
- Speed Layer:
- 실시간 데이터를 처리하여 최신 상태를 반영한 실시간 뷰를 생성.
- 처리 속도가 빠르지만, 최종적으로 정합성이 보장되지 않을 수 있음.
- Serving Layer:
- 배치 뷰와 실시간 뷰를 통합해 사용자에게 최신 데이터 제공.
장점
- 실시간성과 정확성:
- 배치 처리의 정확성과 실시간 처리의 신속성을 동시에 제공.
- 확장성:
- 배치 레이어와 스피드 레이어 모두 분산 시스템 기반으로 확장 가능.
- 유연성:
- 과거 데이터를 보존해 언제든 재처리가 가능.
단점
- 복잡성 증가:
- 두 개의 레이어를 유지관리해야 하므로 운영이 복잡.
- 데이터 중복 처리:
- 배치와 실시간 레이어에서 동일 데이터를 중복 처리.
- 비용 문제:
- 두 레이어를 운영하므로 인프라 비용 증가.
사용 사례
- 소셜 미디어 분석:
- 실시간으로 트렌드를 파악(Speed Layer).
- 장기적인 사용자 행동 분석(Batch Layer).
- 금융 데이터 처리:
- 실시간 거래 감시(Speed Layer).
- 전체 거래 기록 분석(Batch Layer).
카파 아키텍처의 주요 개념
실시간 데이터 스트림 처리를 중심으로 구성되며, 배치 처리 레이어를 없애고 단일 스트림 처리 파이프라인으로 모든 데이터를 처리
- 단일 데이터 파이프라인:
- 모든 데이터 처리를 스트림 기반으로 수행.
- 배치와 실시간 처리를 동일한 데이터 처리 엔진을 사용해 통합.
- 이벤트 소싱(Event Sourcing):
- 데이터를 이벤트 로그로 기록하며, 재처리(replay)를 통해 필요한 분석 작업 수행.
- Kafka Topics 같은 로그 기반 저장소를 활용.
- 일관성(Consistency) 및 유연성:
- 데이터의 재처리를 통해 정합성을 유지하고, 새로운 처리 로직 적용 가능.
- 재처리(Replay):
- 데이터 로그를 다시 읽어 과거 데이터를 재분석하거나, 새롭게 정의된 처리 방식으로 기존 데이터를 처리.
카파 아키텍처의 주요 구성 요소
- 데이터 소스:
- 데이터는 실시간으로 수집되어 로그 저장소로 들어갑니다.
- 예: IoT 센서, 웹 클릭 로그, 트랜잭션 기록 등.
- 로그 저장소:
- 데이터의 단일 진실 소스(Single Source of Truth)로 사용됩니다.
- 예: Apache Kafka, Pulsar.
- 로그 저장소는 데이터를 소비자가 원하는 속도로 읽고 처리할 수 있도록 지원.
- 스트림 처리 엔진:
- 실시간 데이터 처리를 수행하며, 배치와 실시간 처리를 동일한 방식으로 처리합니다.
- 예: Apache Flink, Kafka Streams, Apache Beam.
- 저장 및 조회 시스템:
- 처리된 데이터를 저장하고 사용자 쿼리에 응답합니다.
- 예: Elasticsearch, Cassandra, HBase.
카파 아키텍처의 데이터 처리 흐름
- 데이터 생성 및 수집:
- 데이터 소스에서 이벤트를 수집하여 로그 저장소에 저장.
- 로그 저장소:
- 모든 이벤트는 Kafka Topic과 같은 로그에 저장됩니다.
- 이 데이터는 소비자(Consumer)가 처리할 때까지 유지.
- 스트림 처리:
- 스트림 처리 엔진이 데이터를 실시간으로 처리.
- 재처리가 필요할 경우 로그 저장소를 다시 읽어 과거 데이터를 처리.
- 결과 저장:
- 처리된 데이터를 데이터베이스나 검색 시스템에 저장.
- 결과는 사용자 요청에 따라 즉시 제공.
장점
- 단순화:
- 배치와 실시간 처리를 통합해 관리 복잡성 감소.
- 유연성:
- 로그 저장소에서 데이터를 재처리할 수 있어 새로운 요구사항에 적응 가능.
- 확장성:
- 로그 기반 시스템(Kafka)은 대규모 데이터를 효율적으로 처리하고 확장 가능.
- 신뢰성:
- 로그 저장소를 통해 데이터 유실 방지.
단점
- 재처리 비용:
- 로그 저장소에서 과거 데이터를 읽어 재처리하는 데 시간이 오래 걸릴 수 있음.
- 기술 의존성:
- Kafka, Flink와 같은 특정 기술에 크게 의존.
- 성능 병목:
- 실시간 스트림 처리 엔진이 데이터 처리 속도를 제한할 가능성.
집계 기준 시각
- 이벤트 발생 시각
- 클라이언트/요청 시간 기준 -> 정확한 집계가 가능하지만 시간 조작 가능성도 있음
- 처리 시각
- 서버 도착 시간 기준 -> 안정적이지만 지연되는 이벤트는 부정확함
- 이벤트 발생 시각 + 워터마크 기법
워터마크의 개념
워터마크(Watermark)는 데이터 스트림 처리에서 이벤트 시간(Event Time)을 기반으로 지연 데이터를 처리하는 중요한 개념입니다.
주로 실시간 집계 및 윈도우 연산에서 사용되며, 늦게 도착한 데이터를 효율적으로 다룰 수 있도록 설계되었습니다.
- 이벤트 시간(Event Time): 데이터가 실제로 생성된 시간을 의미. (예: 로그의 타임스탬프)
- 처리 시간(Processing Time): 스트림 처리 엔진이 데이터를 처리하는 실제 시간.
- 데이터 스트림 환경에서는 네트워크 지연이나 시스템 병목으로 인해 이벤트 시간이 비정상적으로 늦게 도착하는 경우가 있습니다. 이를 지연 데이터(Late Data)라고 합니다.
워터마크(Watermark)는 이런 지연 데이터를 다루기 위해 특정 시점까지 기다렸다가 더 이상 이벤트가 도착하지 않는다고 가정하는 기준점입니다.
워터마크의 동작 방식
- 윈도우 연산 수행:
- 데이터를 특정 기간(예: 1분)으로 그룹화하여 집계.
- 예: 09:00:00 ~ 09:01:00까지의 데이터를 집계.
- 지연 허용 시간 설정:
- 워터마크는 지정된 허용 지연 시간 뒤에 도착하는 데이터는 무시하거나 별도로 처리합니다.
- 예: 지연 허용 시간 = 10초 → 09:01:10 이후 도착한 데이터는 늦은 데이터로 간주.
- 워터마크 생성:
- 스트림 처리 엔진이 워터마크를 주기적으로 생성.
- 워터마크는 데이터의 이벤트 시간 기준으로 현재까지의 처리 상태를 나타냄.
- 예: "현재 이벤트 시간은 09:01:05이며, 이 시점 이후에 도착한 데이터는 늦은 데이터로 처리."
- 윈도우 종료:
- 워터마크가 윈도우의 종료 시간을 초과하면 해당 윈도우의 데이터를 닫고 결과를 출력.
- 워터마크가 짧으면 데이터 정확도는 떨어지지만 시스템 응답 지연은 낮아진다. 워터마크를 사용하면 데이터의 정확도는 높아지지만 대기 시간이 늘어나 전반적인 지연 시간은 늘어난다.
집계 윈도
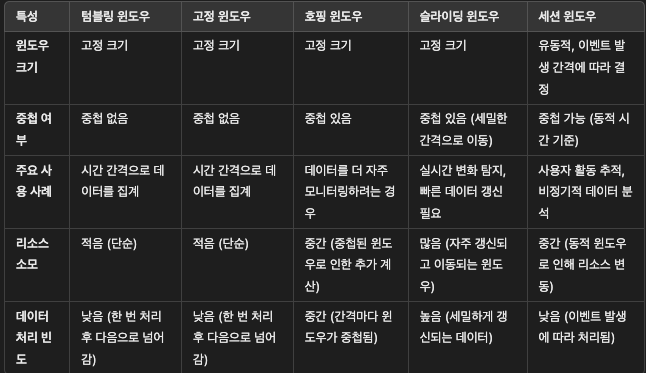
- 텀블링 윈도우: 데이터를 고정된 간격으로 집계하며 중복 데이터는 처리하지 않음. 단순하지만 중간 데이터 손실 가능.
- 고정 윈도우: 텀블링과 동일하지만 구현 방식에 따라 다르게 표현될 수 있음.
- 호핑 윈도우: 고정된 크기의 윈도우를 지정된 간격으로 중첩해 이동. 주기적인 데이터 분석에 적합.
- 슬라이딩 윈도우: 작은 간격으로 데이터를 집계해 연속적으로 처리. 실시간 분석에 적합하나 계산량이 많음.
- 세션 윈도우: 이벤트 간의 비활성 시간을 기준으로 유동적으로 윈도우 종료를 결정. 사용자 활동 및 비정기적 이벤트 추적에 유리.
전달 보장
- 카프카; 정확히 한 번
- 중복 집계 되지 않도록 오프셋 관리 철처하게
- 오프셋은 외부 파일 저장소에 기록
- 아래 4~6 단계의 작업을 하나의 분산 트랜젝션에 넣어야 한다.
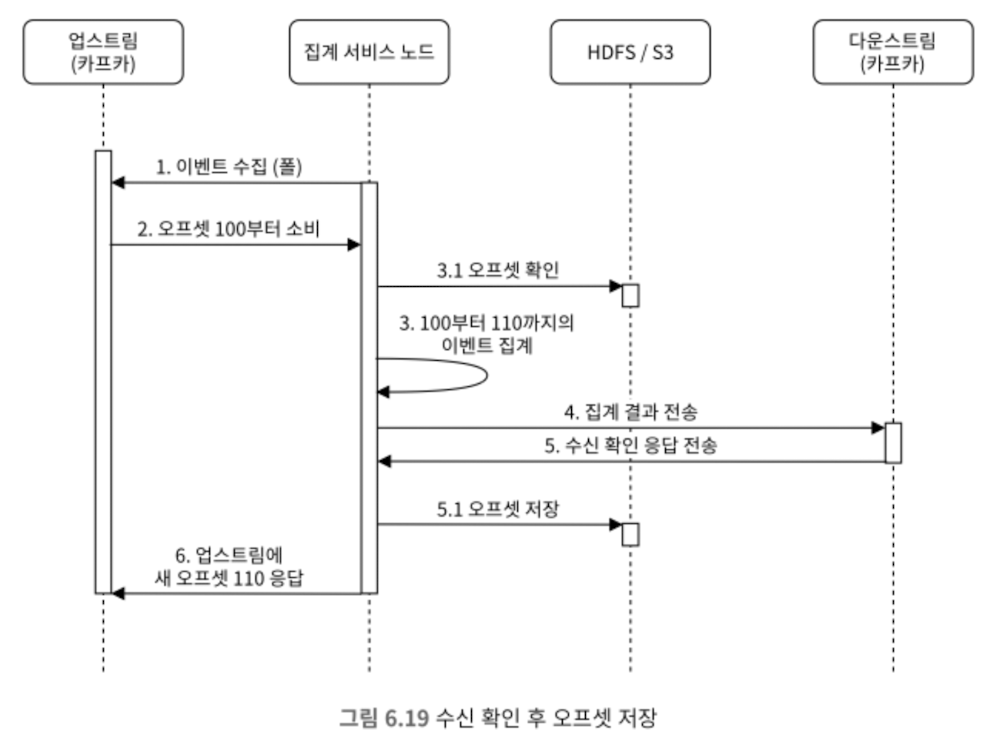
집계 서비스의 규모 확장/핫스팟 문제 시
보통 규모 확장을 위해 추가 서버 투입, 다중 프로세스, 다중 노드로 처리
집계 서비스의 fault tolerance를 위해
스냅 샷을 찍어서 그 후로 복구(집계 데이터 포함)
모니터링
- 지연 시간: 각 단계마다 timestamp 추적이 가능하도록
- 메세지 큐 크기: 카프카의 record lag 등으로 집계 서비스 노드 추가 투입 판단
- 시스템 자원: cpu, jvm, 디스크
- 조정: 배치 결과랑 실시간 결과랑 비교해서 데이터 무결성 검증

728x90
반응형